About
* Silence makes big money.
* Wondering about my destiny.
* Maybe spending your life as you wish is success.
* A distant dreamer.
* My coworkers see me coding.
* 📷 Photos

About Me
一名热衷于图像超分辨率、去噪、增强等方向的工程实践者(学生 硕3 硕4)。因为平时的工作和研究内容,也持续接触目标检测、实例分割、Transformer 系列模型,以及模型部署和推理落地相关的问题。
这个站点主要用来整理几类内容:
- Tech Notes(技术笔记):技术内容的主分区
- Guides(技术分享):相对完整的技术文章、实验总结和实现复盘
- Thoughts(技术杂谈):短结论、坑点和暂时不扩写的技术片段
- Mabinogi:游戏相关的日常记录和 Mabinogi Lounge 内容
- Maintenance(维护):站点迁移、结构调整和长期维护记录
这里不是传统简历页,而是一个长期维护的文档式个人主页。
- 图像处理相关算法与实验
- 模型部署和推理落地
- 工程实践中的整理与记录
- GitHub: https://github.com/PC-Gao
Guides(技术分享)
这里收纳相对完整的技术记录、实验总结和实现复盘。
- AI Studio
- CR/DR 牙齿分割阶段记录
- PPOCRv5-ncnn 移动端速度测试
- DeamNet ncnn Windows
- Raw Image Process
- DruNet ncnn Windows
- Low Light Image Enhancement
AI Studio
Updated: 2026-04-13(更新日期)
A modern algorithm visualization and inference desktop application built with vue3 and pywebview.
Feature Overview(功能介绍)
Updated: 2026-04-13(更新日期)
AI Studio
- 闲暇之余,写了一个算法测试工具,也当作自己的项目集用,在此记录下,主要使用
pywebview、Vue 3、FastAPI、ONNX构建,后续有空会继续加入NCNN等推理框架。
页面总览
| 页面 | 路由 | 主要用途 |
|---|---|---|
| 首页 | / | 展示算法入口与模型总览 |
| 检测页 | /detection | 目标检测、批量检测、视频检测 |
| 分割页 | /segmentation | 图像分割、批量分割、模型预加载 |
| 分类页 | /classification | 图像分类、批量分类 |
| 图像修复页 | /restoration | 单图修复、批量修复、修复模型配置 |
| 姿态估计页 | /pose | 人体或目标关键点姿态估计 |
| OBB 页 | /obb | 旋转框目标检测 |
| 设置页 | /settings | 外观、默认设备、API 地址等全局配置 |
| 关于页 | /about | 项目简介、功能特性、技术栈和系统信息 |
1. 首页
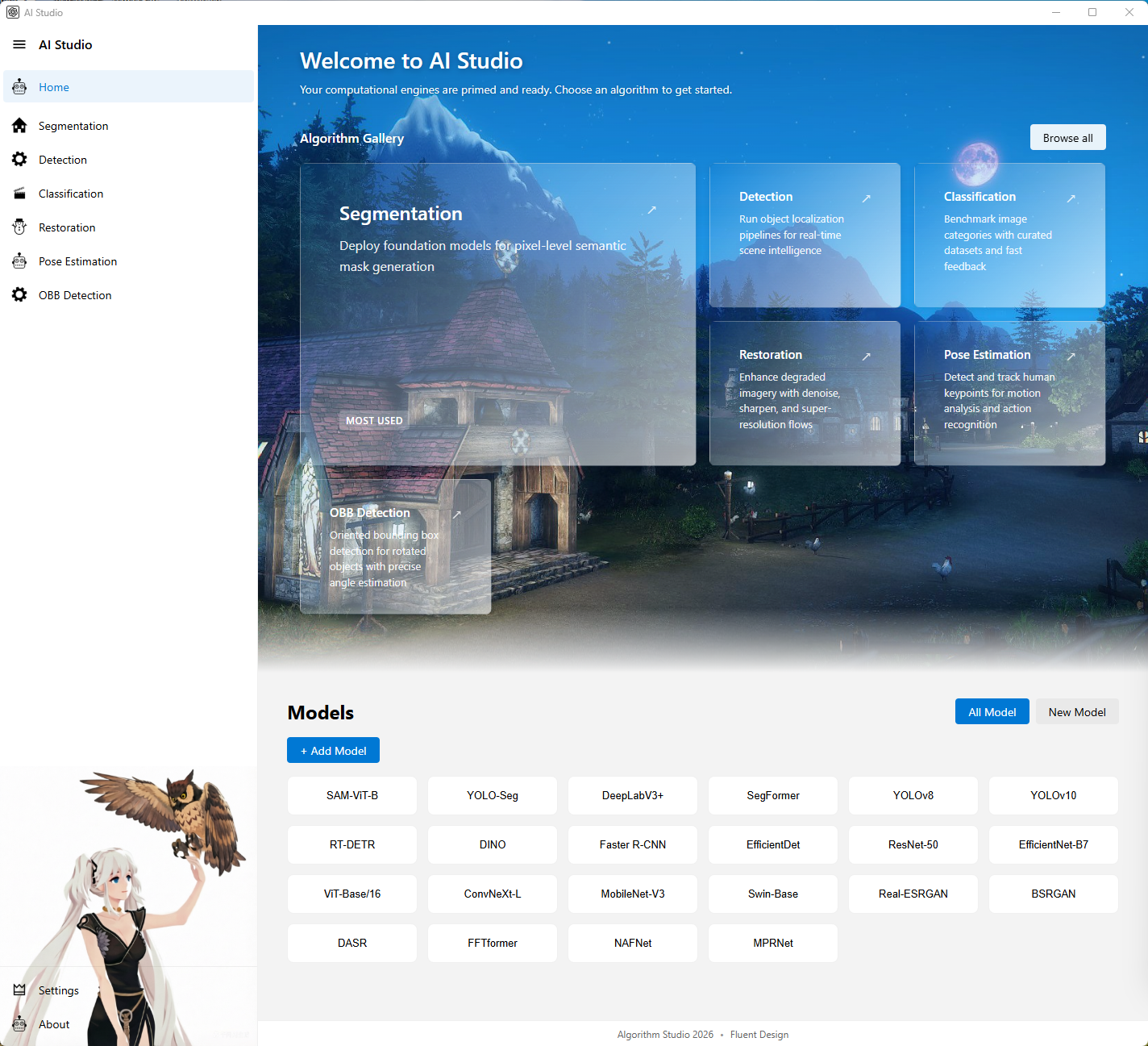
图注:首页展示算法入口、模型总览和最近模型记录,是系统的总导航页。
页面定位
首页是整个系统的总入口,用于帮助用户快速进入不同算法页面,并查看当前系统中已经维护的模型信息。
主要功能
- 展示
Algorithm Gallery,以卡片形式展示各算法方向 - 提供高亮的主推算法入口
- 展示模型总表和新模型列表
- 支持新增和删除首页展示的模型记录
- 支持从模型列表直接跳转到对应算法页面
阅读重点
- 适合在文档开头作为项目总览页展示
- 既能体现产品支持的算法范围,也能体现模型管理能力
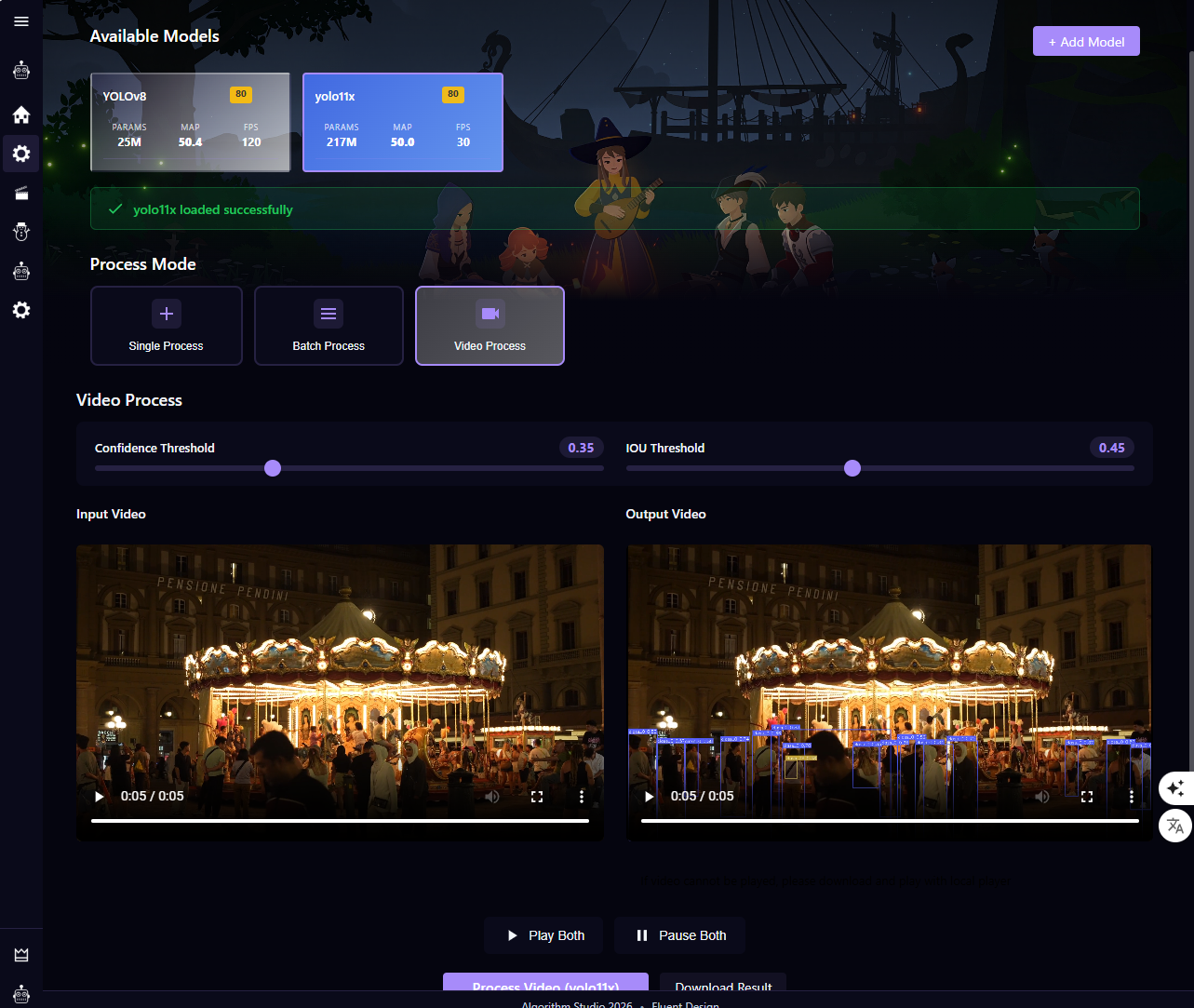
2. 检测页
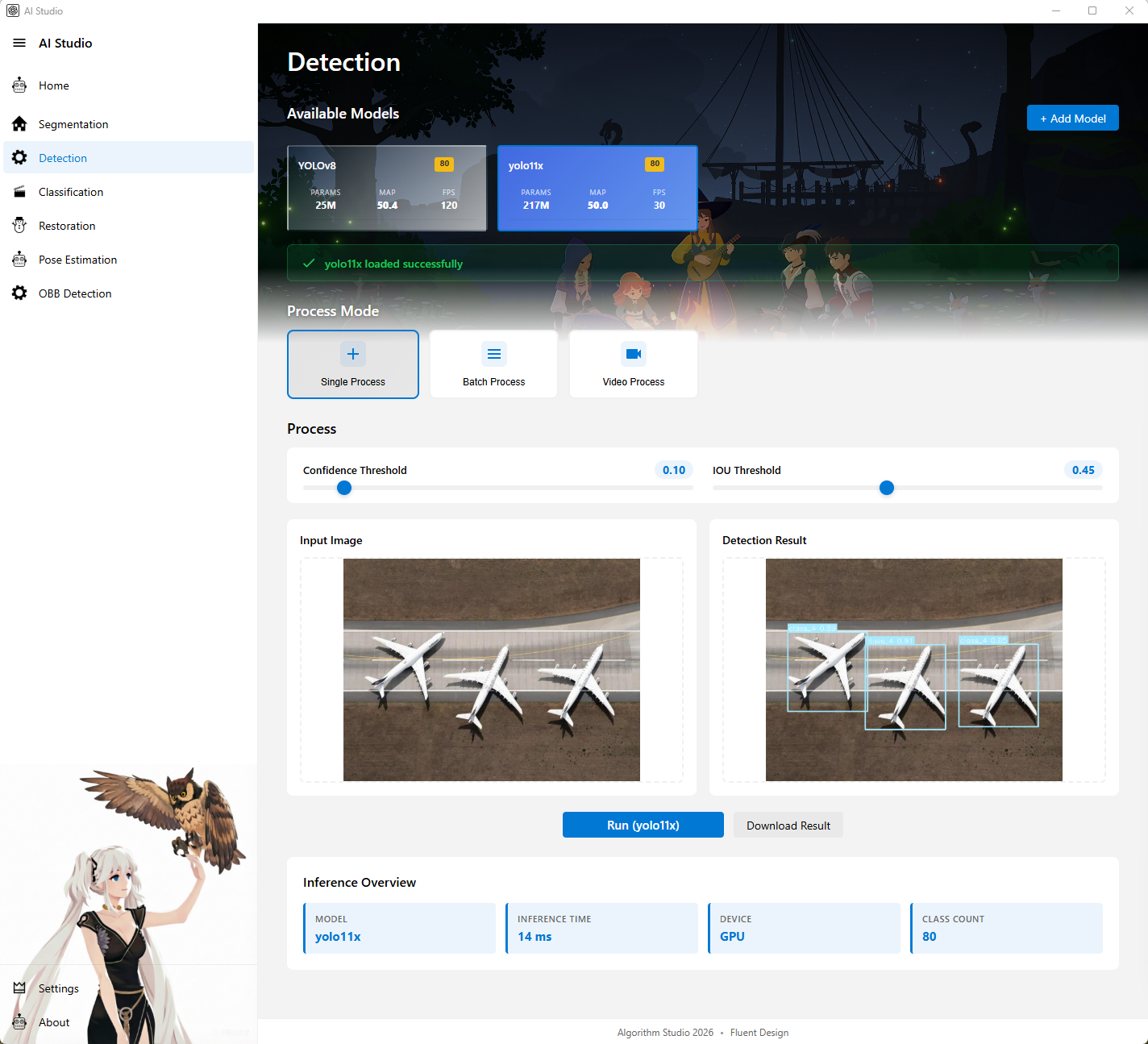
图注:检测页亮色主题,展示模型选择、单图检测、批量检测和推理结果区域。
图注:检测页暗色主题,便于展示系统在不同主题下的界面一致性。
页面定位
检测页用于执行目标检测任务,是当前功能最完整的页面之一。
主要功能
- 展示可用检测模型
- 点击模型卡片后预加载模型权重
- 支持单图检测
- 支持批量图像检测
- 支持视频检测
- 支持新增自定义检测模型
- 支持调整检测参数,例如置信度阈值和 IOU 阈值
- 展示推理结果图、推理时间、设备信息等推理摘要
3. 分割页
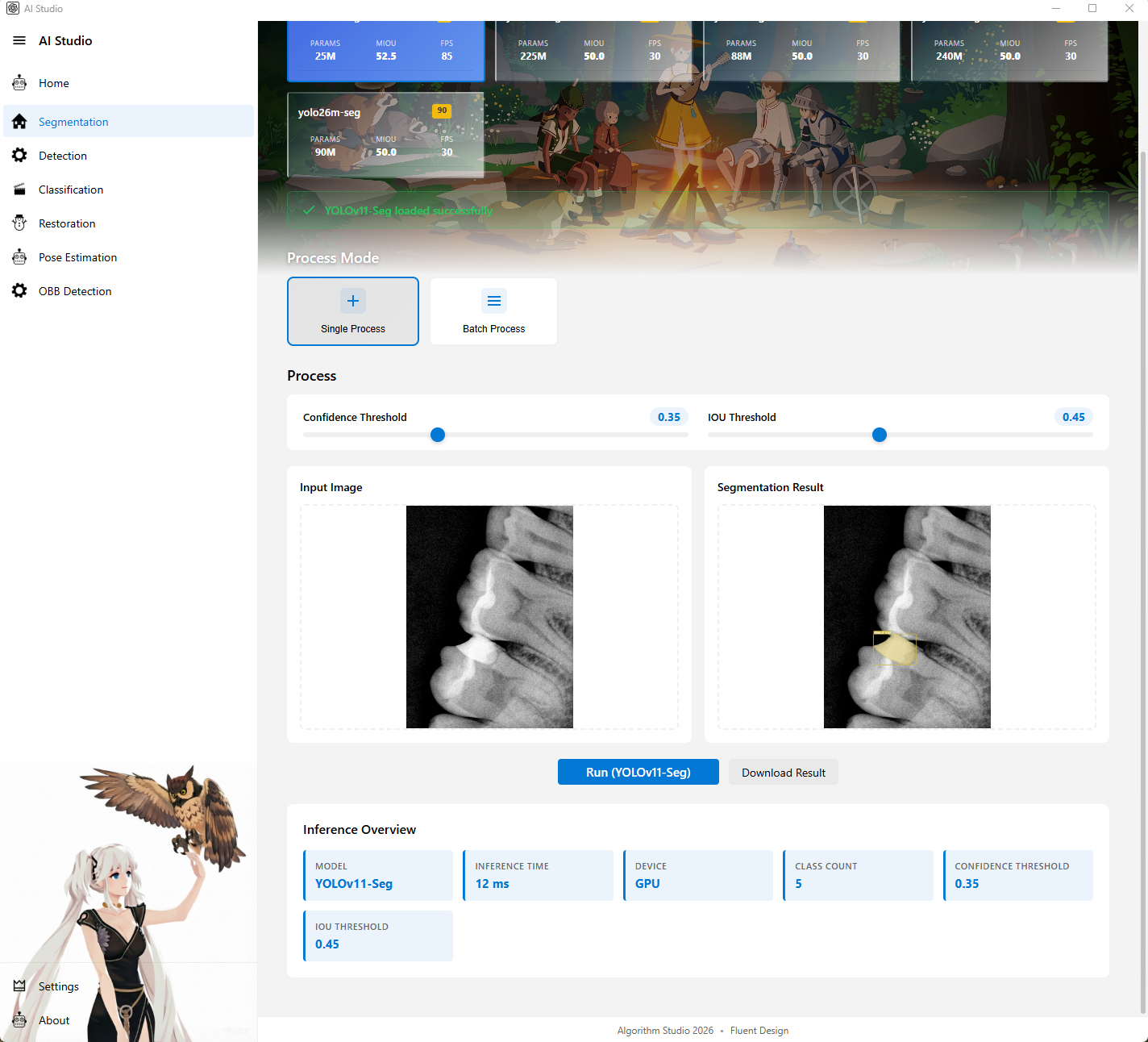
图注:分割页主界面,展示模型选择、分割参数、输入输出和推理信息。
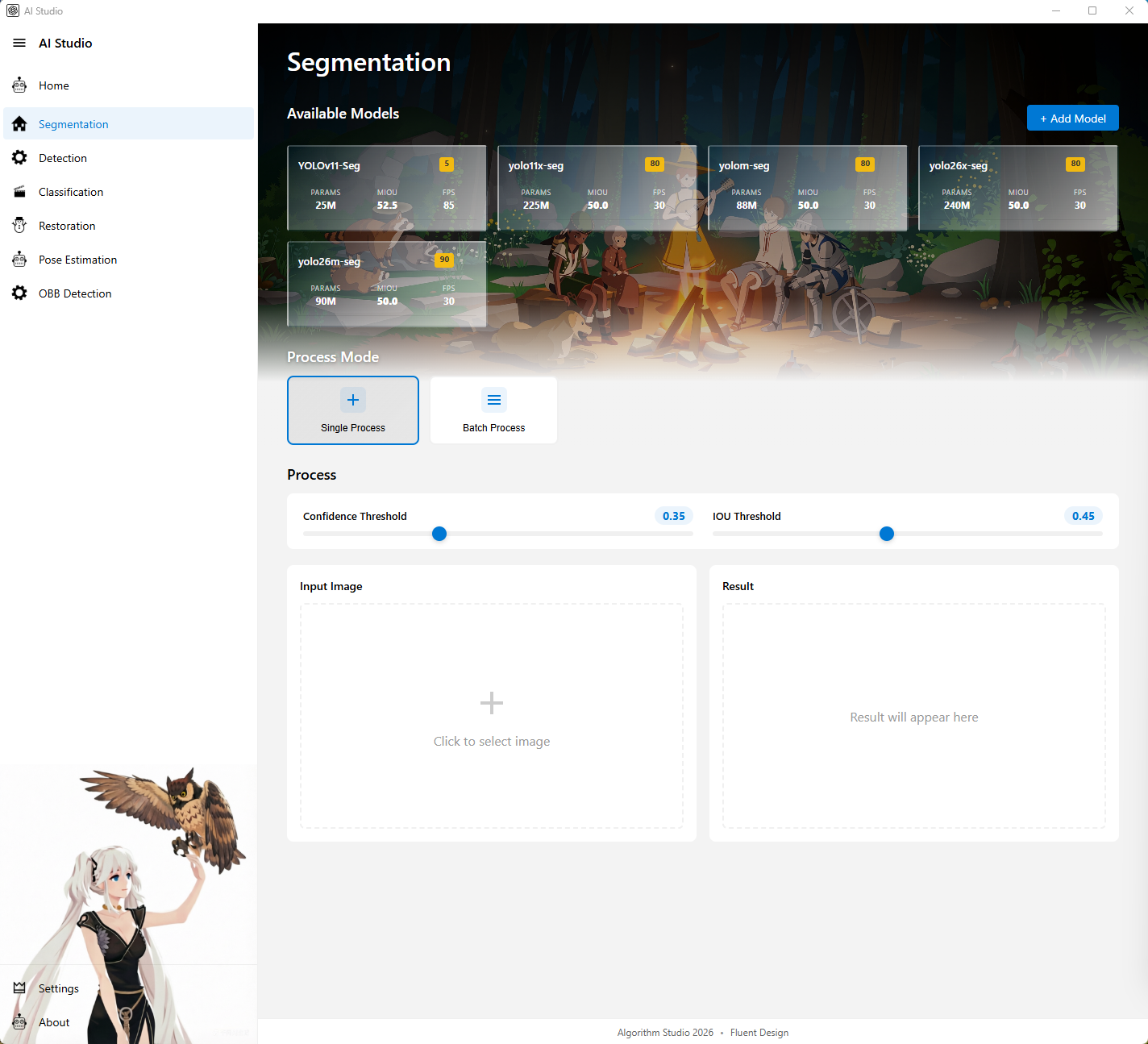
图注:分割页补充截图,可用于展示模型状态提示或结果展示细节。
页面定位
分割页用于执行实例分割或语义分割任务,目前支持 YOLO Seg 和 Mask2Former 等分割模型链路。
主要功能
- 展示可用分割模型
- 点击模型卡片时预加载模型
- 支持单图分割
- 支持批量分割
- 支持新增和维护分割模型
- 支持按模型架构区分推理路径
- 展示模型加载状态、推理结果和推理信息
4. 分类页
页面定位
分类页用于执行图像分类任务,适合展示单标签或多类别概率输出。
主要功能
- 展示可用分类模型
- 点击模型卡片时预加载模型
- 支持单图分类
- 支持批量分类
- 支持新增分类模型
- 展示分类结果与概率信息
- 展示推理时间和运行设备
5. 图像修复页
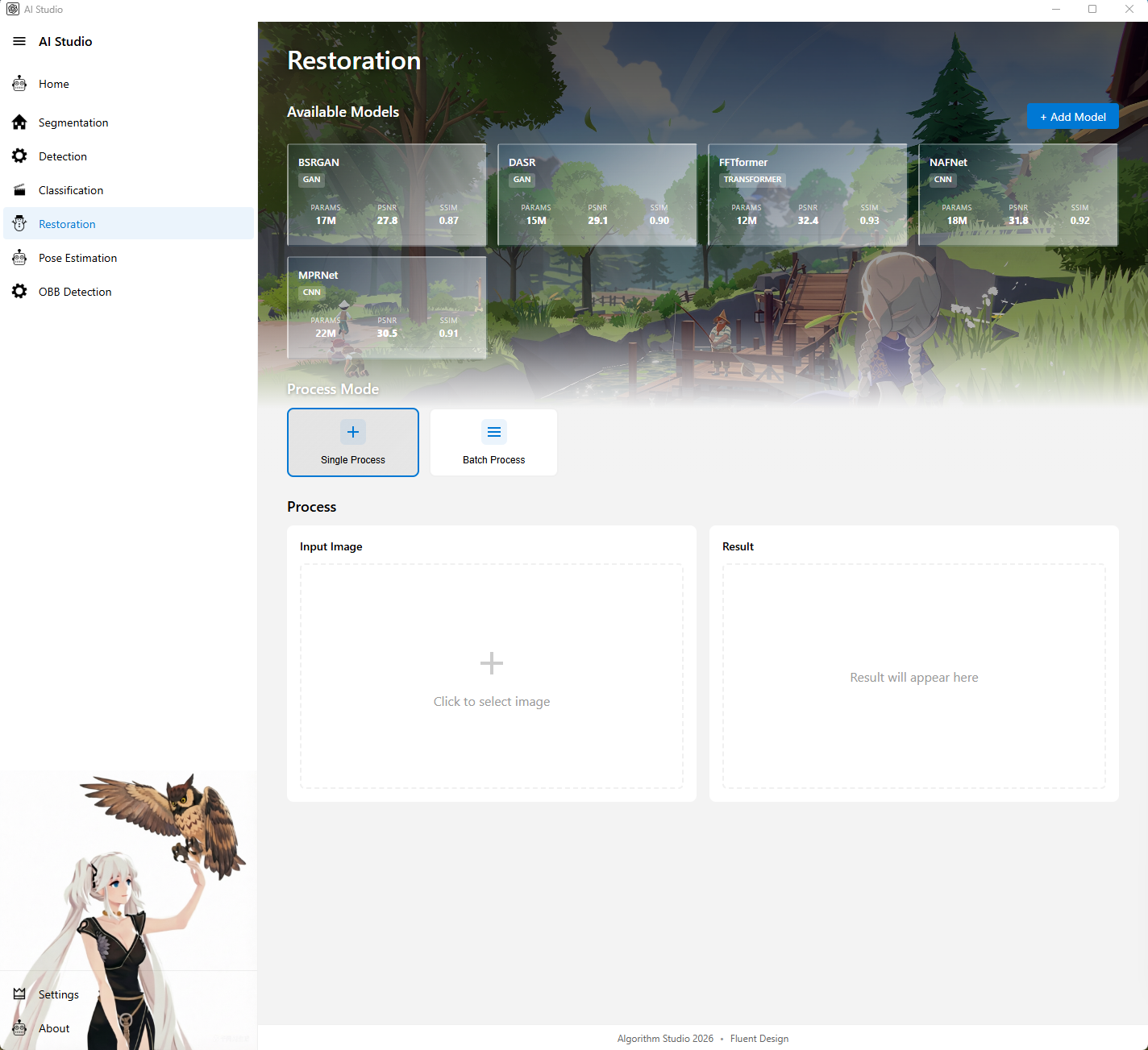
图注:图像修复页展示模型选择、修复前后结果对比,以及修复模型配置入口。
页面定位
图像修复页用于执行图像增强、去噪、去模糊、超分辨率等图像到图像任务。
主要功能
- 展示可用修复模型
- 点击模型卡片后预加载修复模型
- 支持单图修复
- 支持批量修复
- 支持新增修复模型
- 新增模型时支持配置:
Model PathInput SizePadding Size
- 展示修复前后图像对比和推理信息
- 当前修复链路支持在推理前按配置做 padding,推理后裁切,并恢复到原图尺寸
6. 姿态估计页
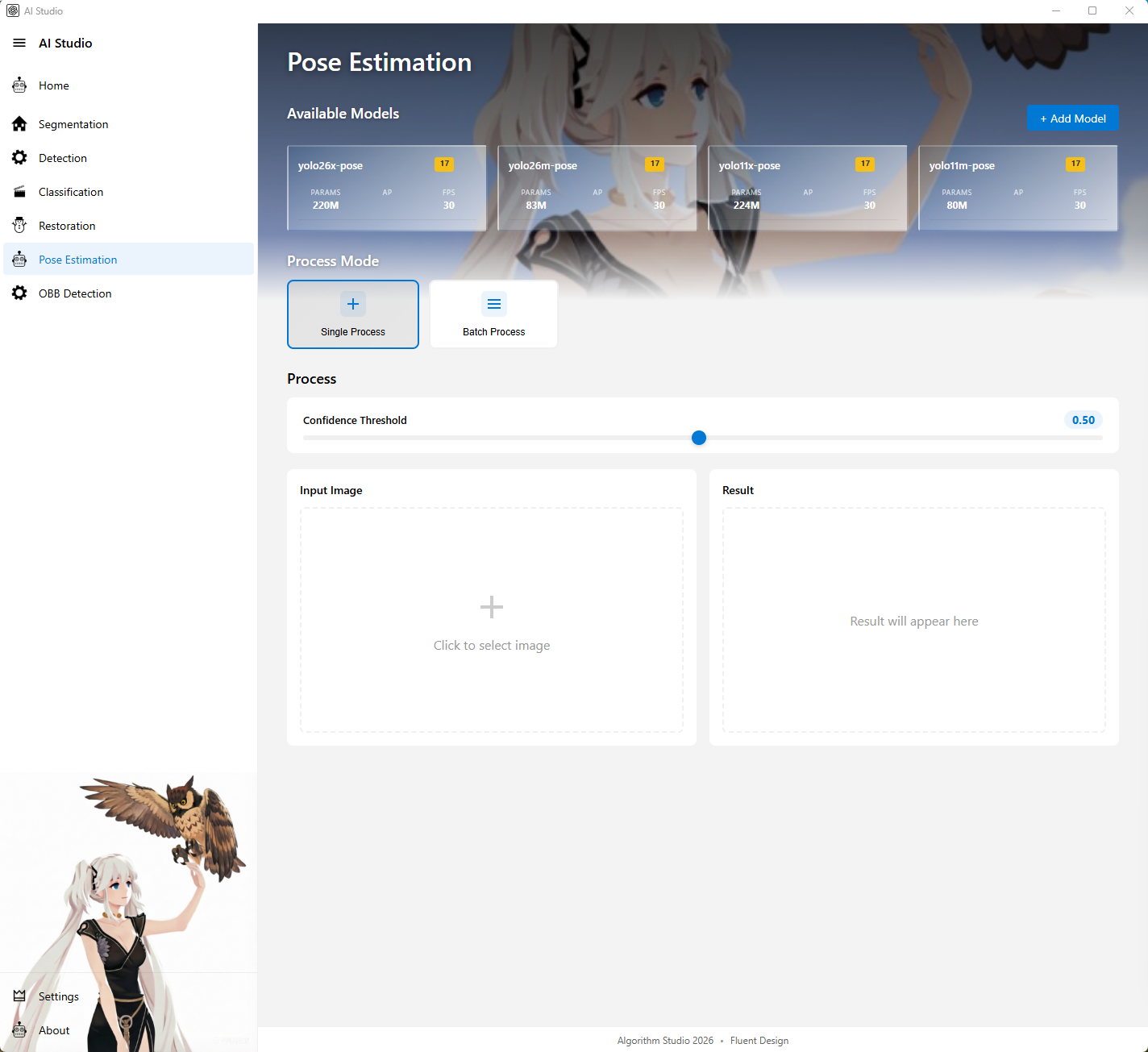
图注:姿态估计页展示关键点模型选择、输入输出区域和推理结果摘要。
页面定位
姿态估计页用于关键点检测和姿态可视化任务。
主要功能
- 展示可用姿态估计模型
- 点击模型卡片后预加载模型
- 支持单图姿态估计
- 支持批量姿态估计
- 支持新增和编辑模型
- 展示推理时间、设备、关节点数量等信息
- 展示模型加载状态提示
7. OBB 页面
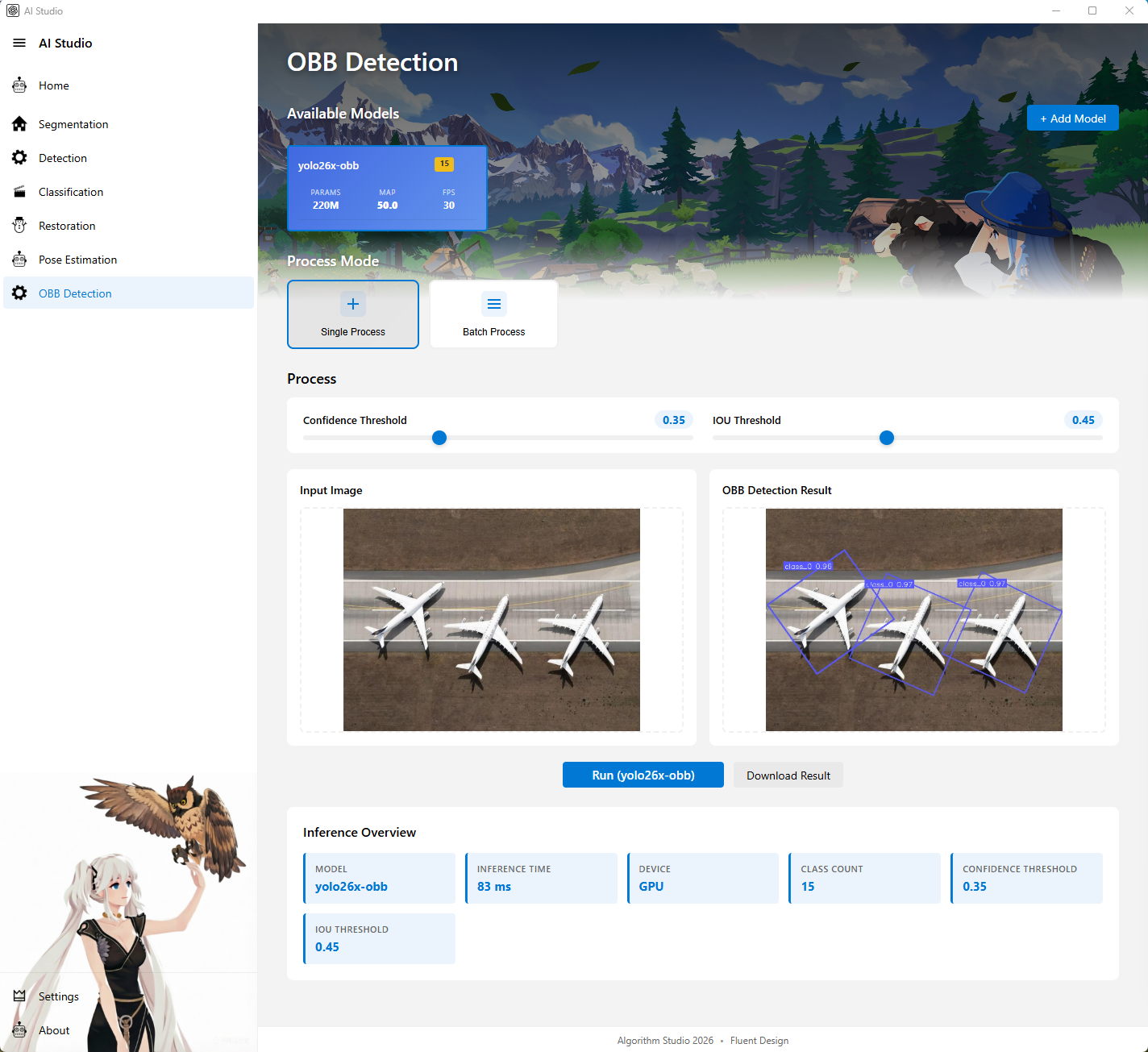
图注:OBB 页面展示旋转框检测结果,适合工业检测和方向敏感场景。
页面定位
OBB 页面用于旋转框目标检测,适合工业检测、遥感检测等需要角度信息的场景。
主要功能
- 展示可用 OBB 模型
- 点击模型卡片后预加载模型
- 支持单图 OBB 检测
- 支持批量 OBB 检测
- 支持新增 OBB 模型
- 支持调整置信度和 IOU 阈值
- 展示推理结果、类别数量、设备和推理时间
- 展示模型加载状态提示
8. 设置页
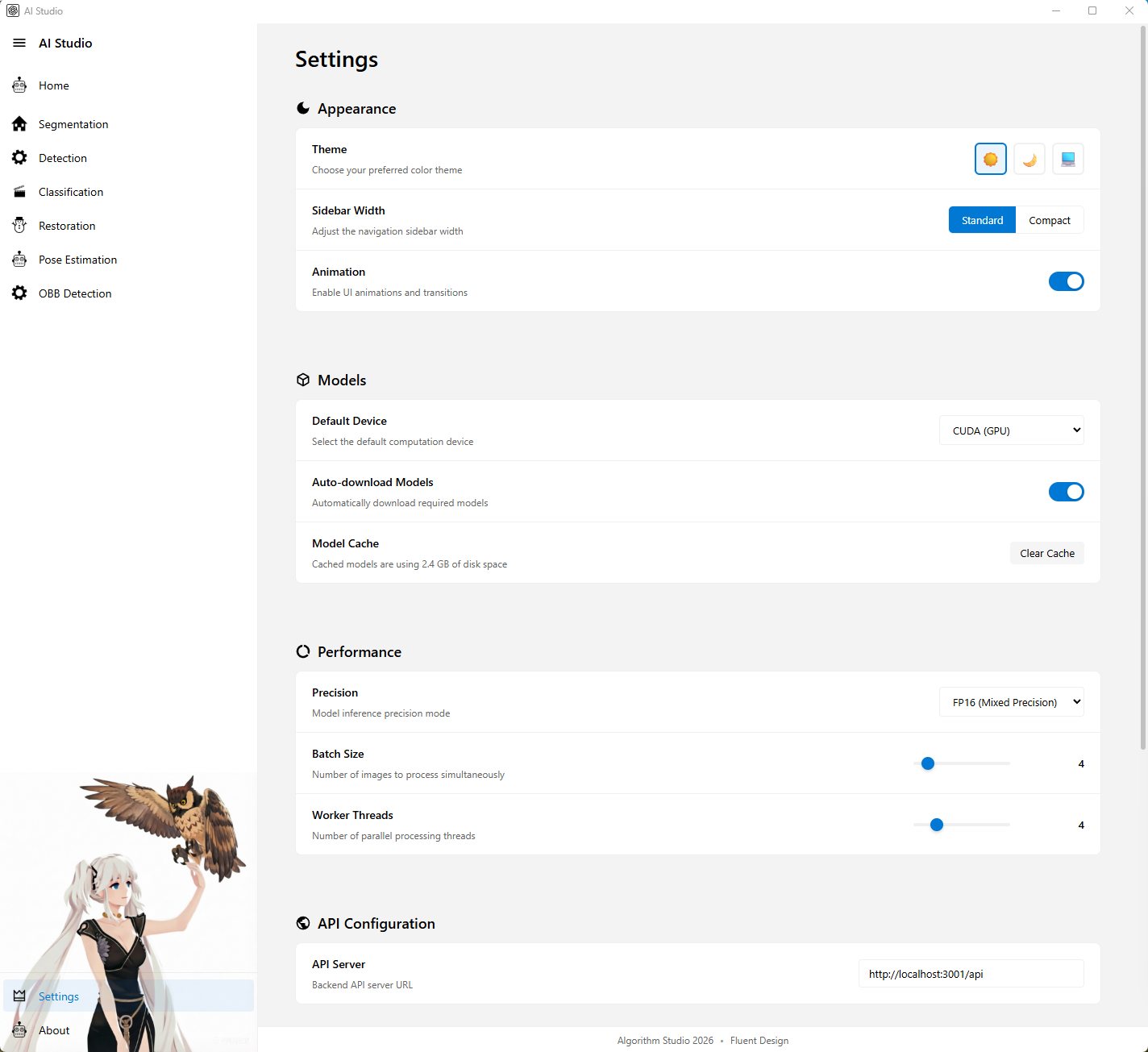
图注:设置页亮色主题,展示外观、模型、性能和 API 配置。
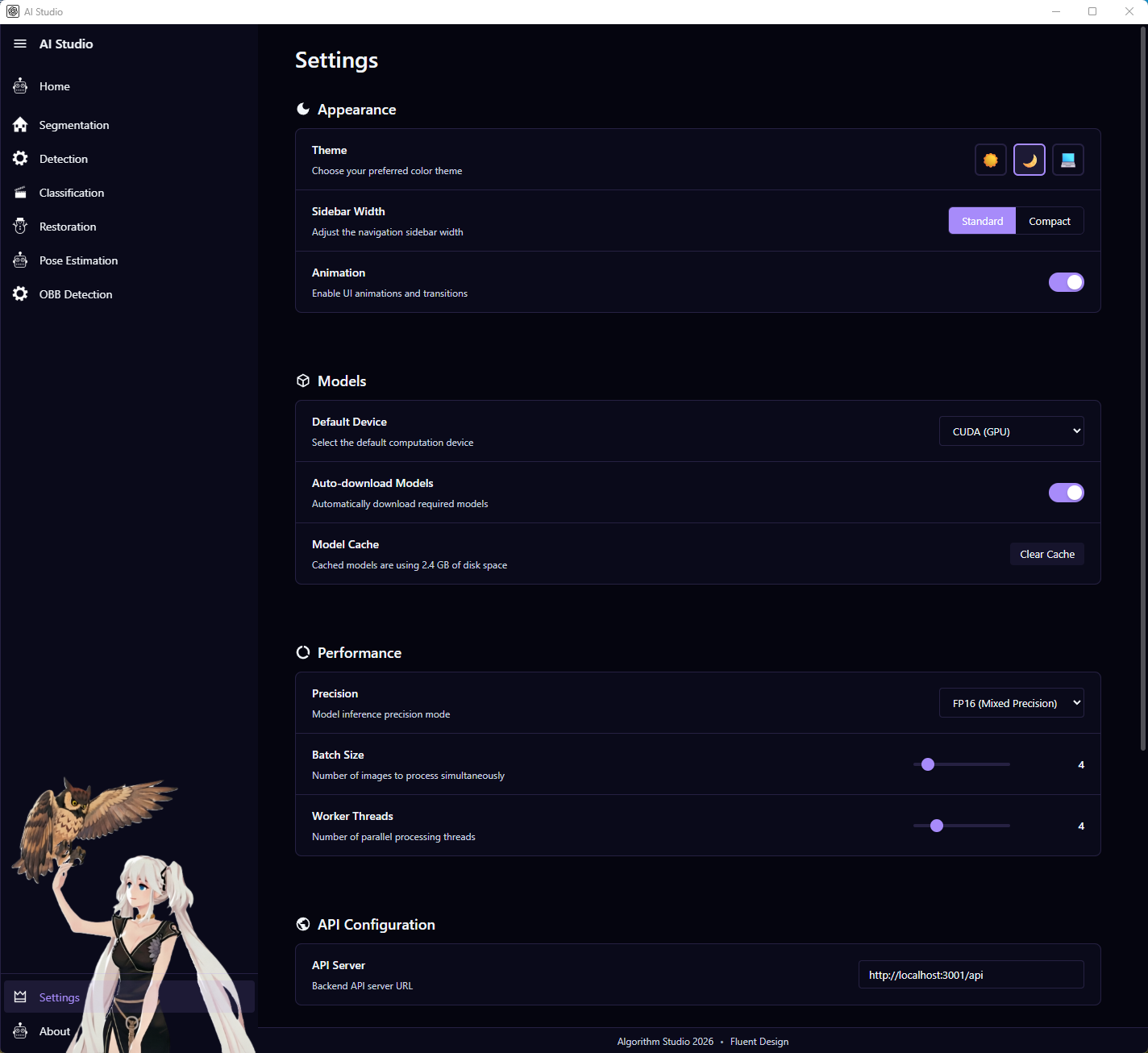
图注:设置页夜间主题,用于展示系统在不同主题下的设置界面效果。
页面定位
设置页用于管理系统级配置,是前端和推理默认行为的集中配置入口。
主要功能
- 管理外观设置
- 主题
- 侧边栏宽度
- 动画开关
- 管理模型相关设置
- 默认设备
- 自动下载模型
- 模型缓存显示
- 管理性能设置
- 精度
- 批大小
- 工作线程
- 管理 API 地址
- 支持一键重置全部设置
9. 关于页
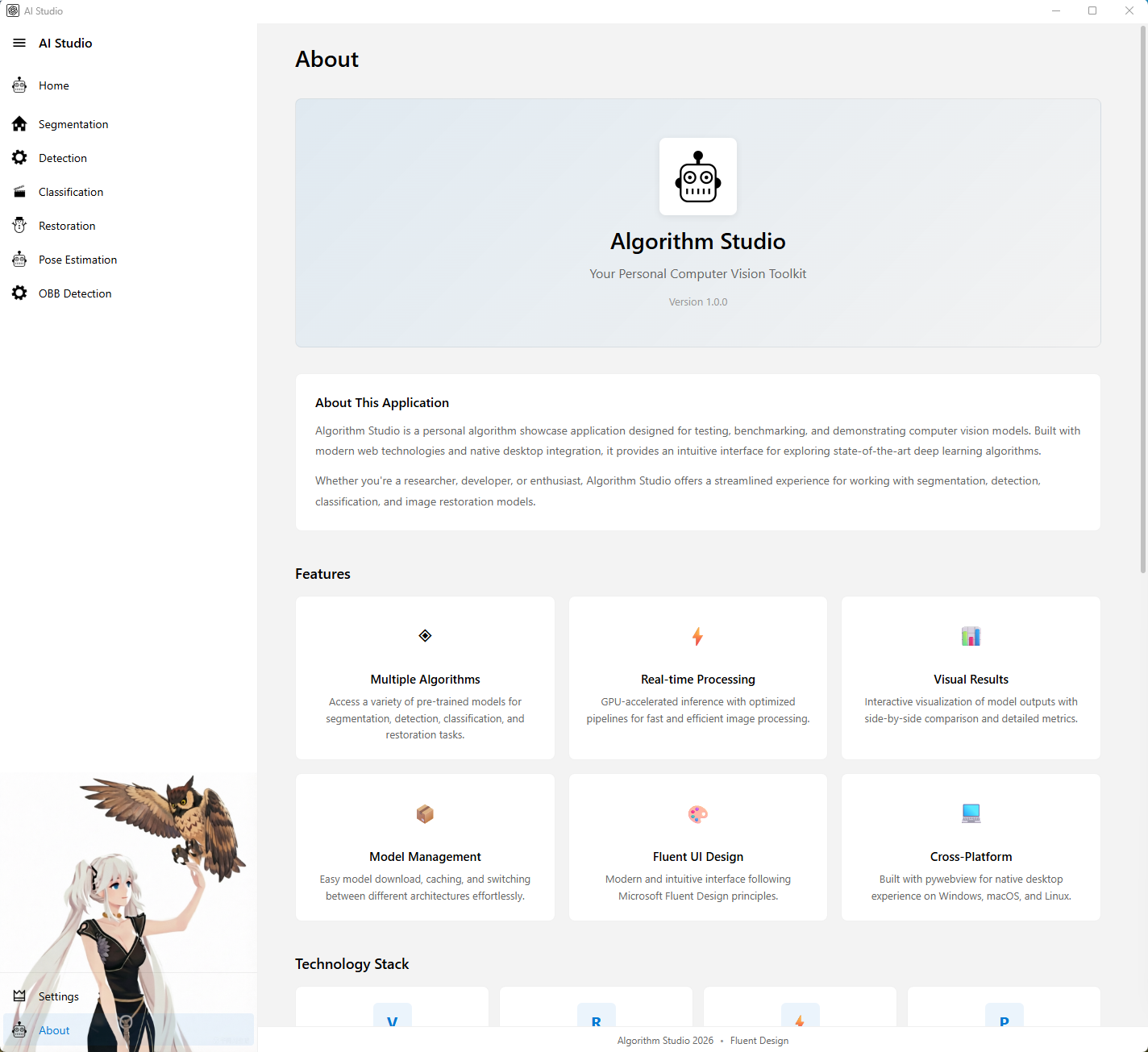
图注:关于页展示项目简介、核心特性、技术栈和系统信息。
页面定位
关于页用于介绍项目背景、功能范围和技术实现,是文档性最强的一个页面。
主要功能
- 展示应用名称、版本和简介
- 展示系统支持的主要功能
- 展示技术栈
- 展示开源项目致谢
- 展示系统信息
- 提供检查更新、文档和问题反馈入口
Software Architecture(软件架构)
Updated: 2026-04-13(更新日期)
项目架构总览
更新时间:2026-04-12
适用读者:新接手开发者、项目维护者、需要快速理解系统结构的人
1. 项目定位
该项目是一个本地运行的 AI 视觉推理工作台,支持:
- 模型管理
- 图片上传
- 单图推理
- 批量推理
- 视频推理
- 推理结果展示
- 多任务页面切换
从形态上看,它不是单纯的 Web 应用,而是:
桌面壳 + Vue 前端 + FastAPI 后端 + SQLite 元数据 + ONNX Runtime 推理层
的组合系统。
2. 全局架构图
flowchart LR
A[main.py / pywebview] --> B[Vue App]
B --> C[页面层 frontend/src/pages]
C --> D[API 封装 frontend/src/api.js]
D --> E[FastAPI backend/app.py]
E --> F[路由层 backend/routes]
F --> G[数据库层 backend/database.py + SQLite]
F --> H[推理层 backend/model]
H --> I[ONNX Runtime / 模型文件]
F --> J[文件系统 uploads outputs labels]
这张图的重点是:
main.py只是宿主,不是业务核心- 真正的业务主线是:页面 -> API -> 路由 -> 数据/推理
- 数据库存的是元数据,文件系统存的是实体资源,推理层执行真实模型
3. 顶层目录结构
demo040501/
├─ main.py
├─ frontend/
├─ backend/
├─ labels/
├─ models/
├─ outputs/
└─ backend/model/
重点目录说明
frontend/
前端目录。包含源码、静态资源、Vite 配置、npm 依赖声明和构建产物。
frontend/src/
前端源码目录。负责界面、交互、状态和 API 调用。
backend/
后端服务目录。负责数据库、上传、推理、结果输出。
backend/model/
后端推理模块目录。负责预处理、ONNX Session 执行、后处理和可视化绘制。
backend/uploads/
上传文件目录。图片和视频先上传到这里,再以 imageId/videoId 形式参与推理。
backend/outputs/
推理结果输出目录。结果图和结果视频由后端生成,前端直接通过静态路径访问。
labels/
标签输出目录,用于保存检测/分割等结构化结果。
4. 分层结构说明
项目可以分成五层:
- 桌面宿主层
- 前端展示与交互层
- 前端 API 适配层
- 后端路由与业务编排层
- 数据与推理执行层
5. 桌面宿主层
核心文件:
main.py
作用
- 检查前端构建产物是否存在
- 如果存在,加载
frontend/dist/index.html - 如果不存在,回退到开发模式地址
- 使用
pywebview创建桌面窗口
为什么这一层重要
它决定了产品最终是“桌面软件”而不是“浏览器页面”,但它不参与推理、模型管理和数据库逻辑。
这一层的设计重点
- 低耦合
- 尽量不侵入业务逻辑
- 只做应用宿主和窗口承载
换句话说:
main.py是外壳,不是核心。
6. 前端展示与交互层
前端采用:
- Vue 3
- Vue Router
- Vite
核心入口:
src/main.jssrc/App.vue
6.1 根应用结构
App.vue 的整体布局是:
- 左侧
Sidebar - 中间主内容区
- 内容区内部按路由切换页面
- 底部
Footer
这是一种典型的:
全局壳层 + 页面内容区
架构。
6.2 路由层
核心文件:
src/router/index.js
当前主要页面路由:
- Home
- Segmentation
- Detection
- Classification
- Restoration
- Pose
- OBB
- Settings
- About
路由层的重点
- 路由只负责页面映射
- 不承载业务逻辑
- 页面逻辑主要放在各自
.vue文件中
7. 前端重点模块
7.1 页面层 frontend/src/pages
这是前端最重要的一层。每个页面本质上都是一个任务控制器。
核心页面:
src/pages/DetectionPage.vuesrc/pages/SegmentationPage.vuesrc/pages/ClassificationPage.vuesrc/pages/PoseEstimationPage.vuesrc/pages/OBBDetectionPage.vuesrc/pages/RestorationPage.vuesrc/pages/SettingsPage.vue
页面层负责什么
通常一个任务页会负责:
- 加载当前任务的模型列表
- 展示
Available Models - 管理模型选择和取消选择
- 触发预加载与卸载
- 上传图片或视频
- 设置推理参数
- 发起推理请求
- 渲染结果图、耗时、设备信息
页面层的设计特点
- 业务逻辑集中
- 状态基本就地维护
- 开发效率高
页面层的代价
- 页面文件较长
- 公共逻辑重复较多
这也是当前项目后续最值得继续抽象的地方。
7.2 通用组件层 frontend/src/components
重要组件:
- src/components/Sidebar.vue
Footer.vue
Sidebar.vue
职责:
- 根据导航常量渲染菜单
- 区分顶部、滚动区、底部导航
- 发出导航事件
- 支持紧凑/展开两种模式
重点:
- 它只做导航展示
- 不直接处理推理、模型、数据库
这是一个标准的“无业务组件”。
7.3 设置状态层 frontend/src/composables/useSettings.js
核心文件:
作用
- 提供全局设置状态
- 从
localStorage读取设置 - 自动保存设置
- 应用主题
当前设置项
themesidebarCompactanimationsdefaultDeviceautoDownloadprecisionbatchSizeworkerThreadsapiBase
模块重点
这不是完整状态管理框架,而是一个轻量级全局配置中心。
它解决的是:
- 全局设置共享
- 持久化
- 主题应用
而不是复杂业务状态同步。
7.4 API 适配层 frontend/src/api.js
核心文件:
作用
- 统一封装
fetch - 动态读取
settings.apiBase - 按领域组织 API 方法
主要 API 分组:
algorithmsallModelsnewModelscategoryModelsimagesinferenceexports
模块重点
它是前端和后端之间的边界层。
好处:
- 页面组件不用关心具体 URL 拼接
- 后端 API 调整时只需集中修改
8. 后端架构
后端采用 FastAPI。
核心入口:
后端主要职责
- 提供 REST API
- 管理模型元数据
- 接收上传图片和视频
- 调度推理
- 输出结果文件
- 提供导出接口
9. 后端重点模块
9.1 应用入口 backend/app.py
职责:
- 创建 FastAPI 实例
- 配置 CORS
- 初始化数据库
- 注册路由
- 挂载静态目录
挂载静态目录:
/uploads/outputs/labels
为什么重要
它把“API 服务”和“结果资源访问”放进了同一个服务里,前端因此可以直接显示输出图片和结果视频。
9.2 路由聚合层 backend/routes/__init__.py
职责:
- 集中导出路由
- 由
app.py统一注册
当前路由模块:
- backend/routes/algorithms.py
- backend/routes/models.py
- backend/routes/images.py
- backend/routes/inference.py
- backend/routes/exports.py
这是典型的“按业务领域拆分路由”设计。
9.3 算法管理模块 algorithms.py
职责:
- 维护任务分类
- 提供算法列表给前端
它管理的是:
- detection
- segmentation
- classification
- restoration
重点:
这层提供的是“任务分类元数据”,不是推理逻辑。
9.4 模型管理模块 models.py
职责:
- 维护全量模型目录
- 维护新模型目录
- 维护按任务分类的模型元数据
最关键的数据表是:
category_models
为什么 category_models 是核心
前端页面展示的 Available Models,以及后端推理时读取的:
- 模型名称
- 模型路径
- 输入尺寸
- 类别数
- 性能指标
基本都来自这张表。
这意味着:
当前项目不是“自动扫描模型目录”型系统,而是“数据库驱动的模型配置系统”。
9.5 上传模块 images.py
职责:
- 接收上传文件
- 生成唯一文件名
- 写入
uploads - 记录到数据库
重点
项目采用两阶段推理模式:
- 先上传文件
- 再根据
imageId/videoId发起推理
这种方式比“推理接口里直接传原文件”更适合:
- 页面回显
- 批处理
- 结果追踪
9.6 推理编排模块 inference.py
这是后端最核心的模块。
职责:
- 接收推理请求
- 查询图片记录
- 查询模型元数据
- 根据任务创建或复用预测器
- 进行预加载、预热、推理、卸载
- 记录结果
当前承担的关键能力
- 设备标准化
- 模型缓存
- 预热 warm-up
- 任务分流
- 单图推理
- 视频推理
- 卸载释放
为什么它是系统核心
因为它连接了三端:
- 前端请求
- 数据库元数据
- 模型执行层
如果把项目比作生产线,inference.py 就是调度中心。
9.7 导出模块 exports.py
职责:
- 根据结果 ID 返回导出信息
当前状态:
- 更接近占位接口
- 已有结构,但不是项目复杂核心
10. 数据层
核心文件:
10.1 作用
- 提供 SQLite 连接
- 初始化数据库表
- 写入种子数据
10.2 为什么选 SQLite
对于本地桌面型工具,SQLite 的优点很明确:
- 部署简单
- 无需额外数据库服务
- 适合中小规模元数据管理
10.3 核心数据表
algorithms
- 保存任务分类
all_models
- 保存所有模型的总目录信息
new_models
- 保存首页或推荐区模型
category_models
- 保存任务页面真实使用的模型元数据
images
- 保存上传文件记录
inference_results
- 保存推理输出结果记录
数据层重点
数据库存的是:
- 元数据
- 路径
- 状态
真正的二进制文件在文件系统中:
- 上传文件在
uploads - 输出文件在
outputs - 标签文件在
labels
11. 推理执行层 backend/model
这是“真正跑模型”的地方。
重要模块:
- backend/model/yolo_detection.py
- backend/model/yolo_classification.py
- backend/model/yolo_seg.py
- backend/model/yolo_pose.py
- backend/model/yolo_obb.py
- backend/model/video_detection.py
- backend/model/xxxx_seg.py
11.1 推理器的通用结构
这些推理器普遍遵循同一套路:
- 读取 ONNX 模型
- 根据设备创建 Session
- 解析输入尺寸
- 预处理输入图像
- 执行 ONNX 推理
- 后处理输出
- 绘制结果
- 返回结果和耗时
这一层的重点
- 它不关心页面
- 不关心数据库
- 只关心“如何把输入变成结果”
这是一层纯执行逻辑。
11.2 各推理模块的重点
yolo_detection.py
负责:
- 普通目标检测
- 兼容
yolo11和yolo26 - 解析框、得分、类别
重点:
- 已支持 raw-head 与 end-to-end 两种输出格式
yolo_seg.py
负责:
- 实例分割
- mask 解码
- 掩码绘制
重点:
- 后处理复杂度高于普通检测
yolo_classification.py
负责:
- 分类推理
- top-k 结果计算
重点:
- 结构相对最简单
yolo_pose.py
负责:
- 姿态框和关键点解析
- 骨架绘制
重点:
- 依赖
num_joints
yolo_obb.py
负责:
- 旋转框解析
xywhr转 polygon
重点:
- 比普通检测多一个角度维度
video_detection.py
负责:
- 逐帧读取视频
- 调用图像预测器
- 重编码输出视频
重点:
- 视频推理本质上是对图像推理器的逐帧复用
xxxx_seg.py
负责:
- 提供
xxxx分割推理示例 - 作为后续接入非 YOLO 分割模型的参考实现
重点:
- 当前还是独立示例脚本
- 还没有接入
backend/routes/inference.py的统一分流
12. 关键调用链
12.1 单图推理链路
sequenceDiagram
participant U as 用户
participant P as 页面组件
participant A as frontend/src/api.js
participant R as backend/routes/inference.py
participant D as SQLite
participant M as backend/model/*
U->>P: 选择模型并点击 Run
P->>A: api.inference.run(...)
A->>R: POST /api/inference
R->>D: 查询 images / category_models
R->>M: 创建或复用 predictor
M-->>R: 返回推理结果
R->>D: 写入 inference_results
R-->>A: 返回 resultPath / inferenceTime / device
A-->>P: 返回 JSON
P->>U: 展示输出图和信息
12.2 模型预加载链路
sequenceDiagram
participant P as 页面组件
participant A as frontend/src/api.js
participant R as inference.py
participant M as predictor
P->>A: api.inference.preload(...)
A->>R: POST /api/inference/preload
R->>M: 创建 predictor
R->>M: warm-up
R-->>A: status=loaded
A-->>P: 已加载
12.3 页面离开或取消选中
flowchart LR
A[页面取消选中或切换页面] --> B[调用 unload]
B --> C[inference.py 查找缓存]
C --> D[释放 predictor]
D --> E[gc.collect]
13. 当前架构的优点
- 前后端职责清楚
- 元数据和推理执行分离
- 本地部署简单
- 适合持续增加新任务页和新模型
- 预加载与缓存机制已经具备实用价值
14. 当前架构的主要限制
- 页面组件过重,很多页面同时承担 UI、状态、API 编排职责
inference.py过于核心,已开始承担较多服务层职责- 数据模型仍存在兼容性存储,例如
Pose的关节数 - 某些设置项仍未彻底和真实执行逻辑对齐
这是一个以 Vue 页面组织任务、以 FastAPI 编排推理、以 SQLite 保存元数据、以 ONNX Runtime 执行模型的本地桌面化 AI 推理平台。
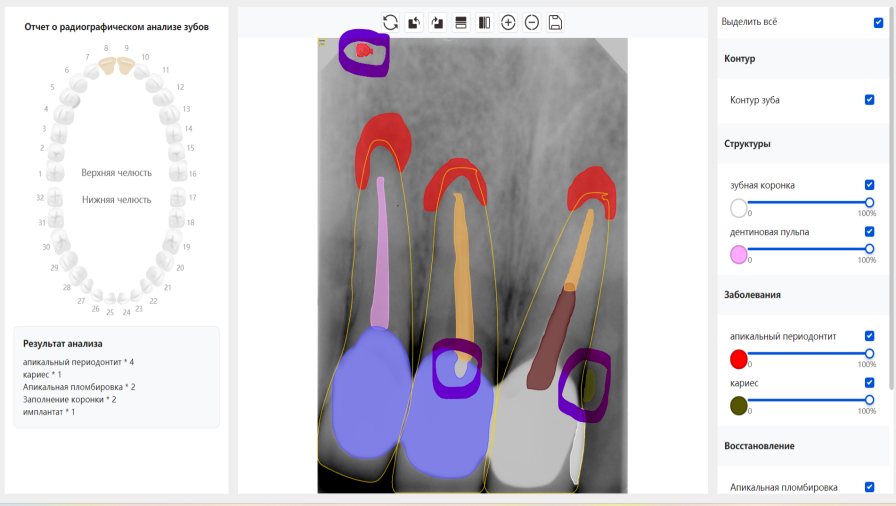
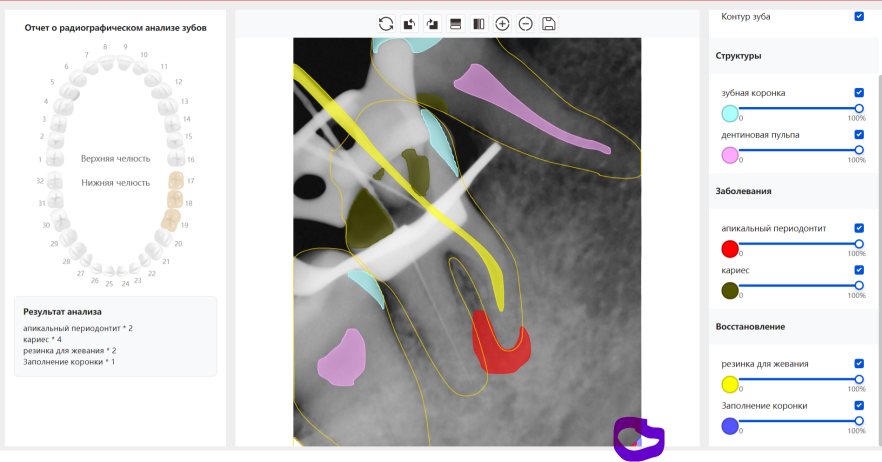
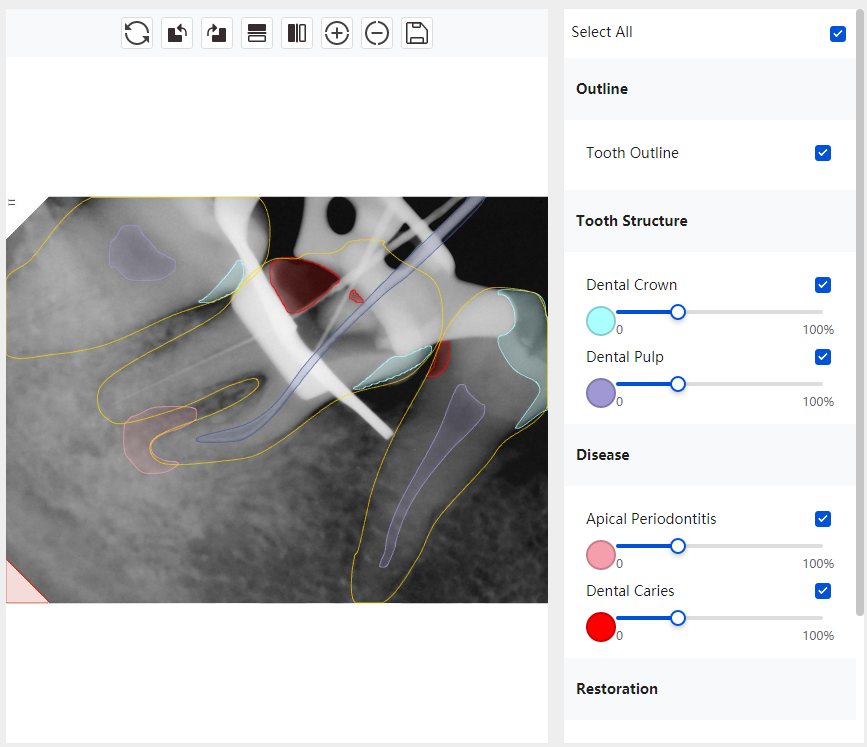
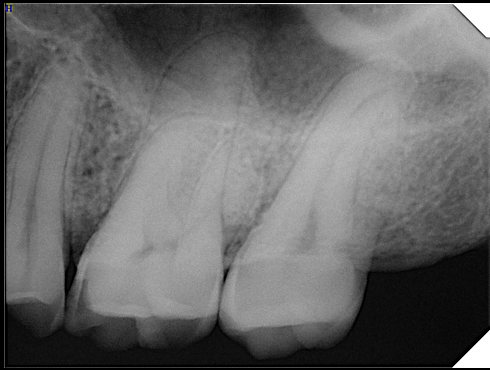
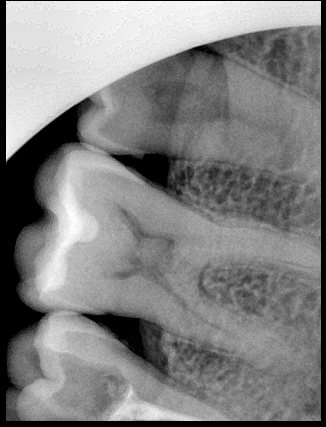
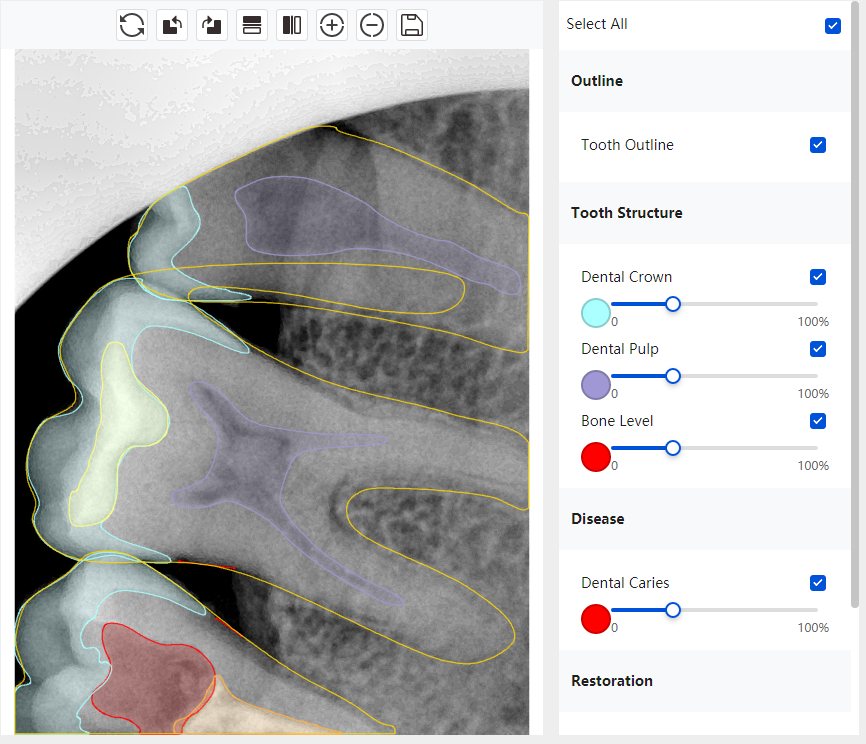
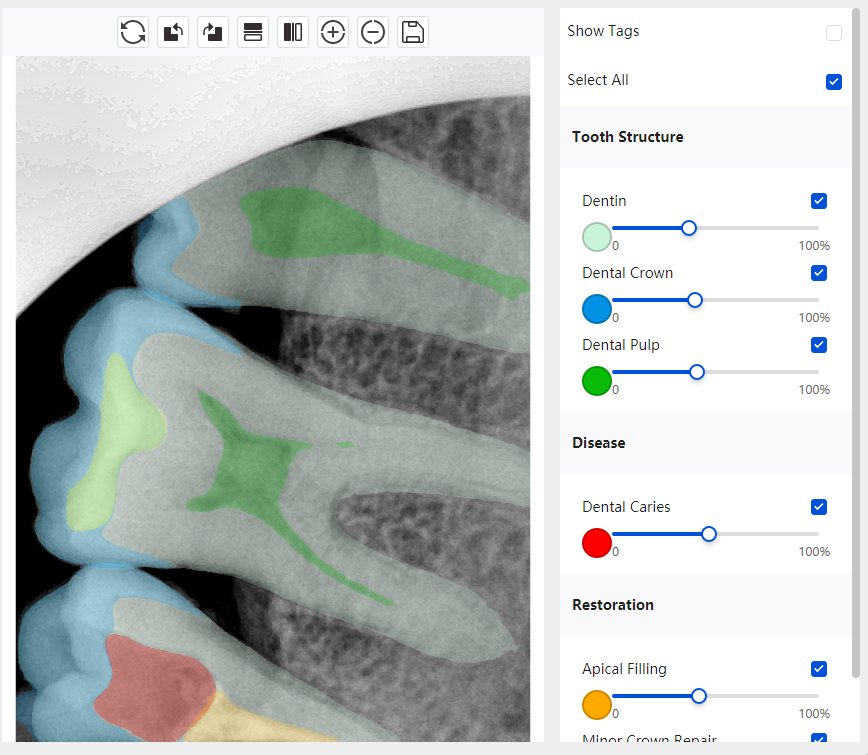
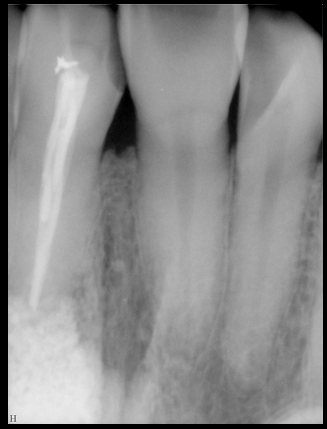
CR/DR 牙齿分割阶段记录
Updated: 2026-04-13(更新日期)
当前进展
- 完成了 CR/DR 牙齿相关分割训练
- 当前结果已经达到阶段预期,但仍有细节问题需要继续处理
相关测试
遇到的问题
- 训练过程中出现过 mask 下移问题
- 部分结果会出现 box 填充异常
- mask 边缘仍然有比较明显的锯齿感
参考
第二版算法问题测试
Updated: 2026-04-13(更新日期)
| 第一版 | 第二版 | 是否解决 | |
|---|---|---|---|
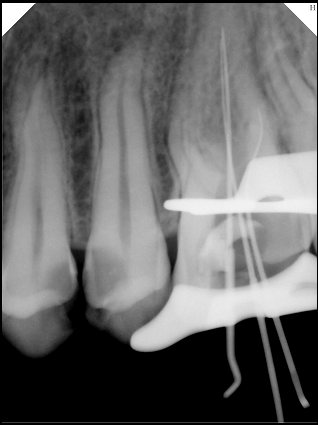 | 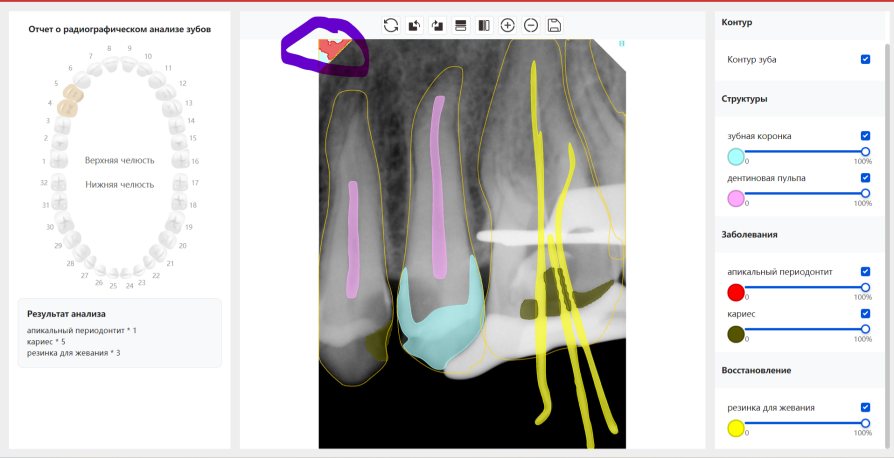 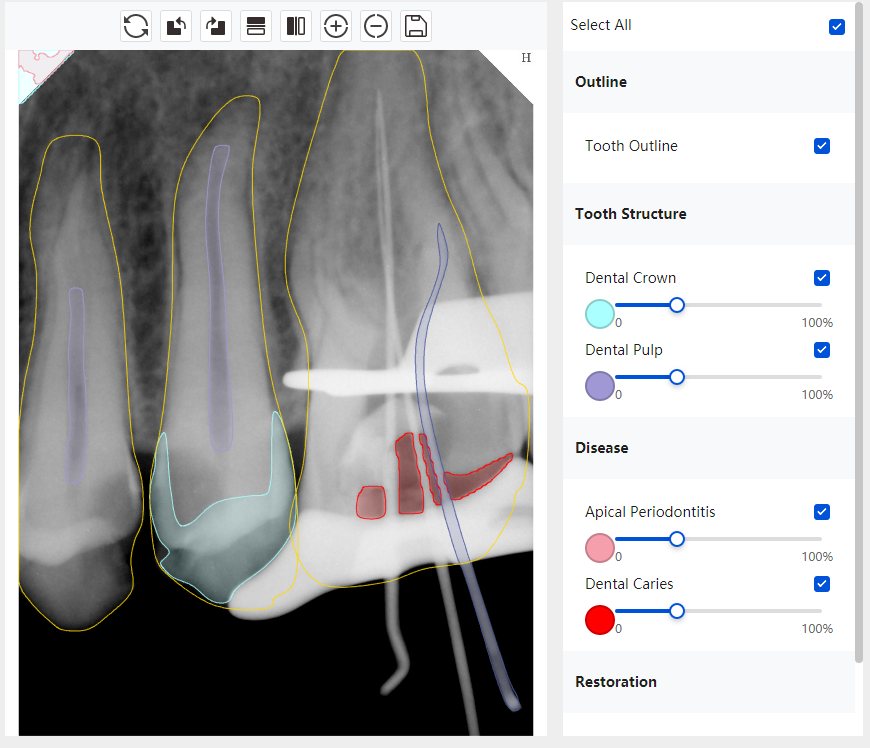 边角识别有问题 龋齿识别不全 牙髓识别不全 | 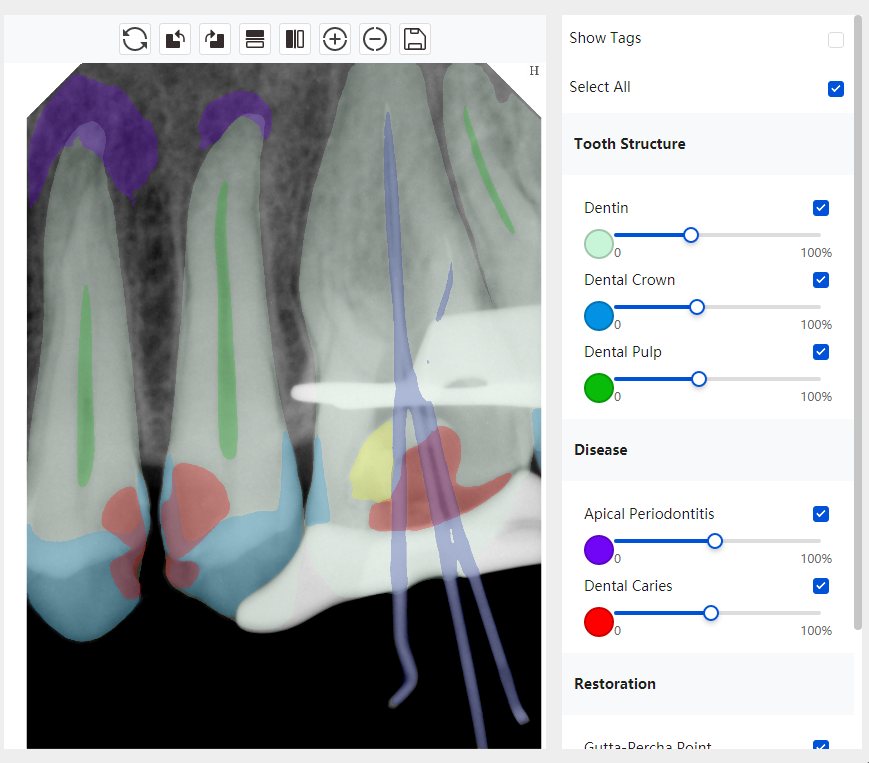 | 解决 |
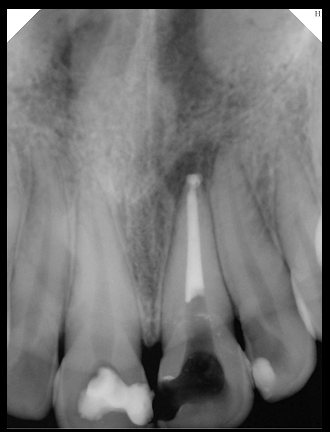 | 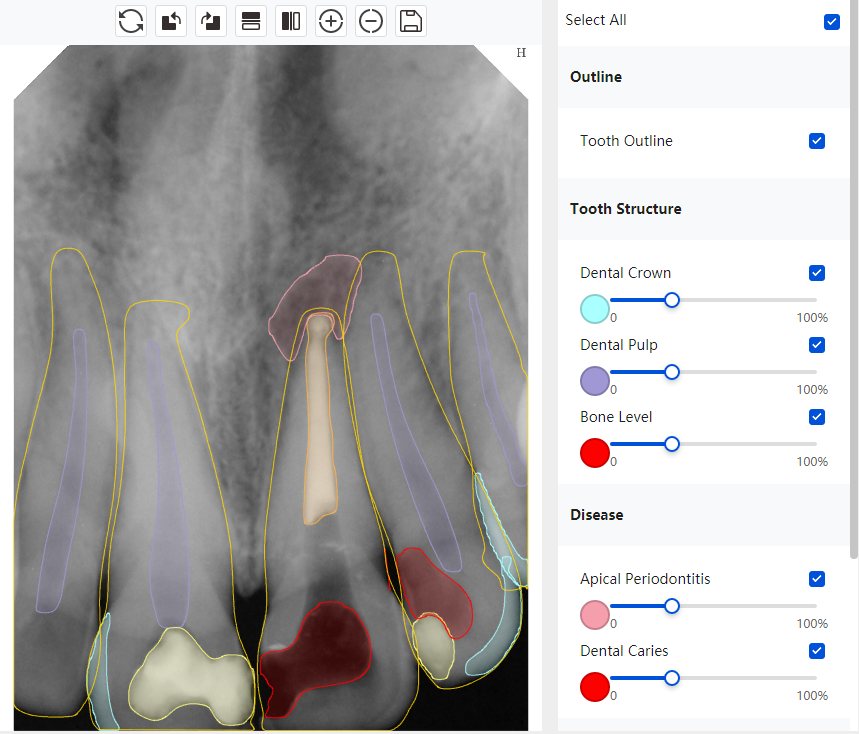 边角识别有问题 识别信息有误 自查(牙冠识别不全) | 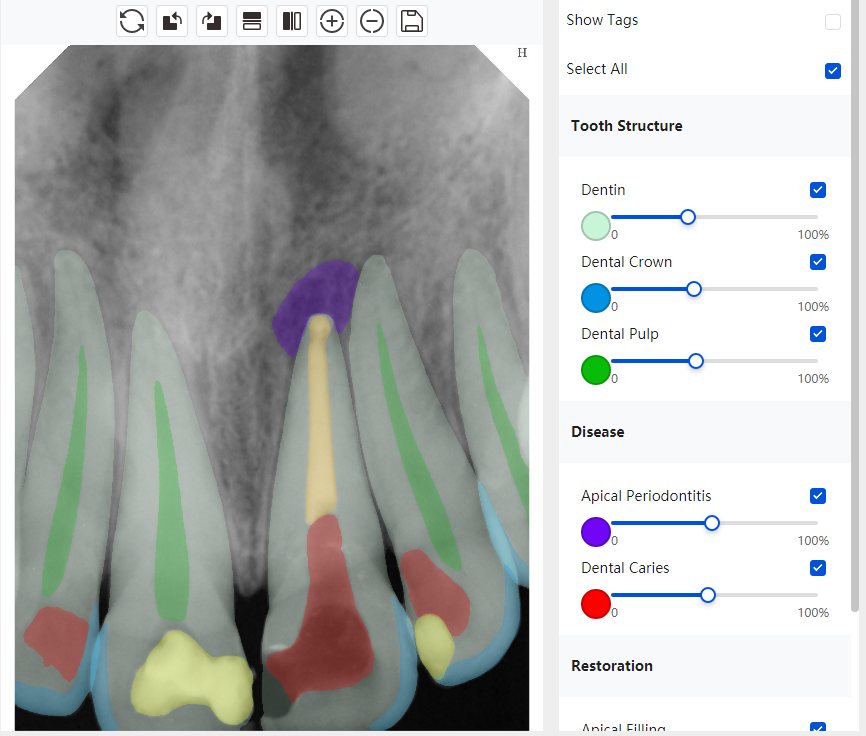 | 解决 |
 |  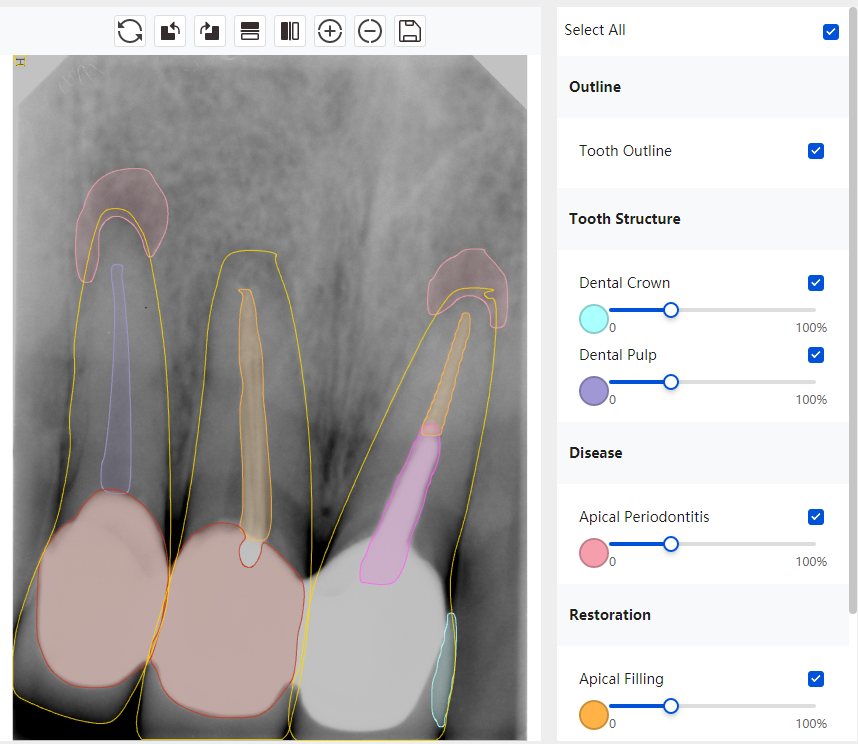 边角识别有误 大范围填充识别遗漏 | 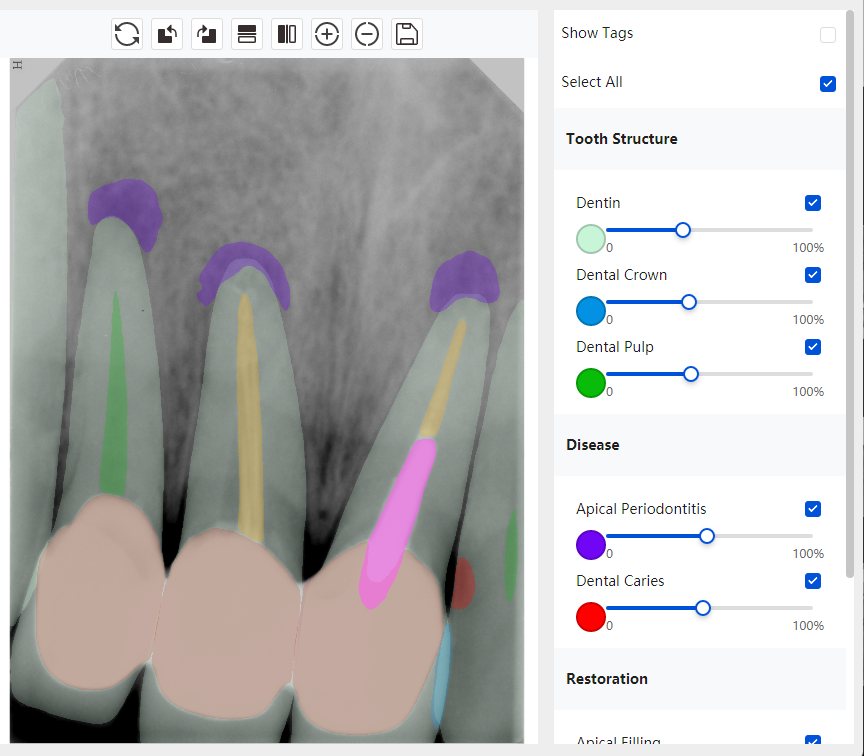 | 解决 |
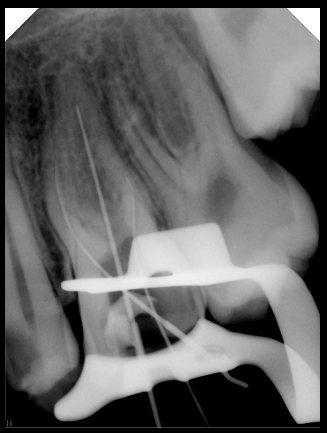 | 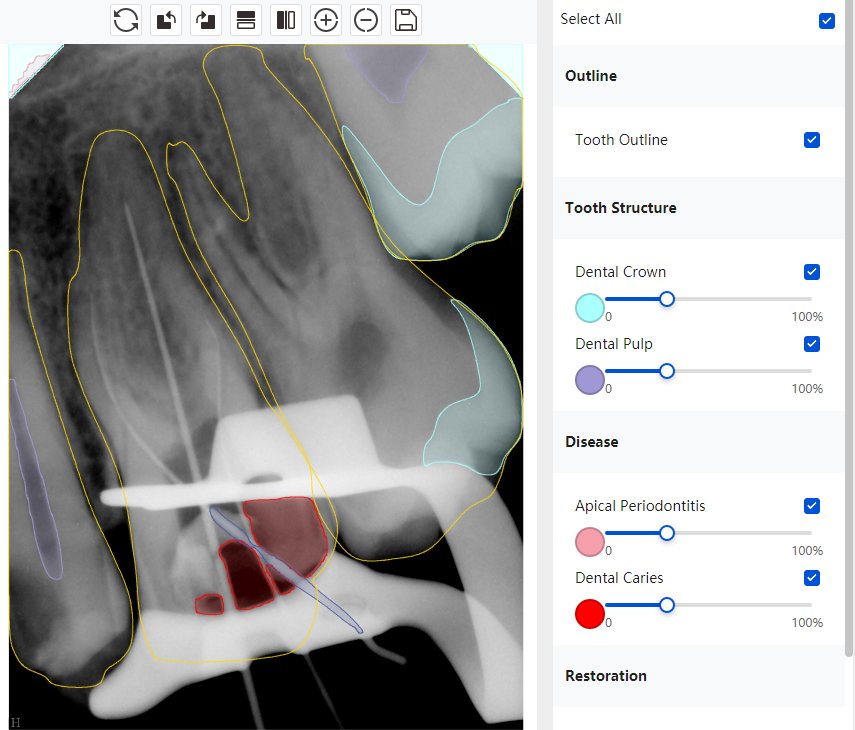 识别信息不全 | 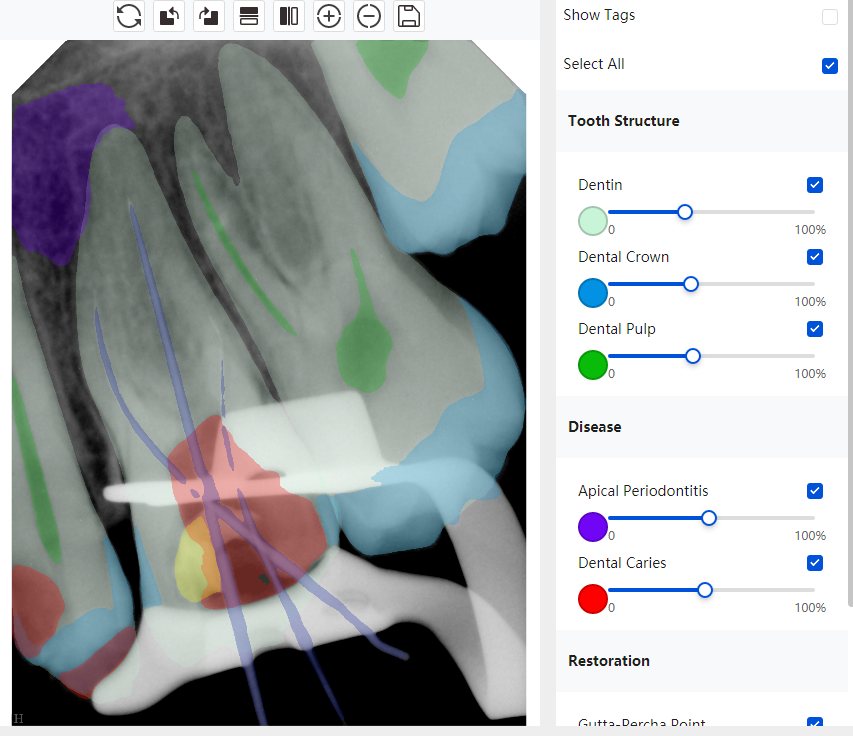 | 解决 |
 |   边角问题 牙胶识别不全 牙冠识别不全 | 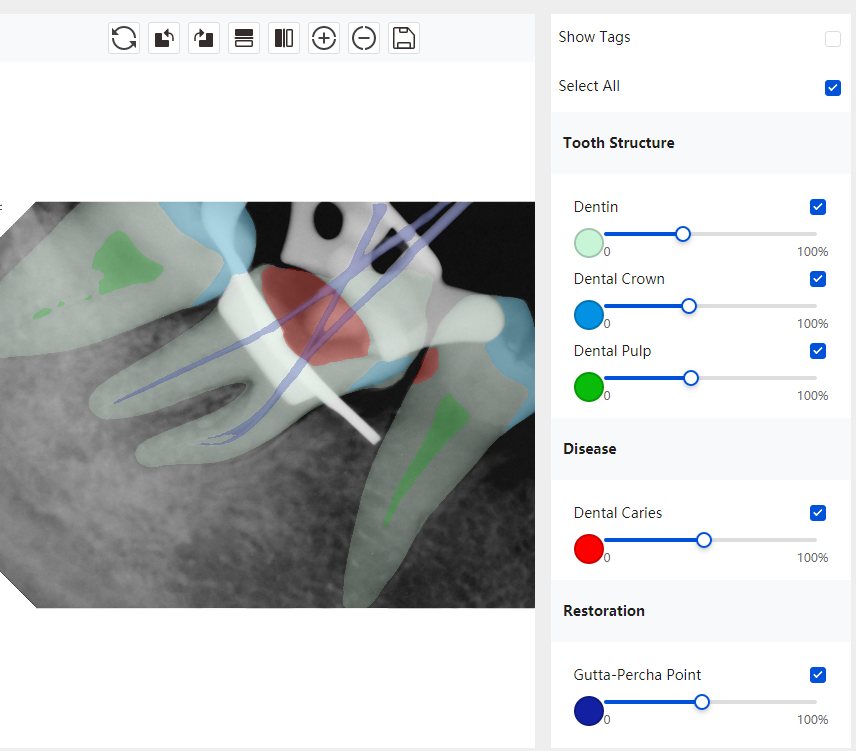 | 解决 |
 换图片 | 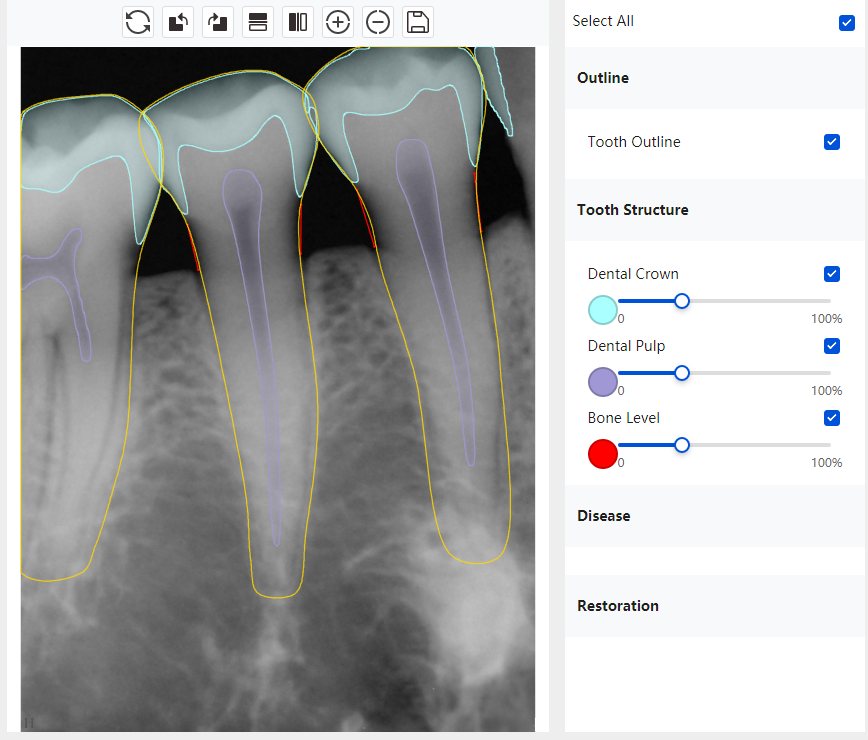 | 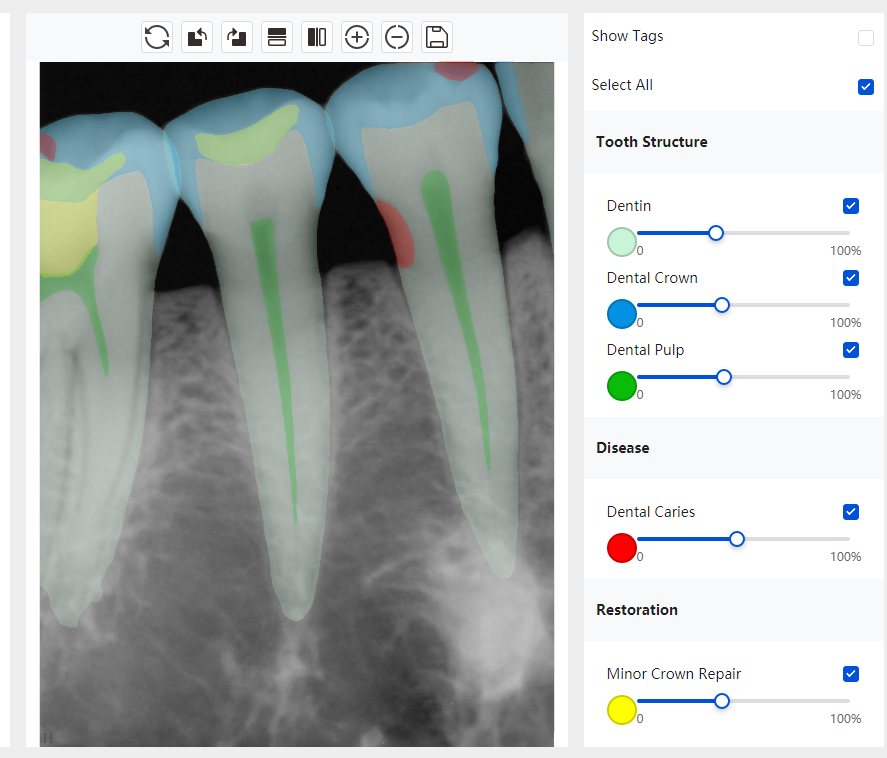 牙冠部分稍微白了一些就识别成小范围修补,部分判断异常 | 部分解决,修复类略敏感,牙冠部分稍微白了一些就识别成小范围修补,部分判断异常。 |
 | 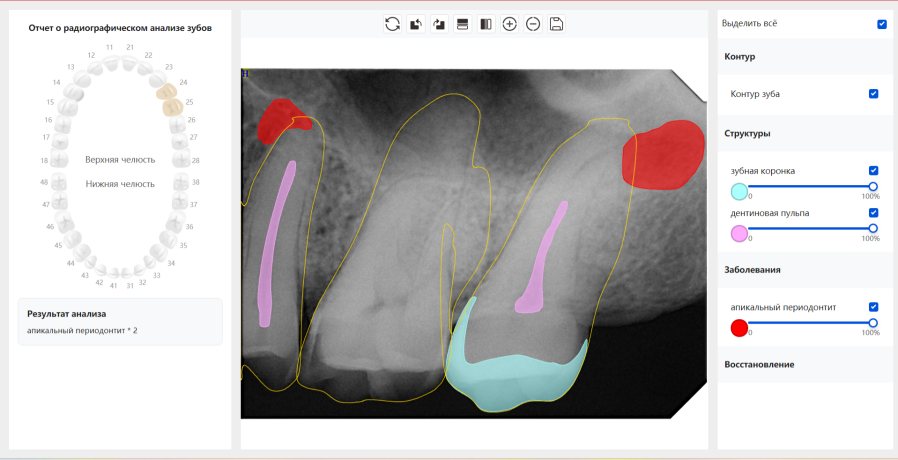 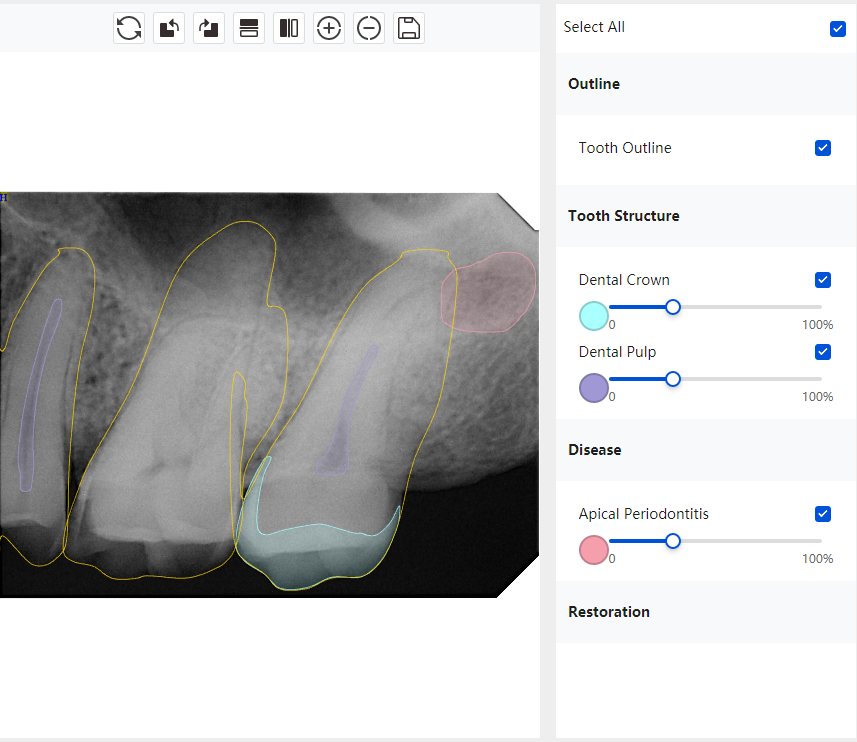 牙冠识别不全 牙髓不全 根尖炎龋齿识别有误 | 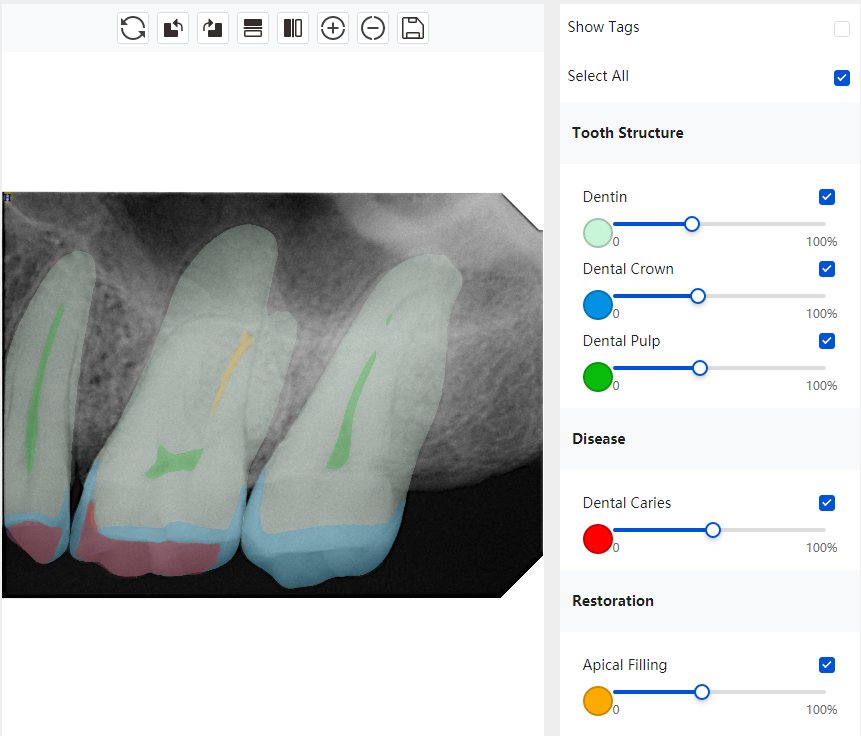 | 解决 |
 |  |  | 解决 |
 换图片 | 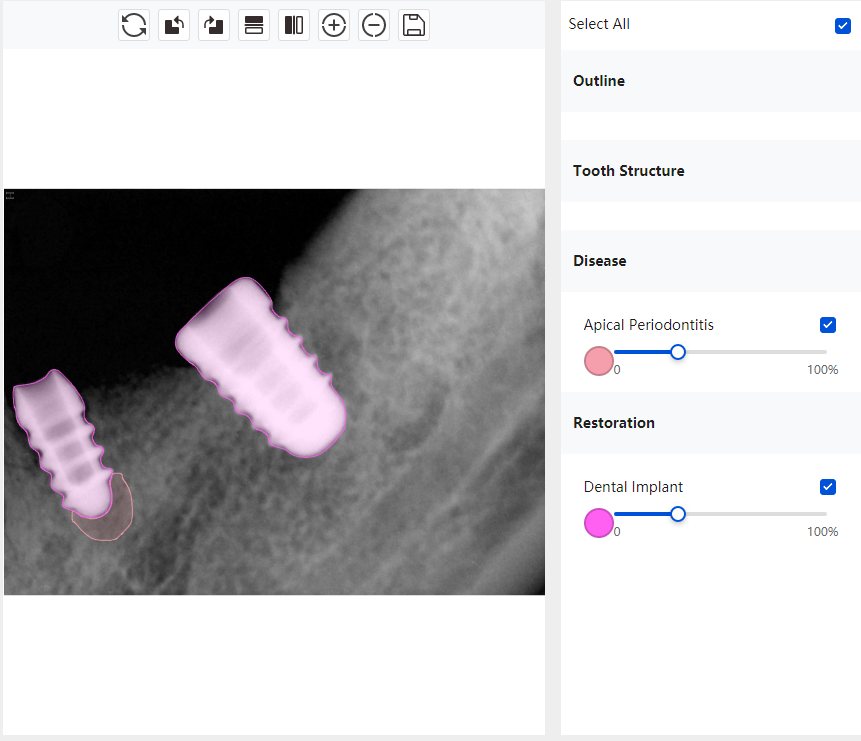 | 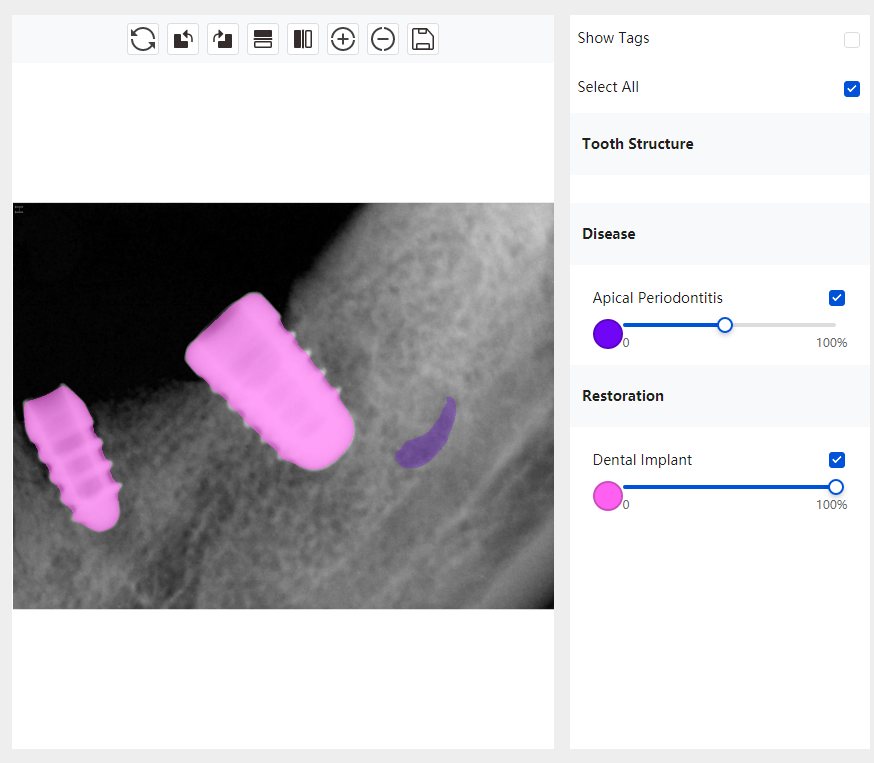 | 解决 |
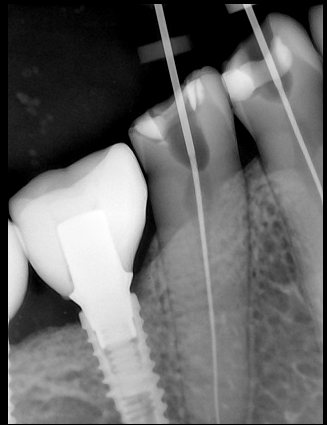 | 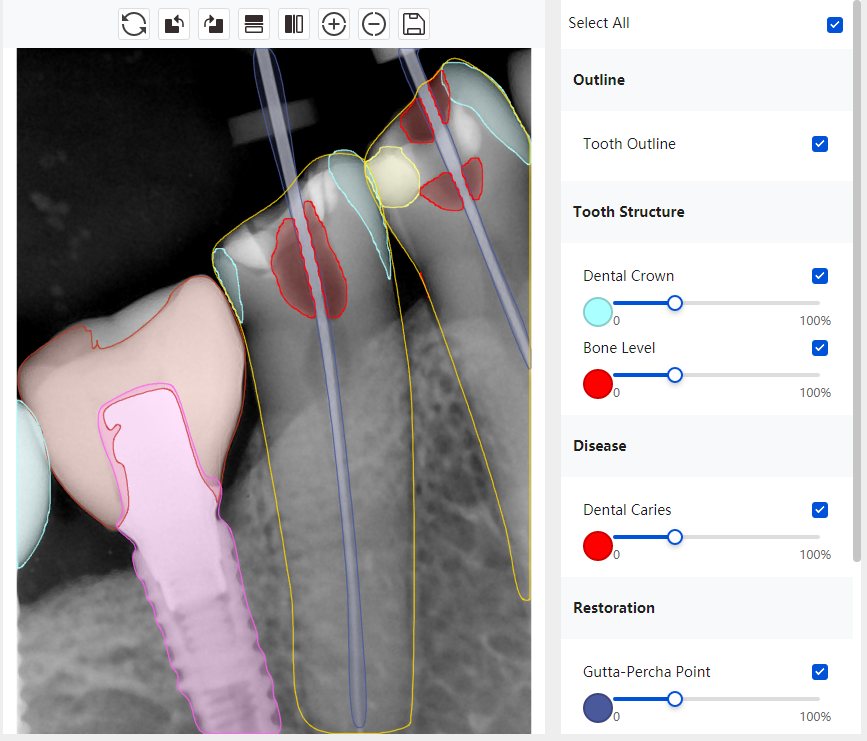 牙冠识别有误 | 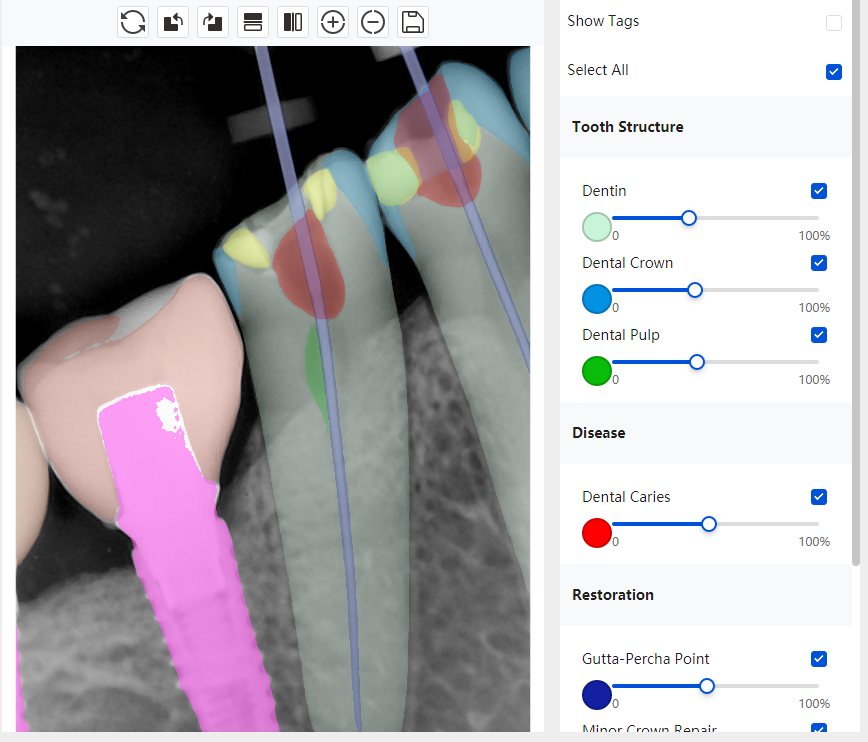 | 解决 |
 | 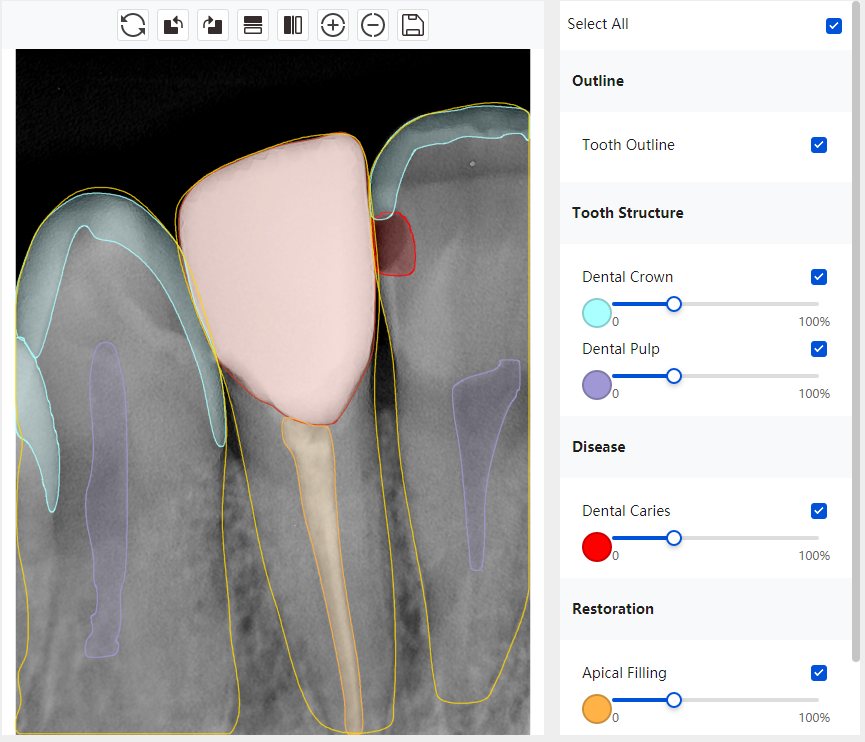 | 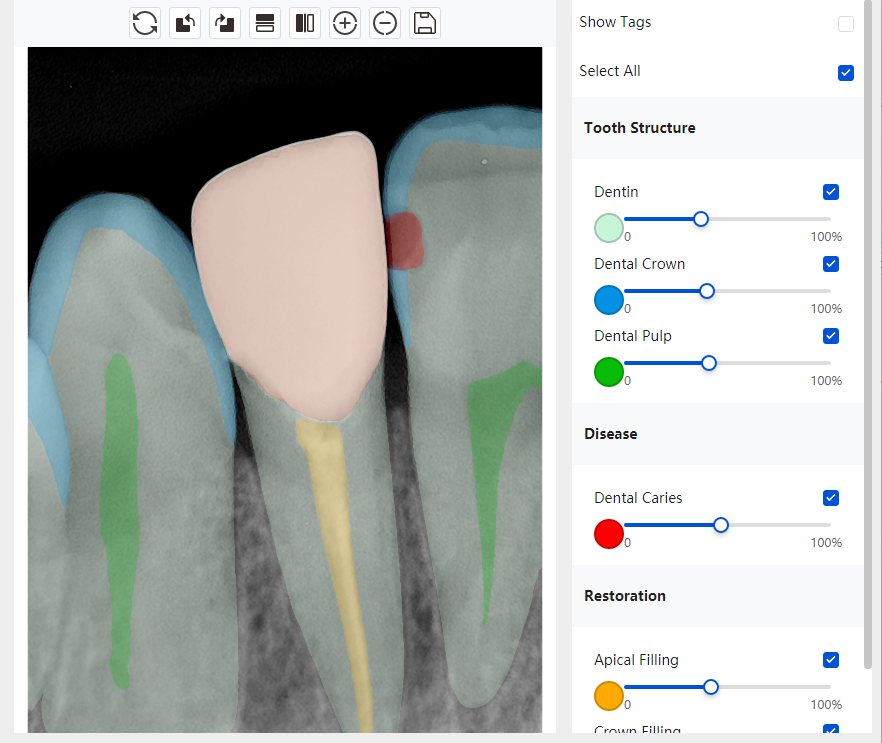 | 解决 |
 换图片 | 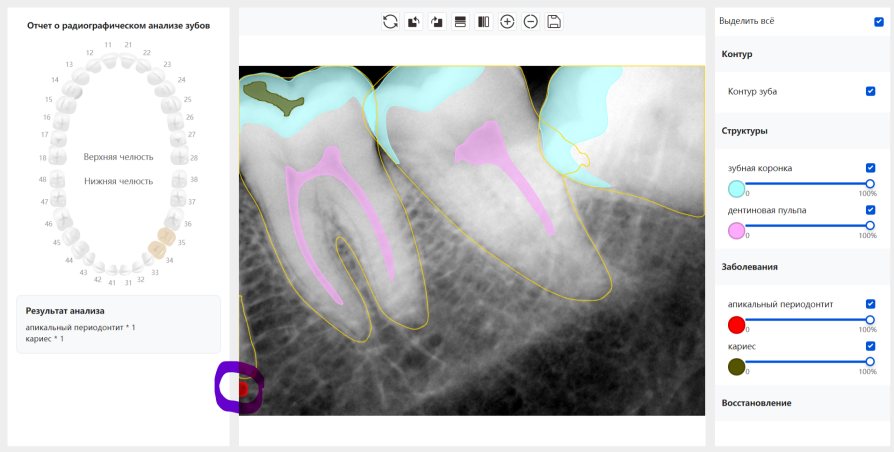 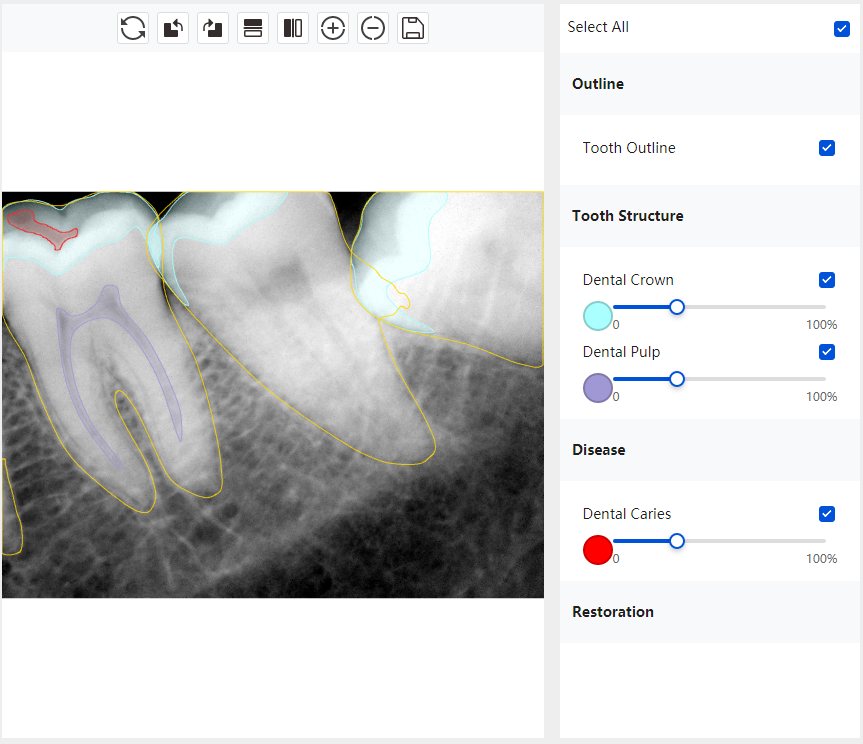 边角识别有误 | 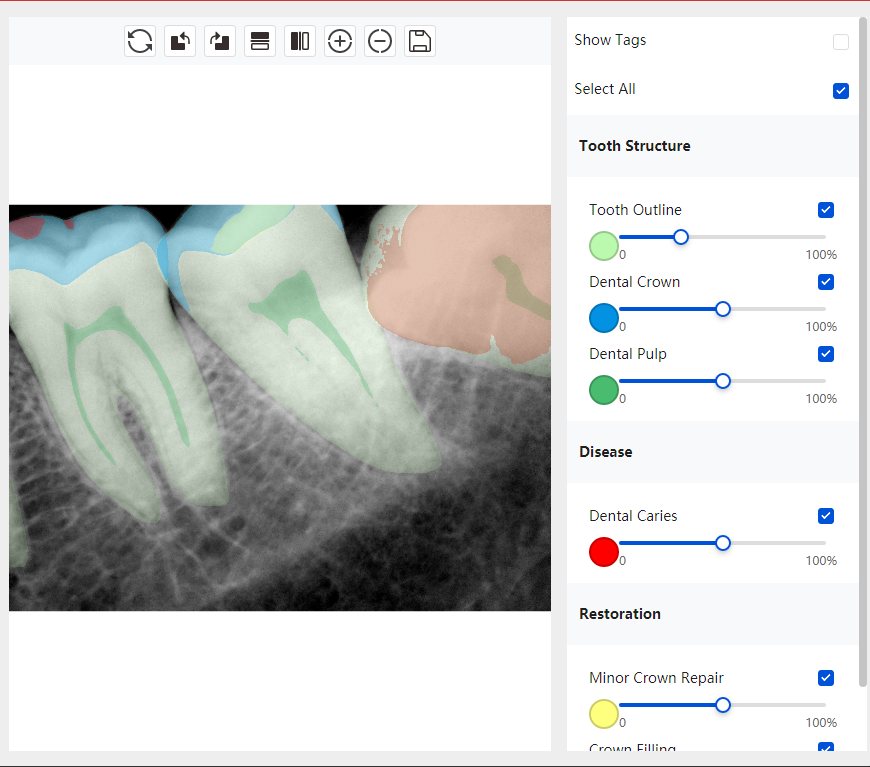 修复类敏感 | 部分解决,图像过白,导致修复类判断异常。 |
 换图片 | 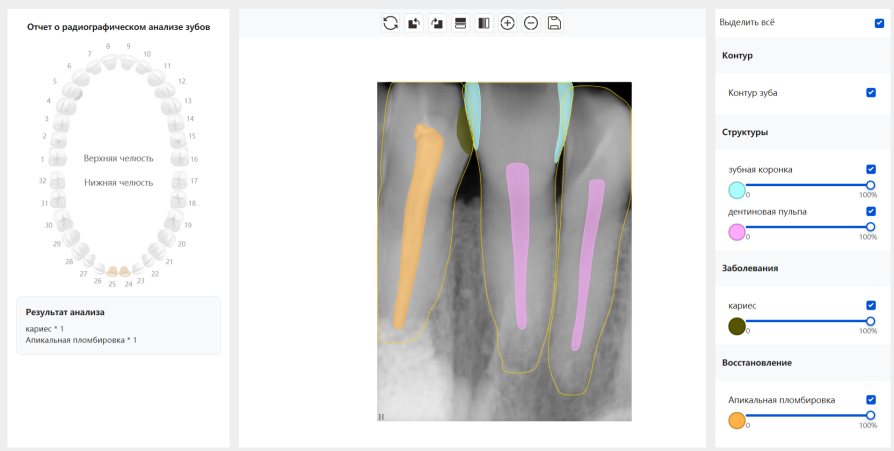 牙冠识别不全 | 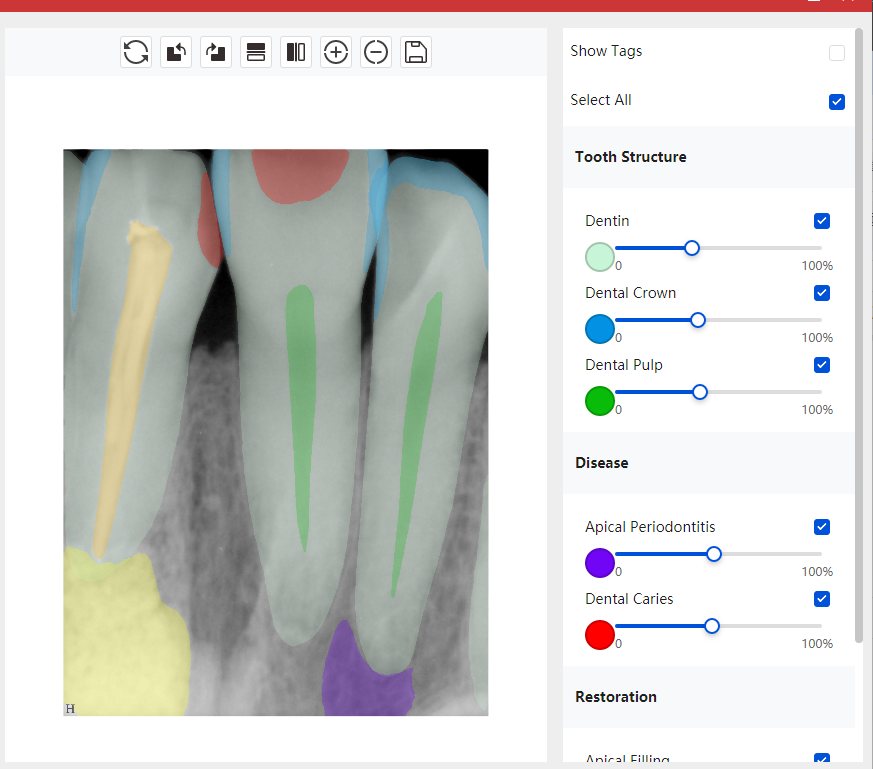 修复类敏感 | 部分解决,图像过白,导致修复类判断异常 |
结论:修复类出现了不鲁棒的情况,后续需要加入轮廓的扩充数据进行增强。
第三版算法分辨率效果比较
Updated: 2026-04-13(更新日期)
| 编号 | 原图 | 第一版 | 第二版 | 第三版 1216x1600 | 第三版 768x1024 | 第三版 1120x1120 |
|---|---|---|---|---|---|---|
| 131315.jpg | 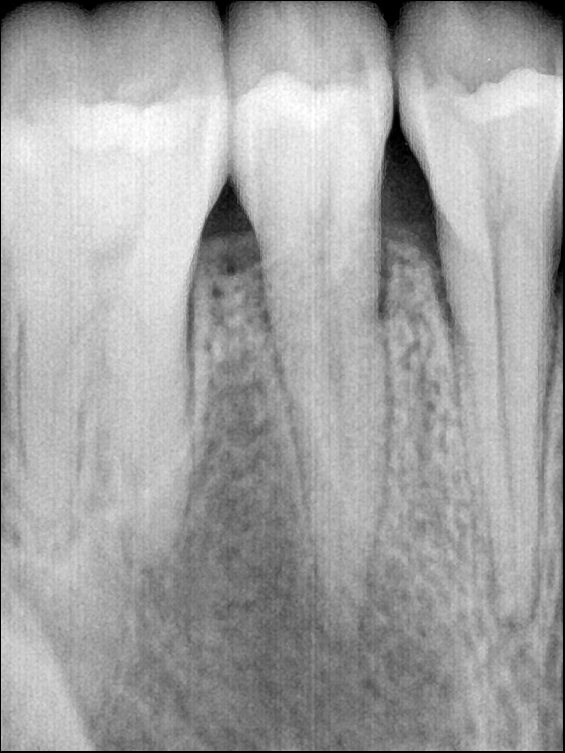 | 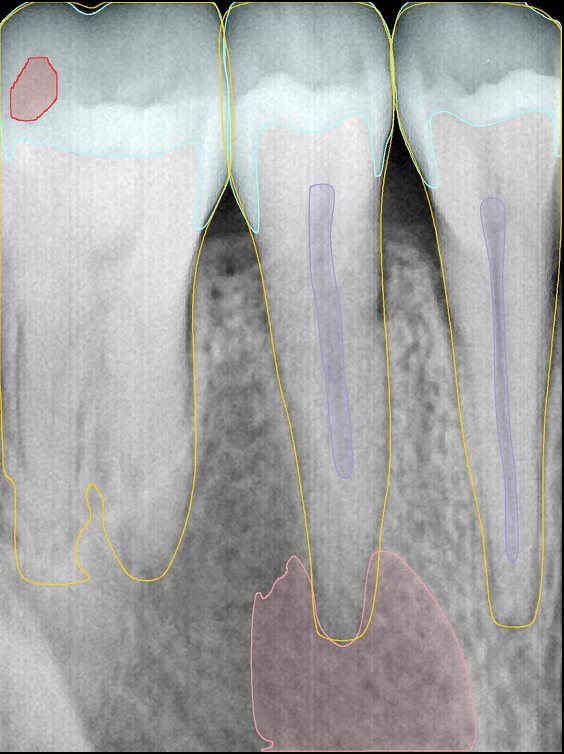 | 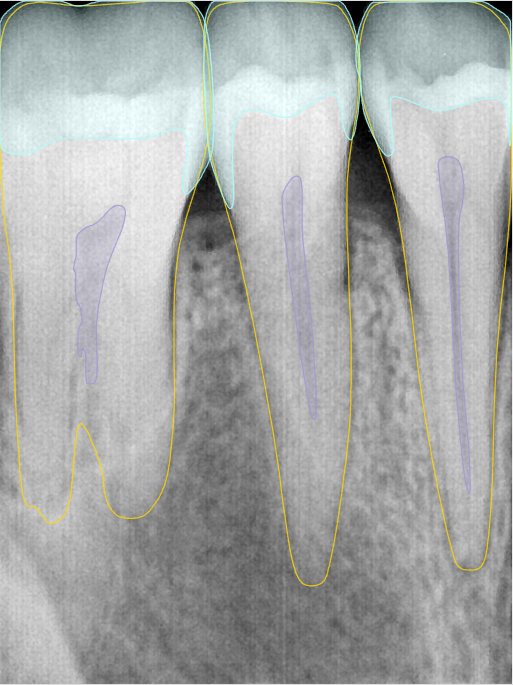 | 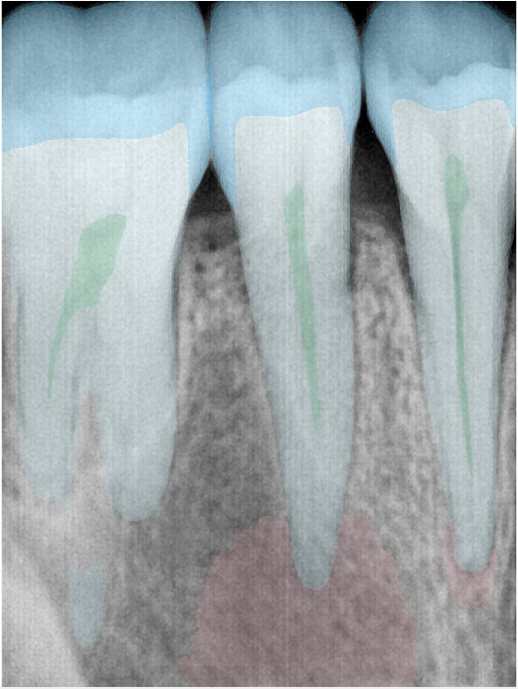 | 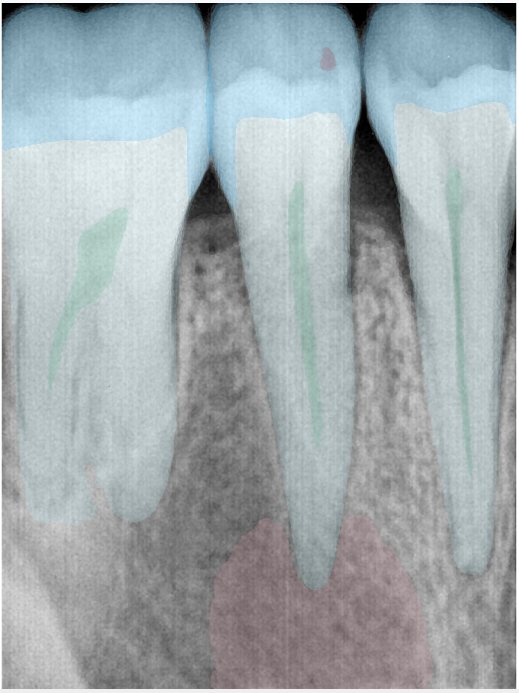 | 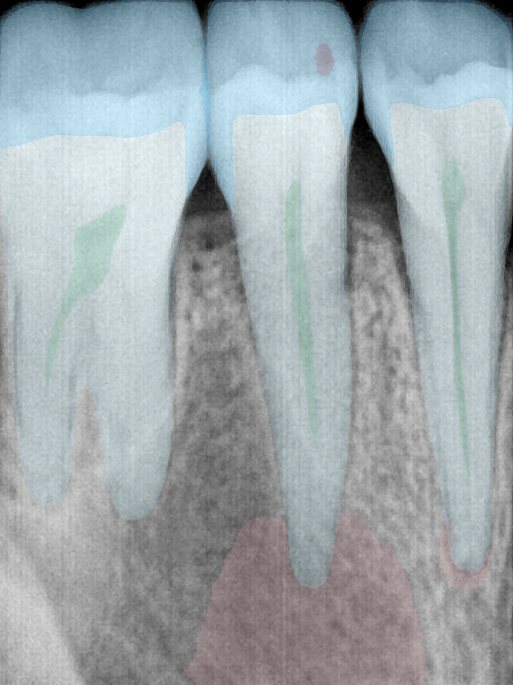 |
| 131316.jpg | 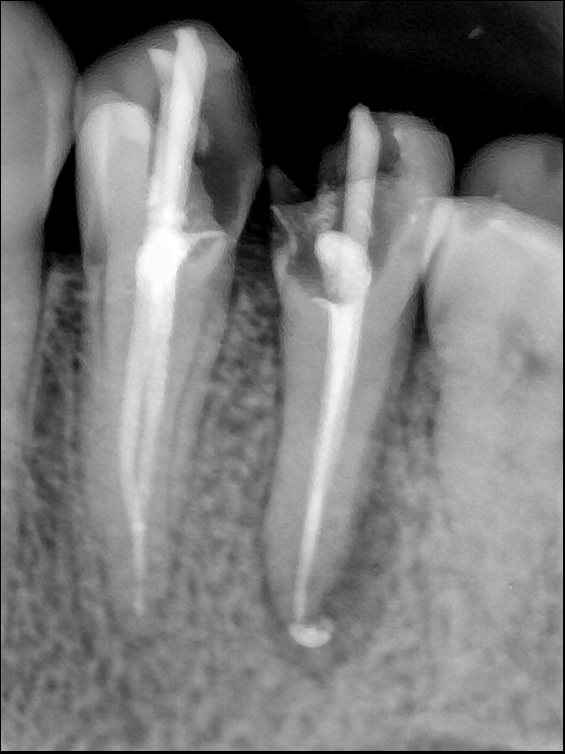 | 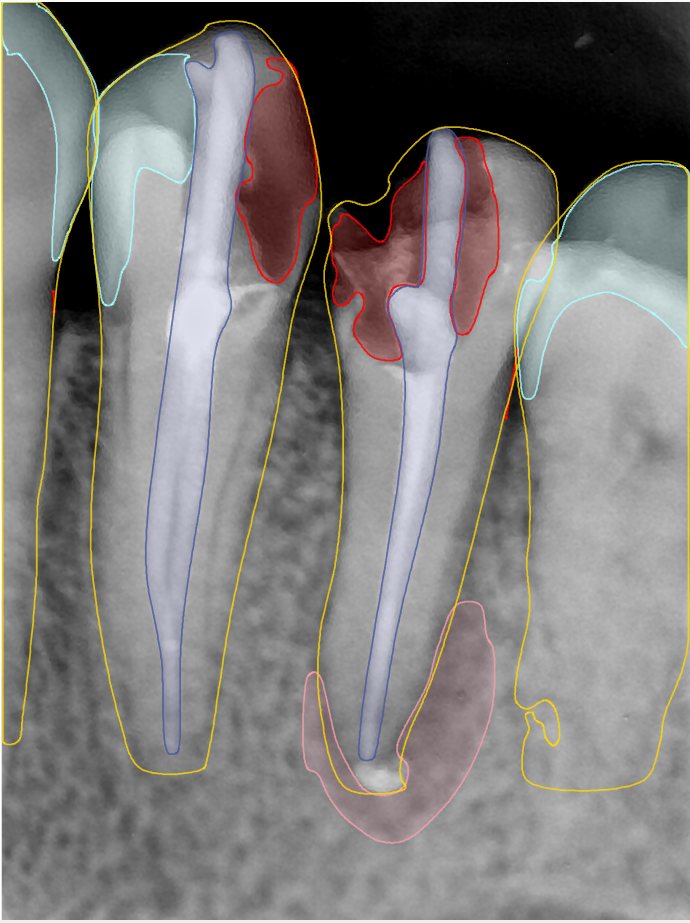 | 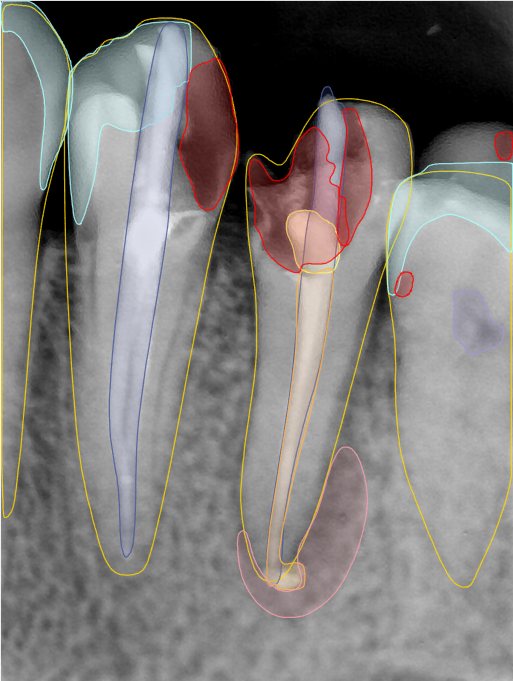 | 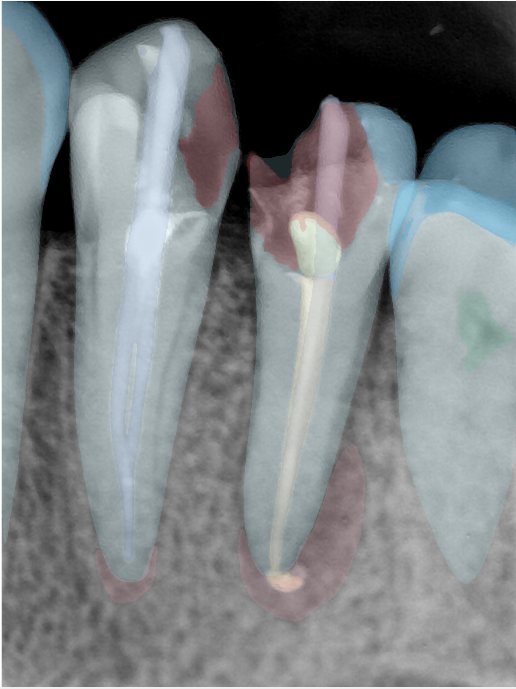 | 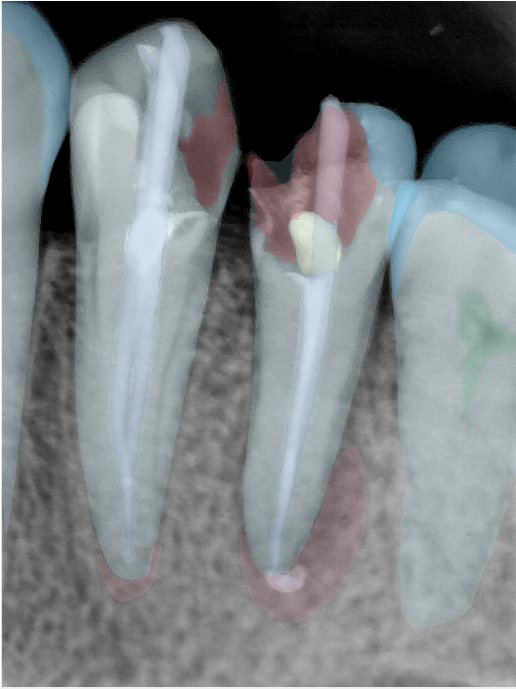 | 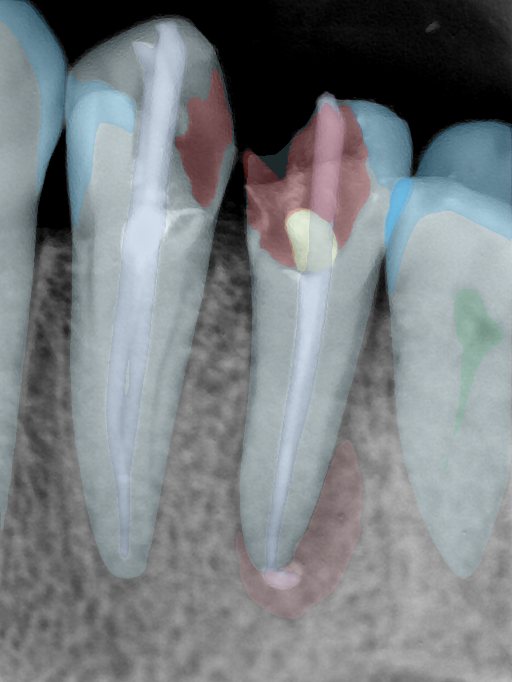 |
| 131317.jpg | 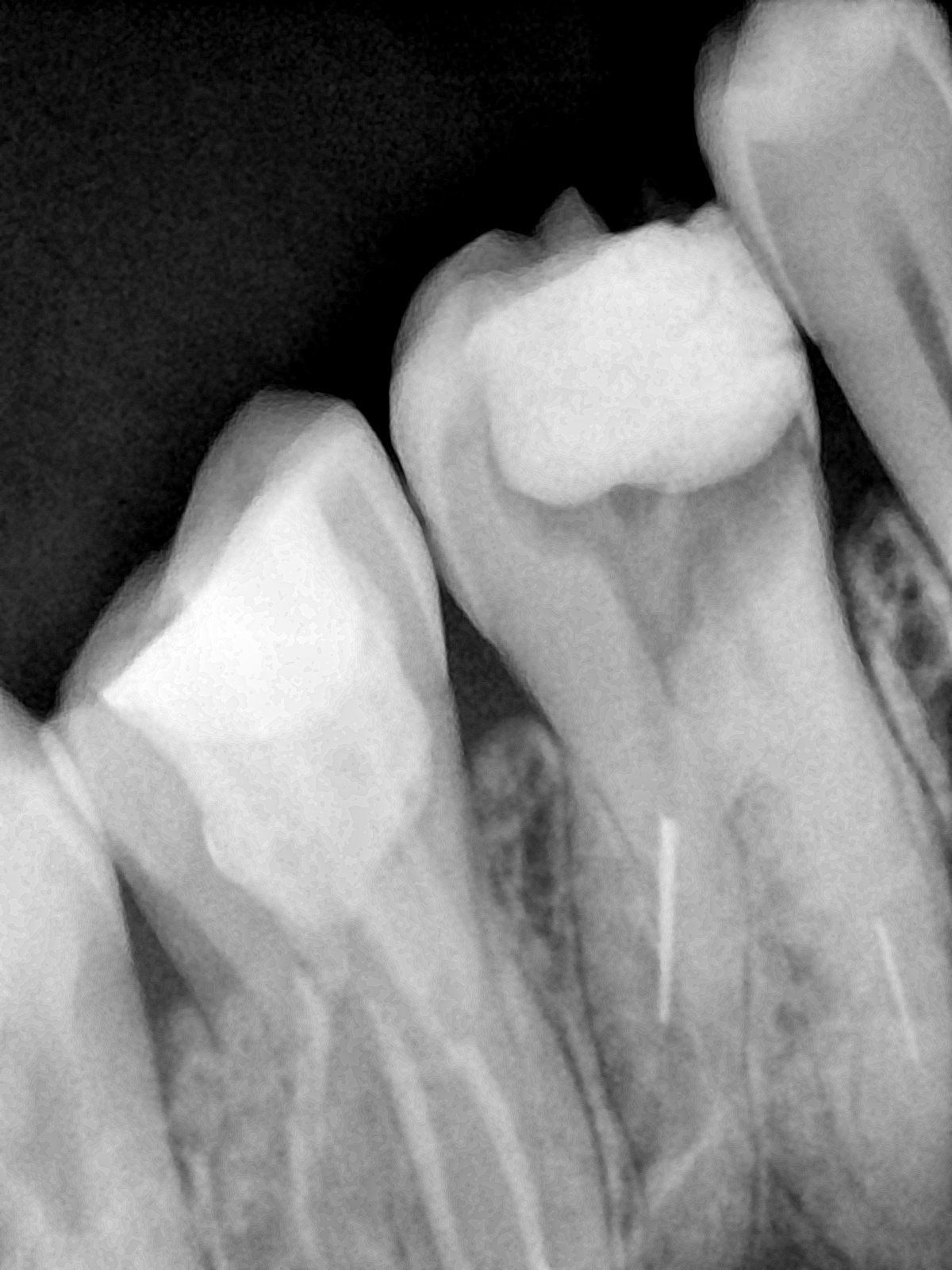 | 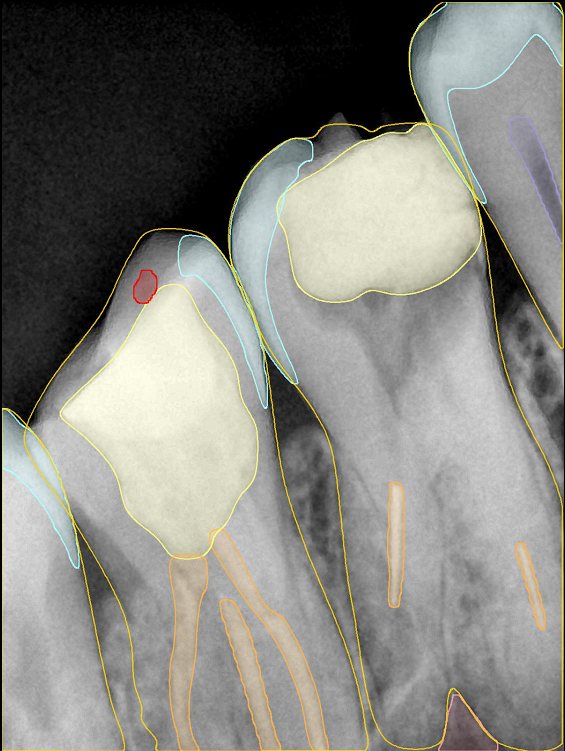 | 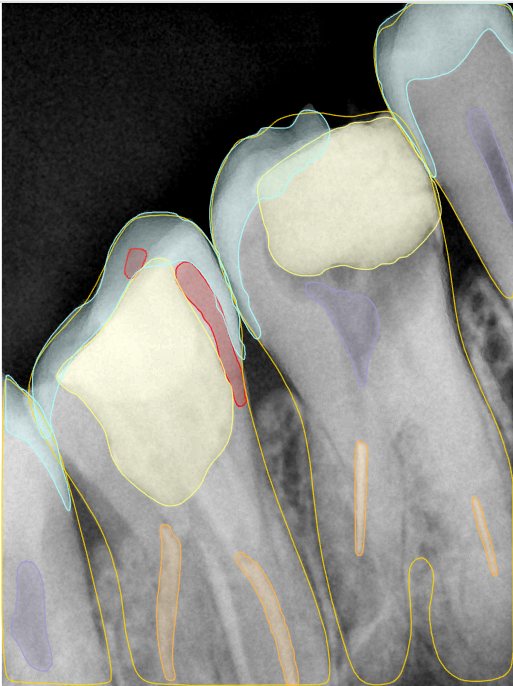 | 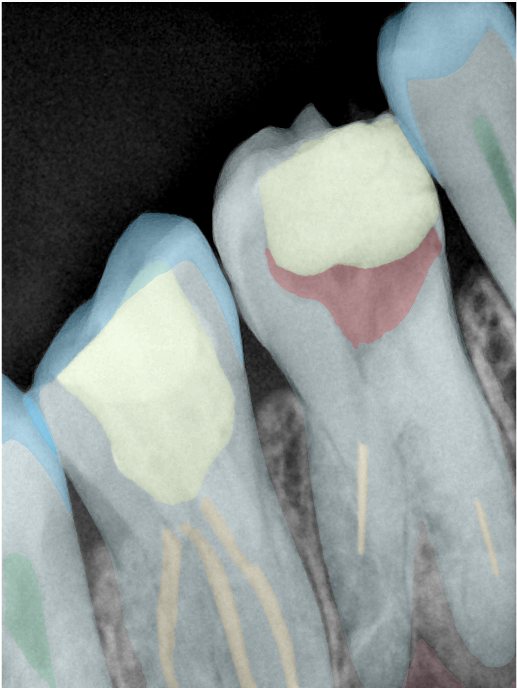 | 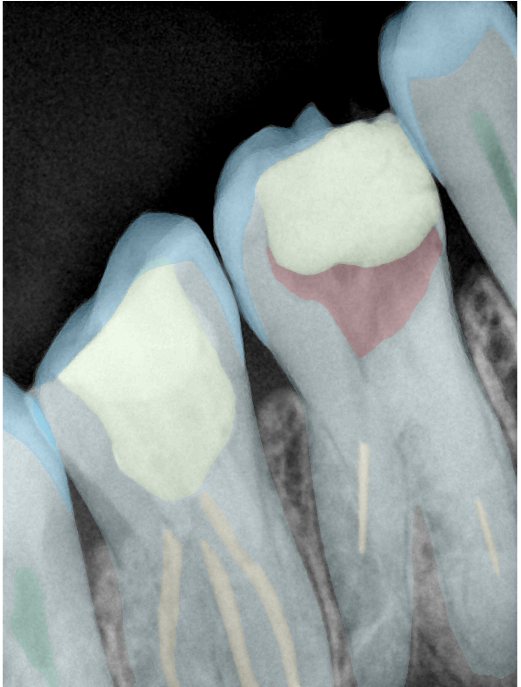 | 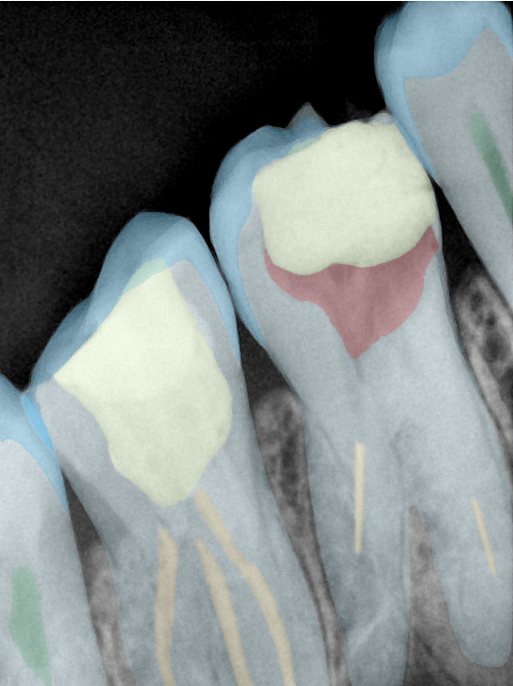 |
| 131318.jpg |  | 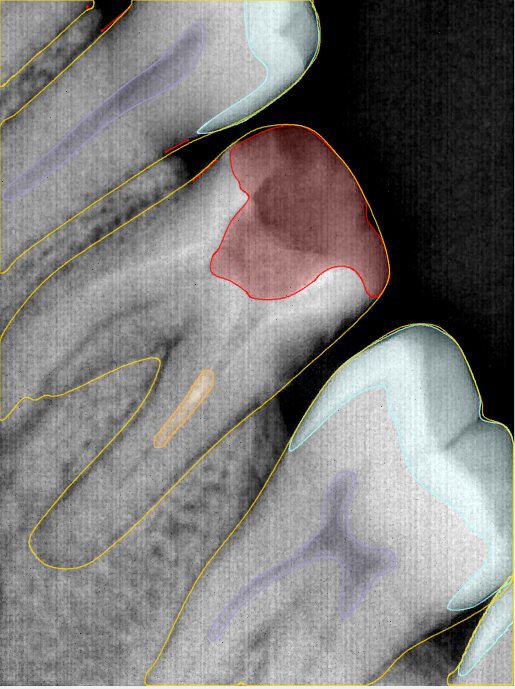 | 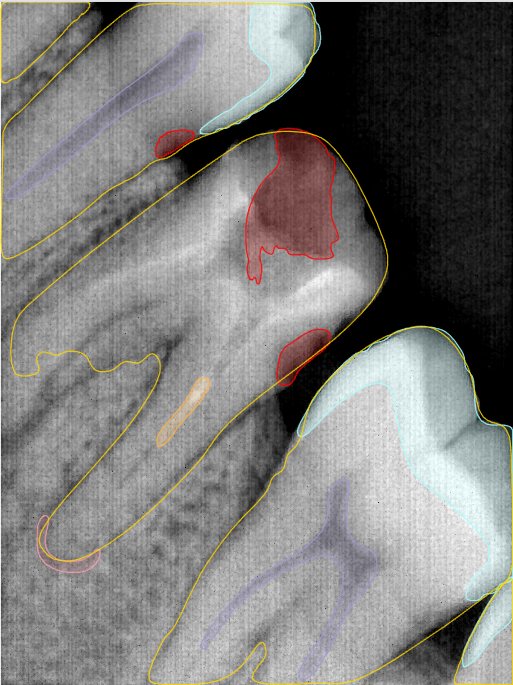 | 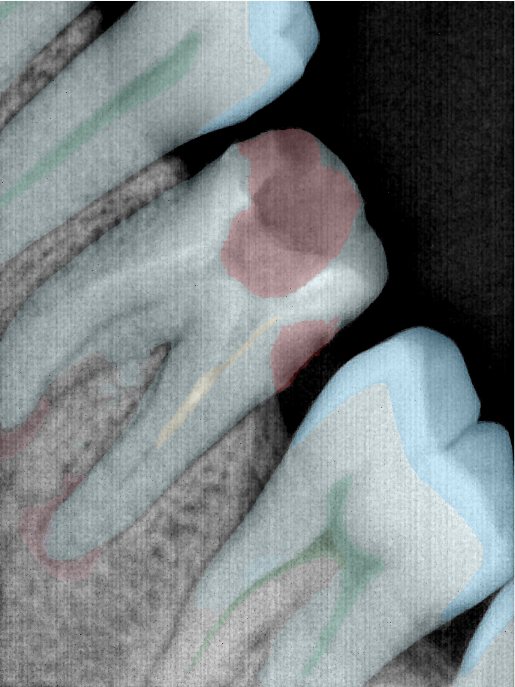 | 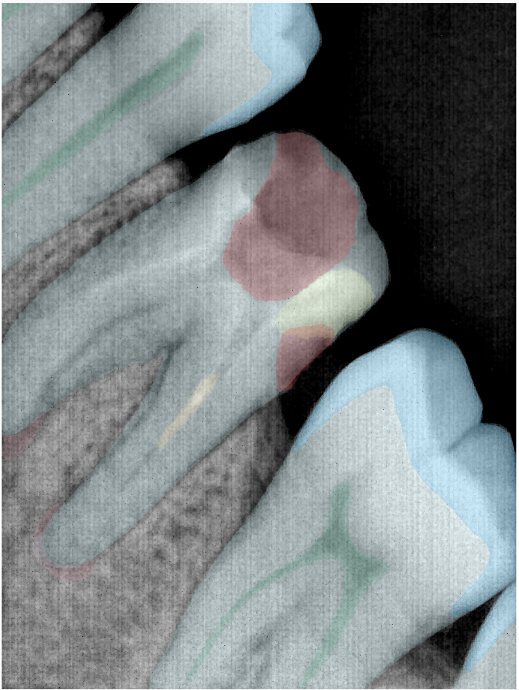 | 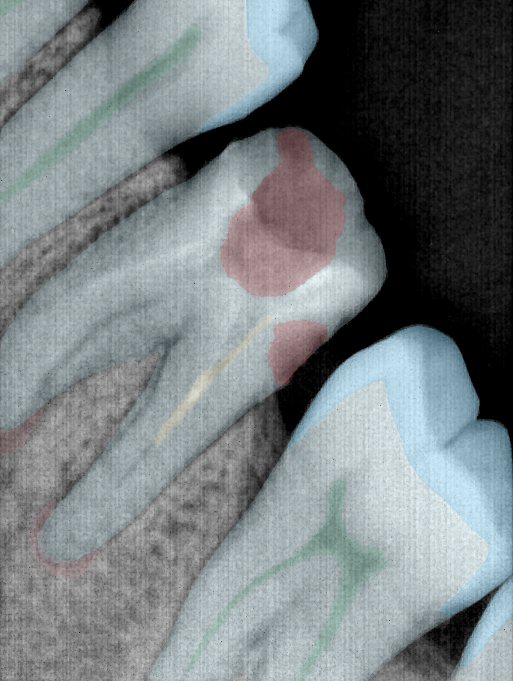 |
| 131319.jpg | 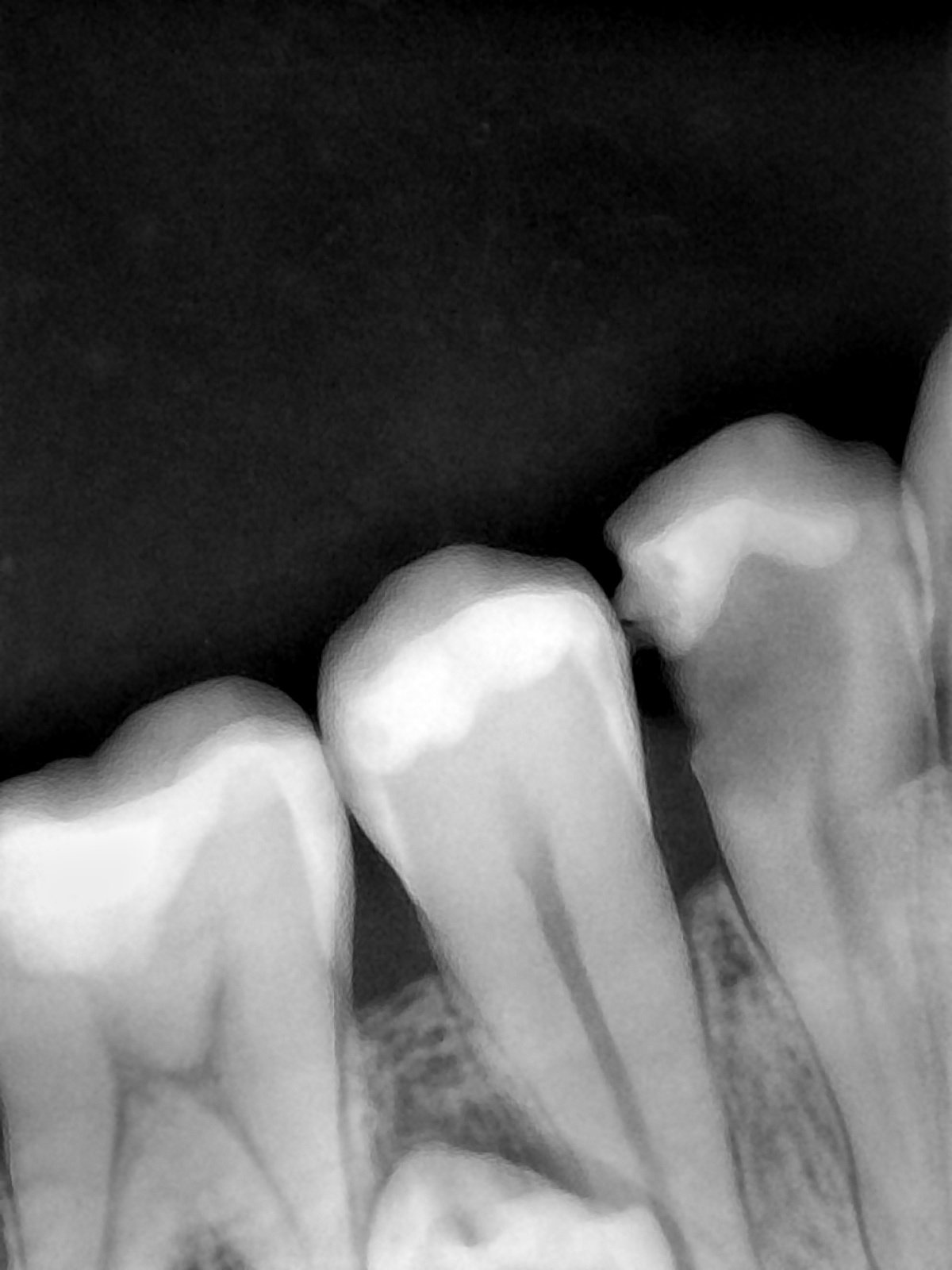 | 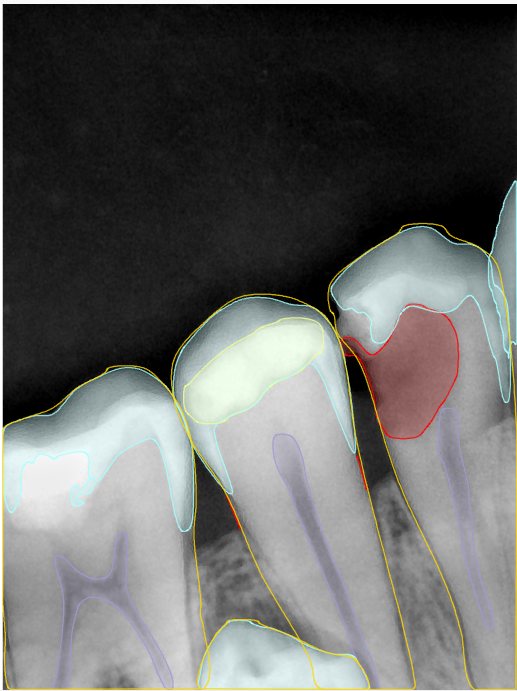 | 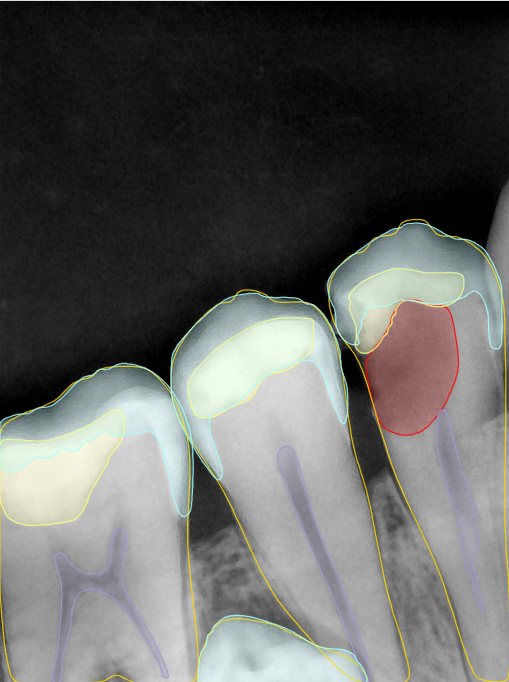 | 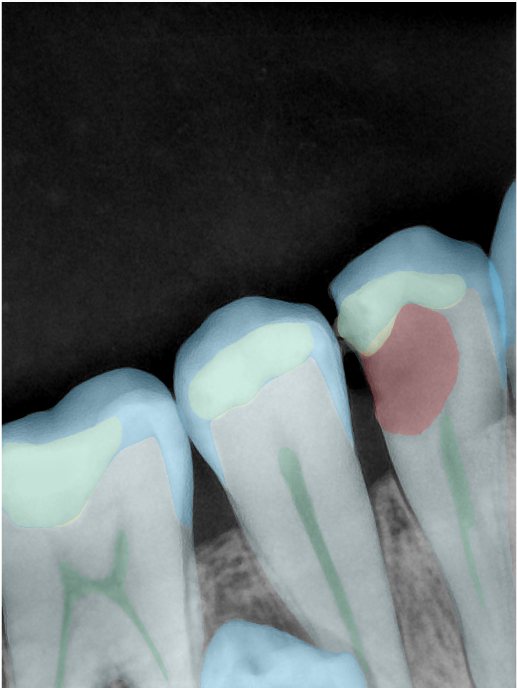 | 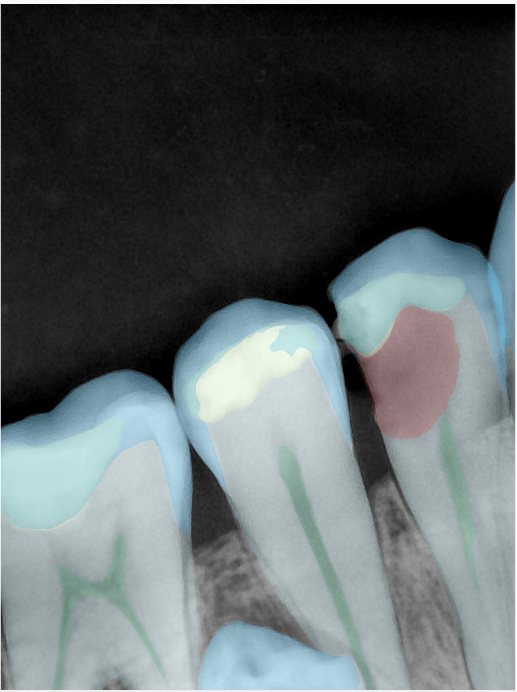 | 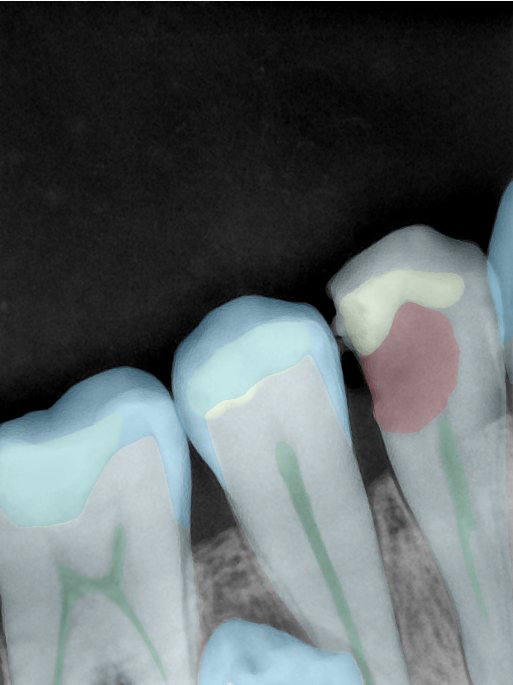 |
| 131320.jpg | 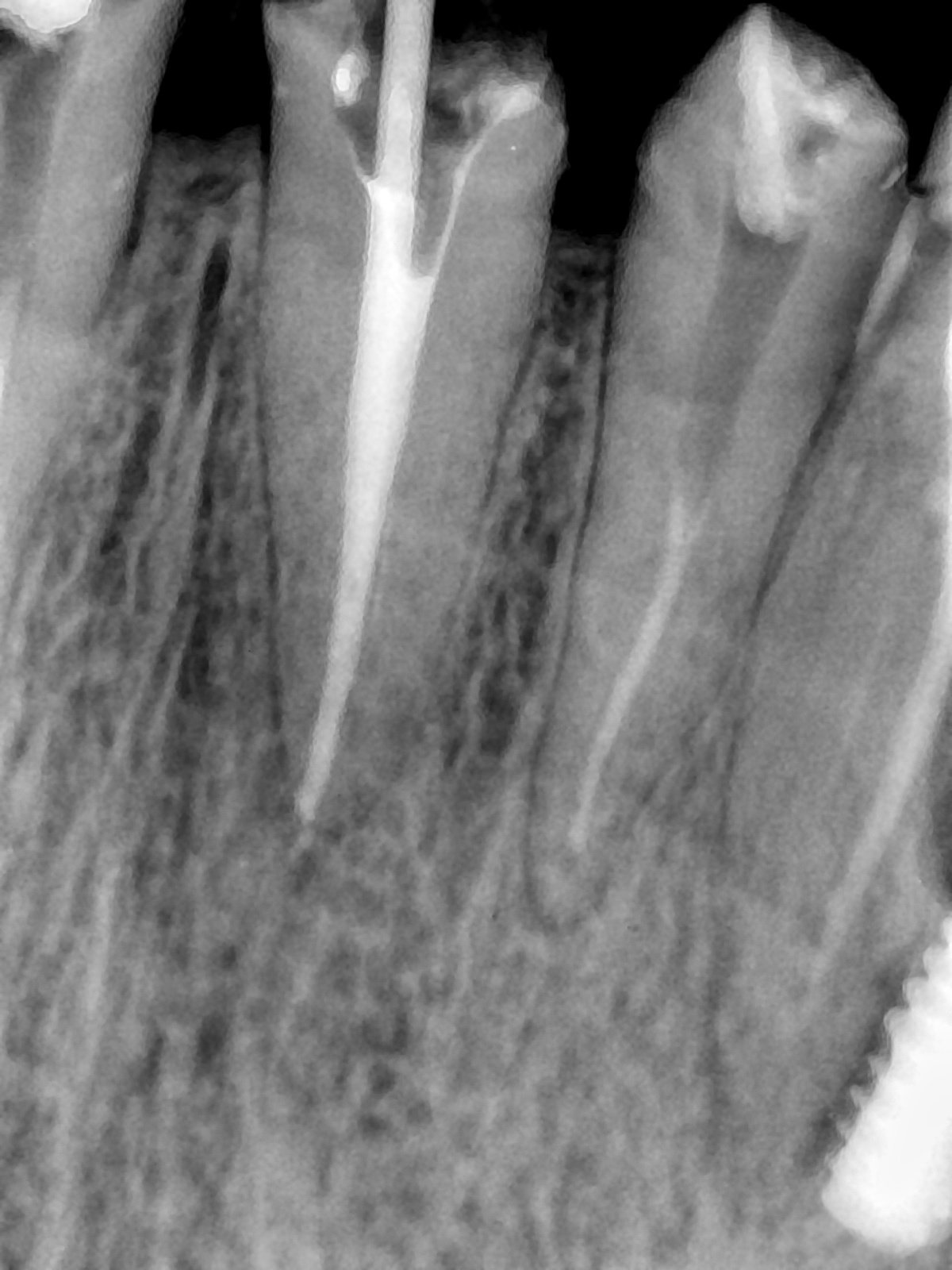 | 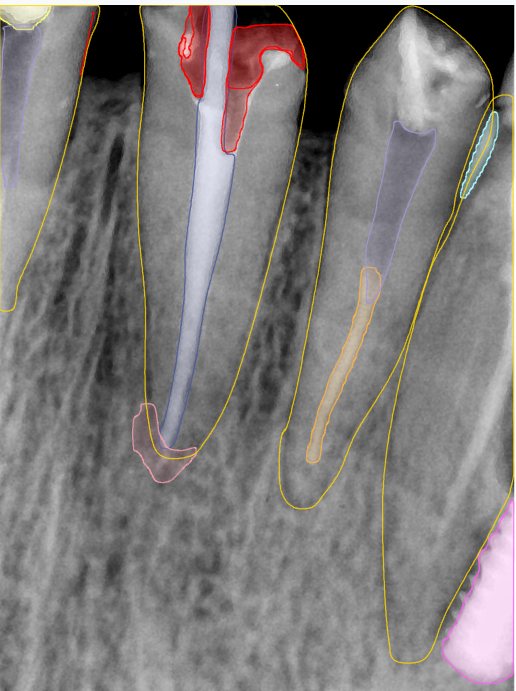 | 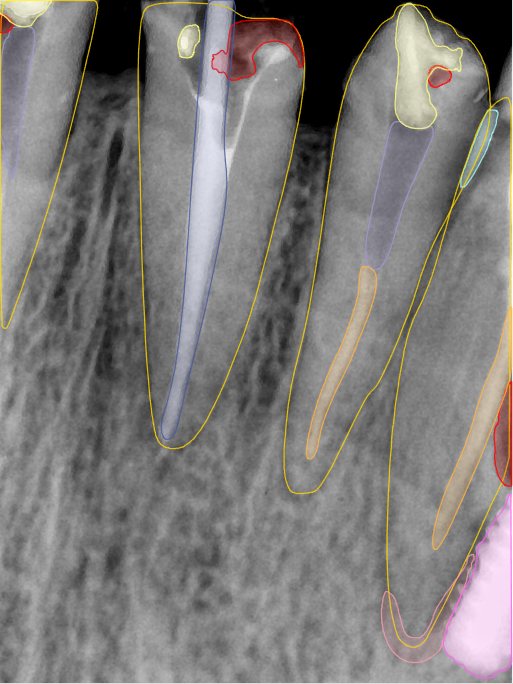 | 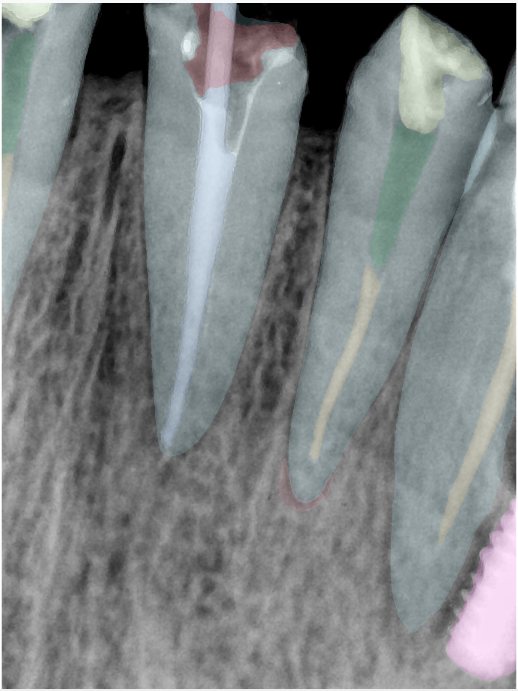 | 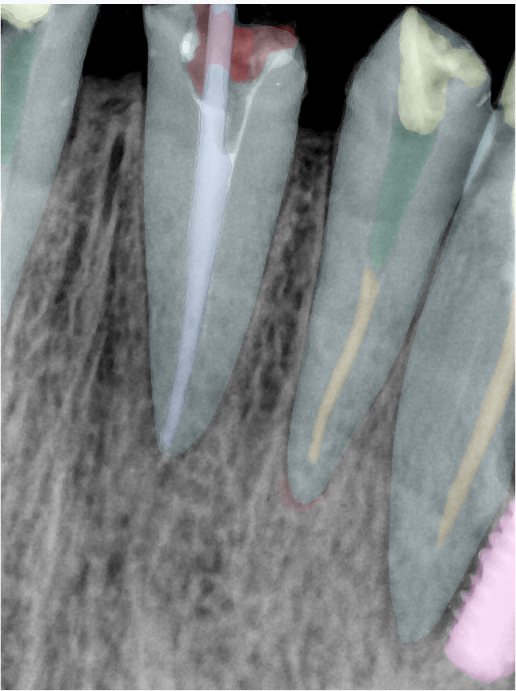 | 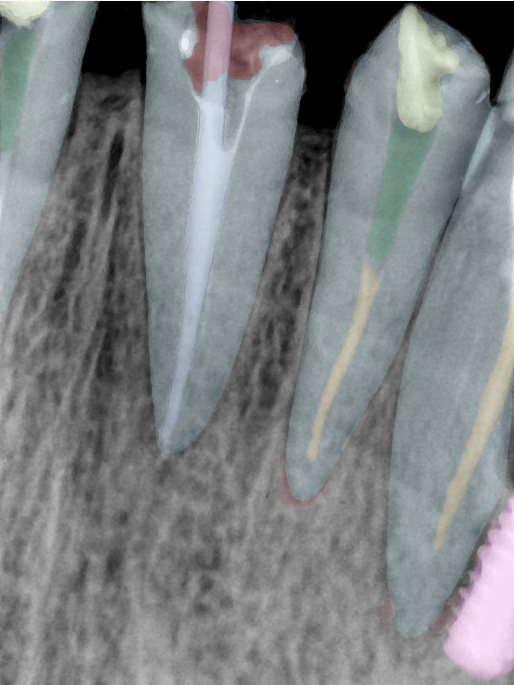 |
| 131321.jpg | 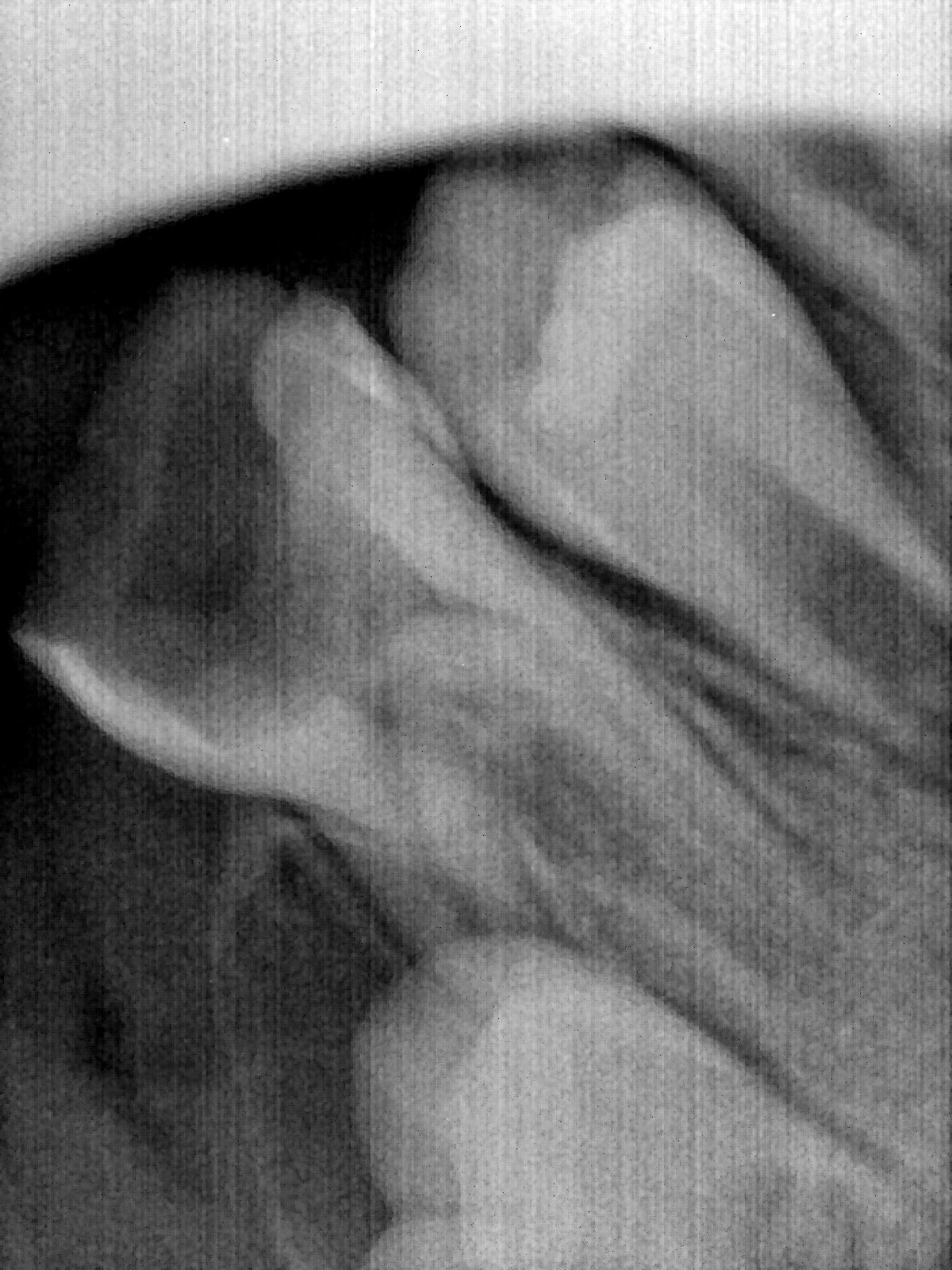 | 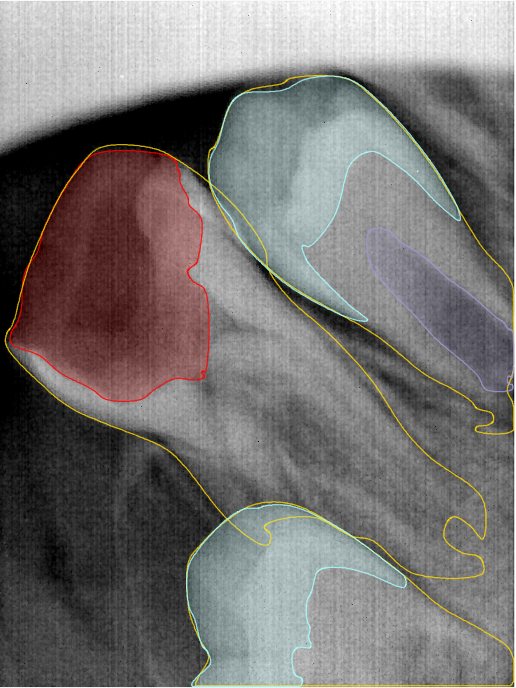 | 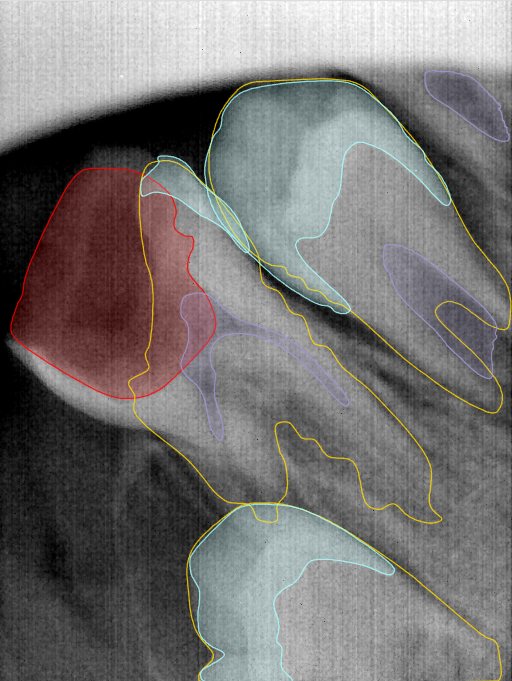 | 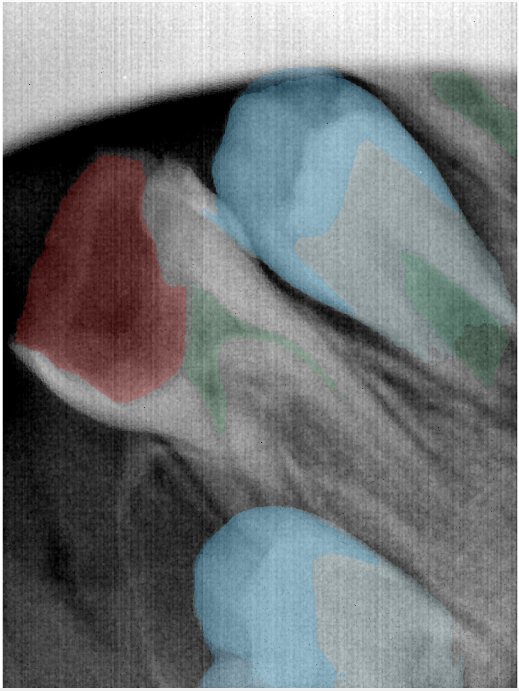 | 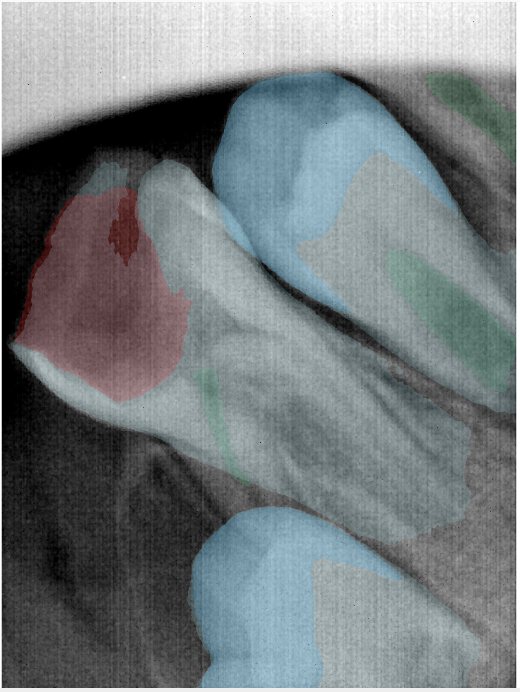 | 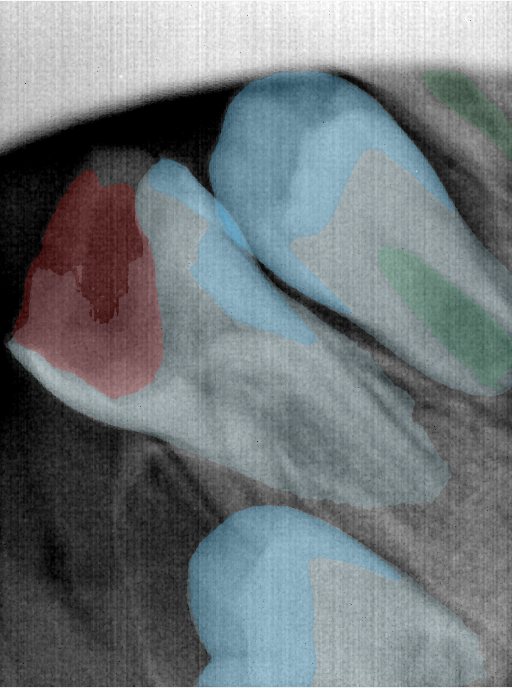 |
| 131326.jpg | 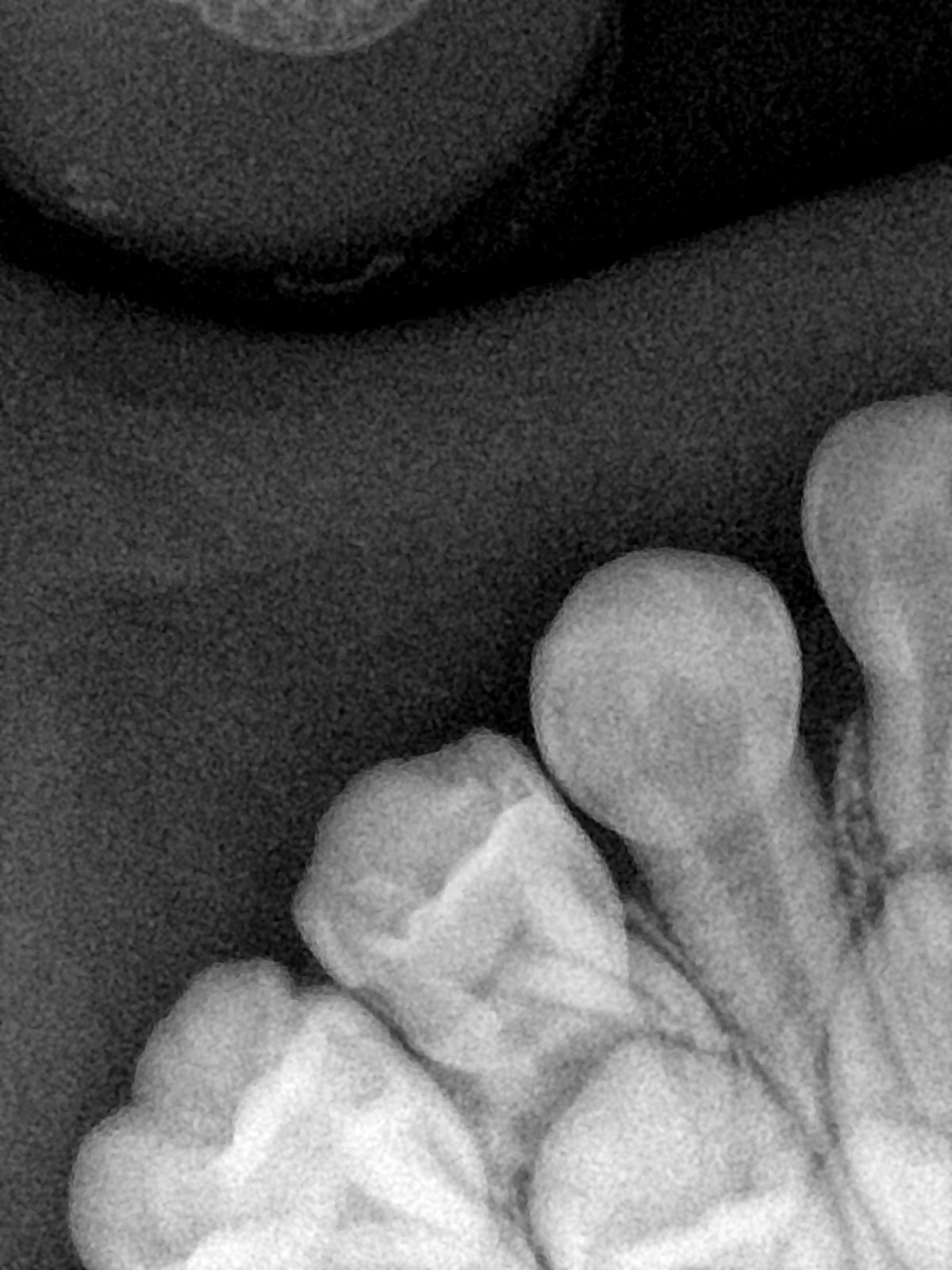 | 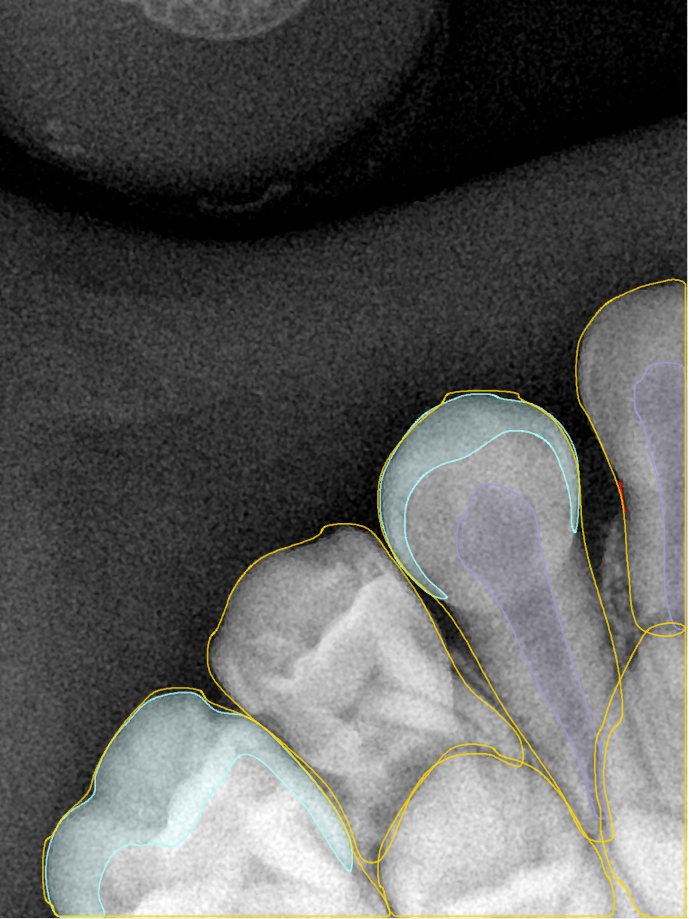 | 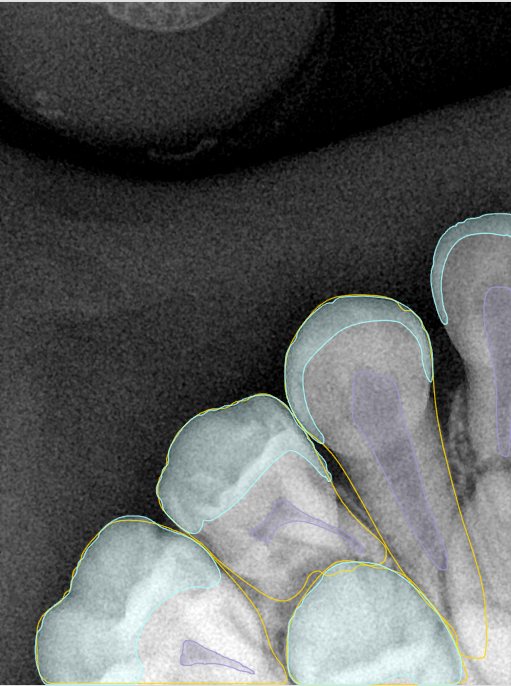 | 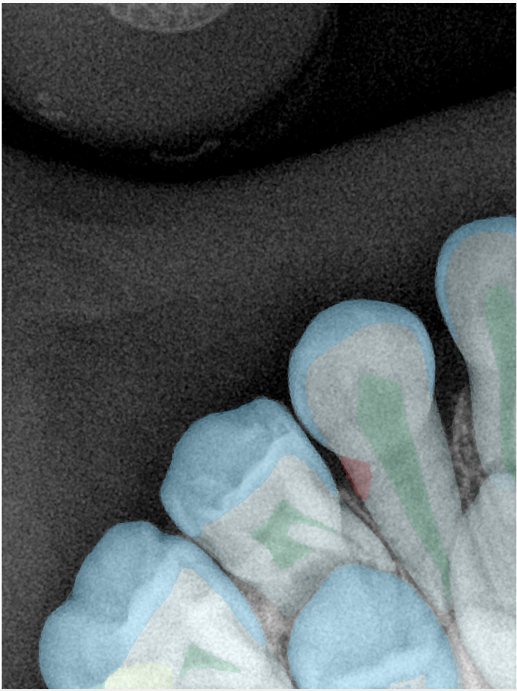 | 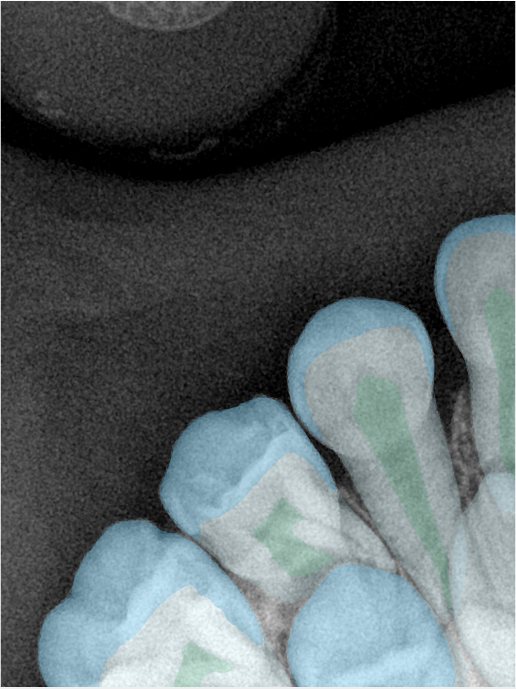 | 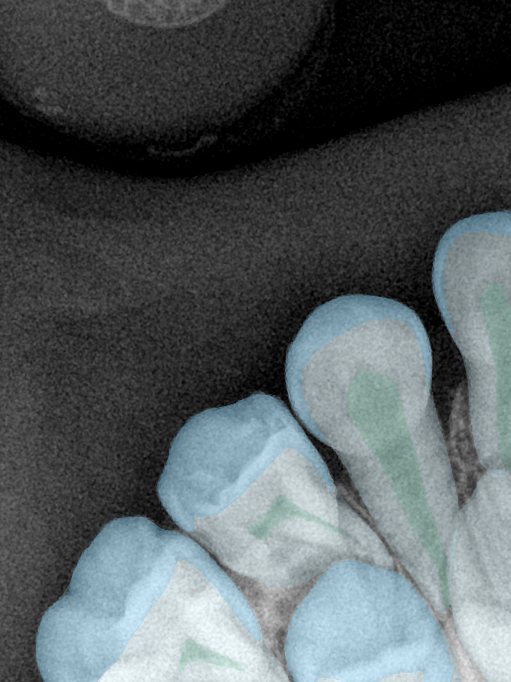 |
| 131327.jpg | 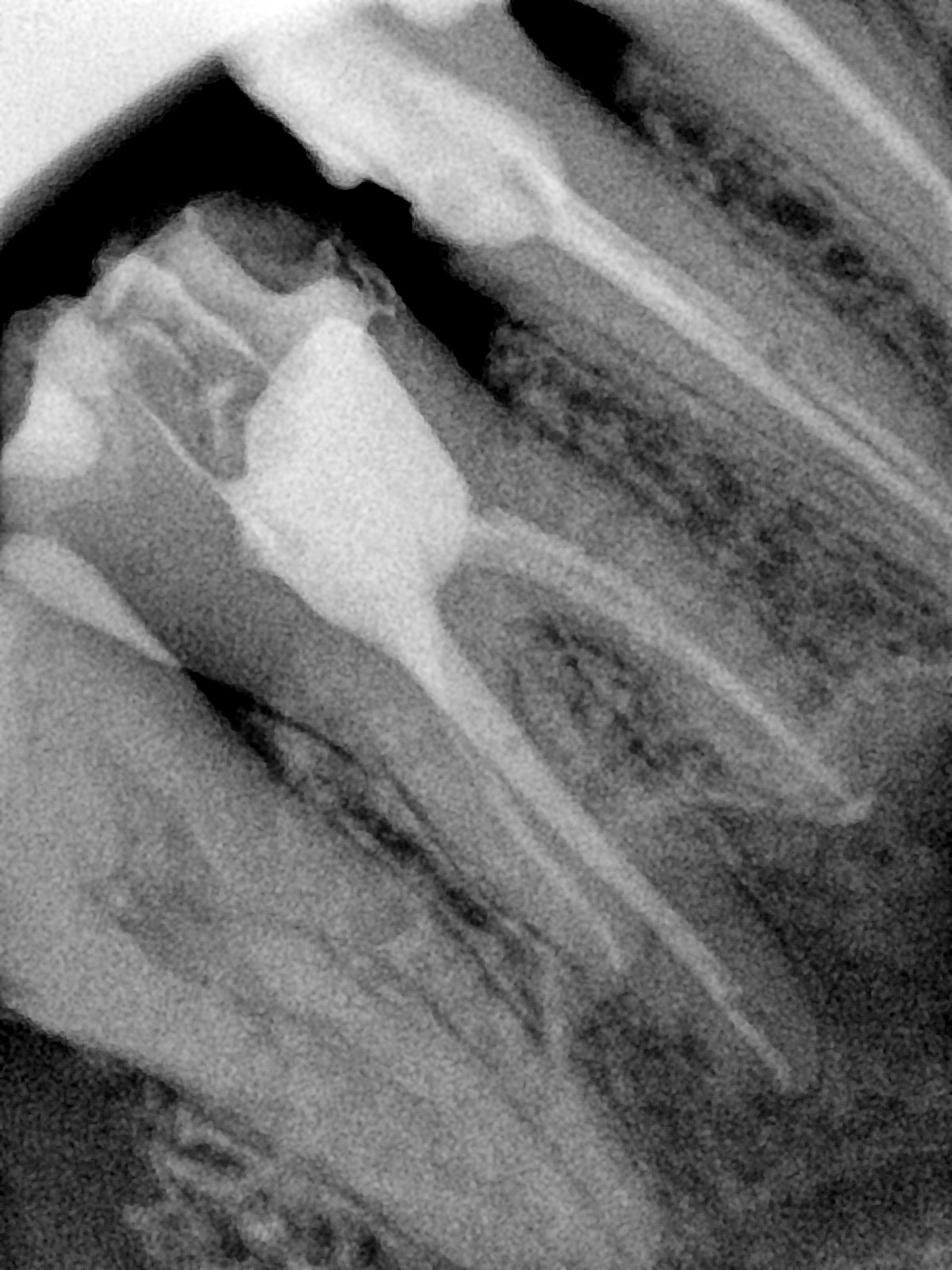 | 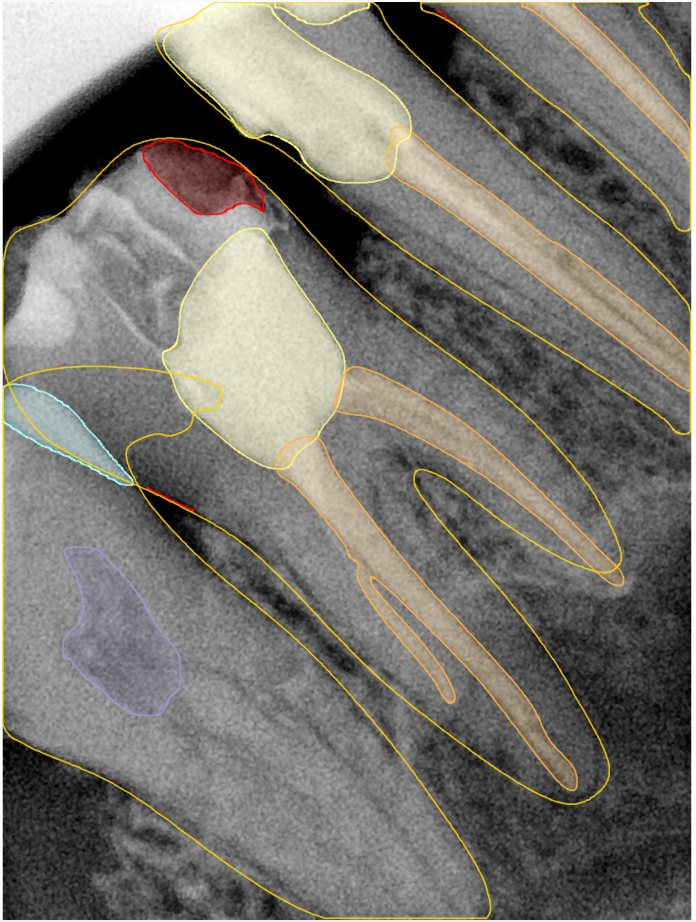 | 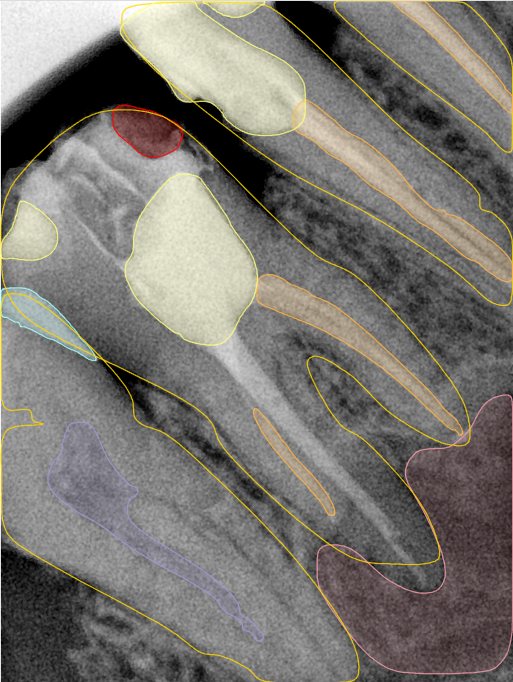 | 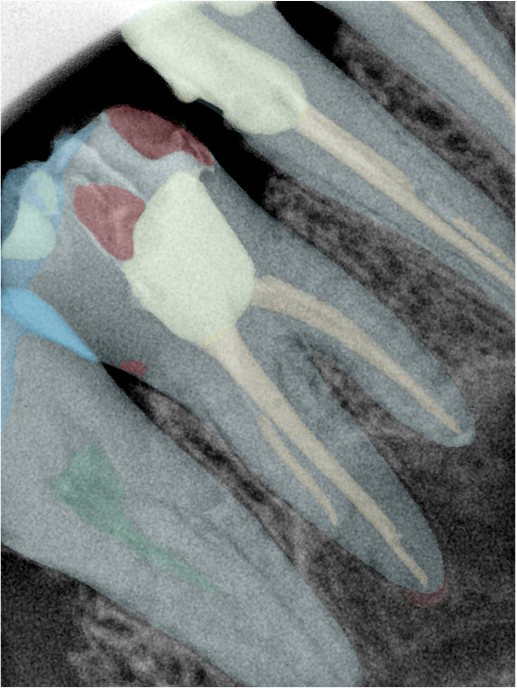 | 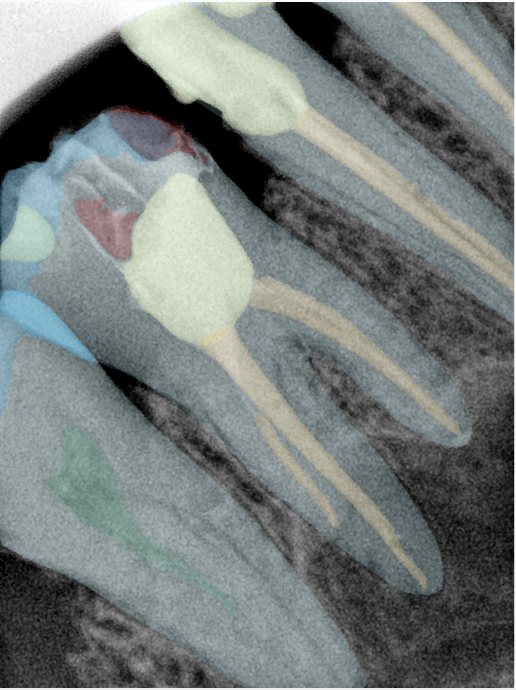 | 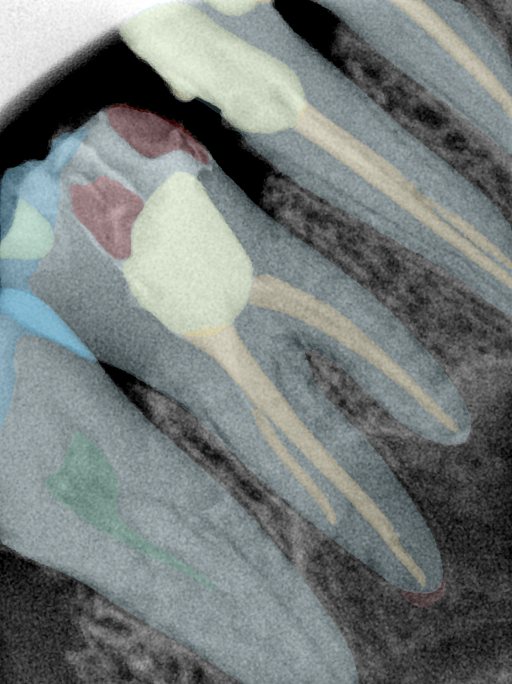 |
| 131328.jpg | 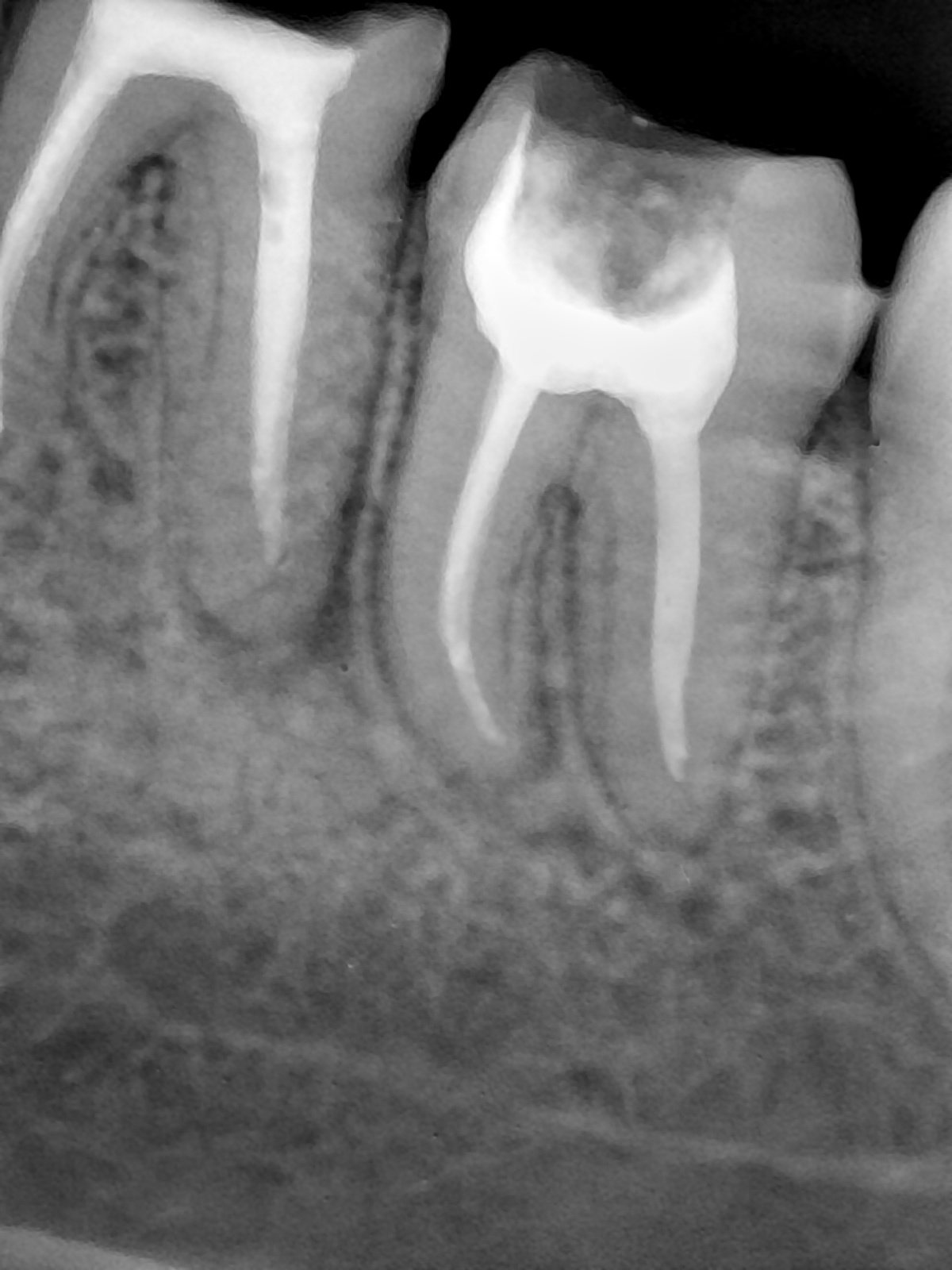 | 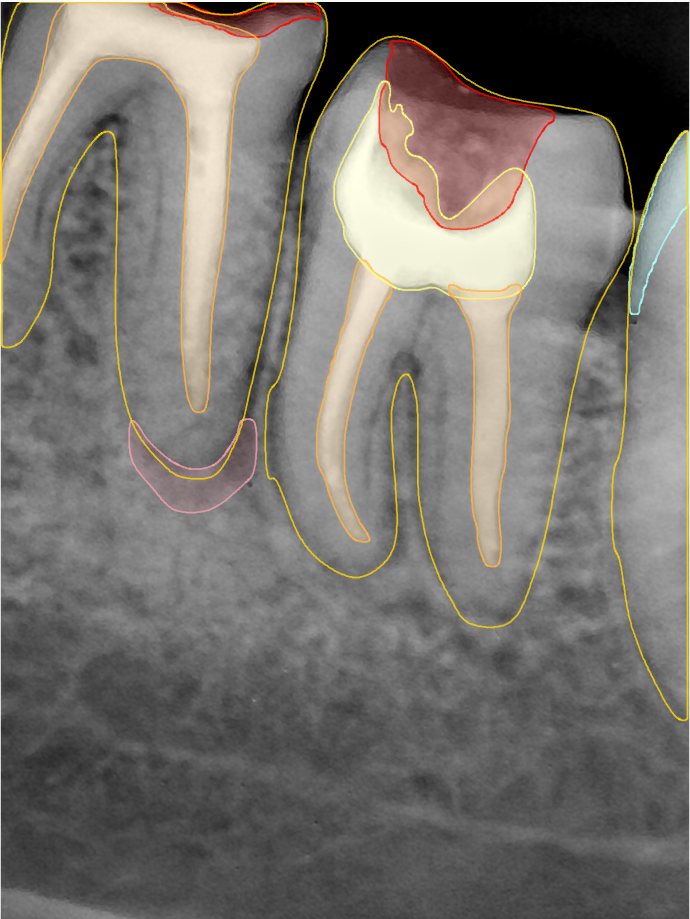 | 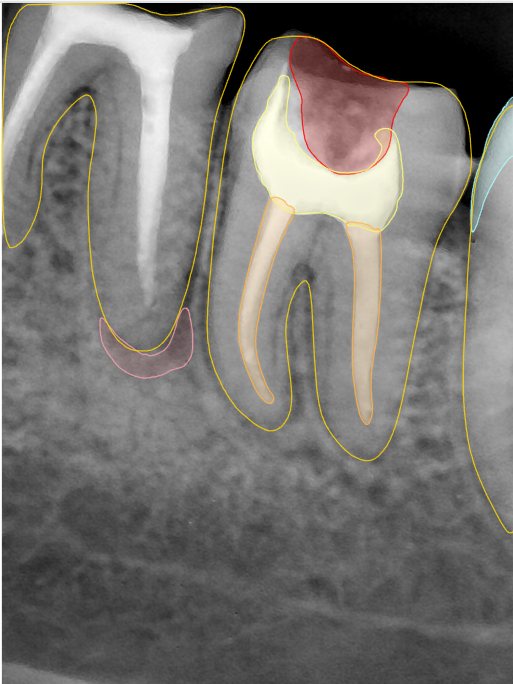 | 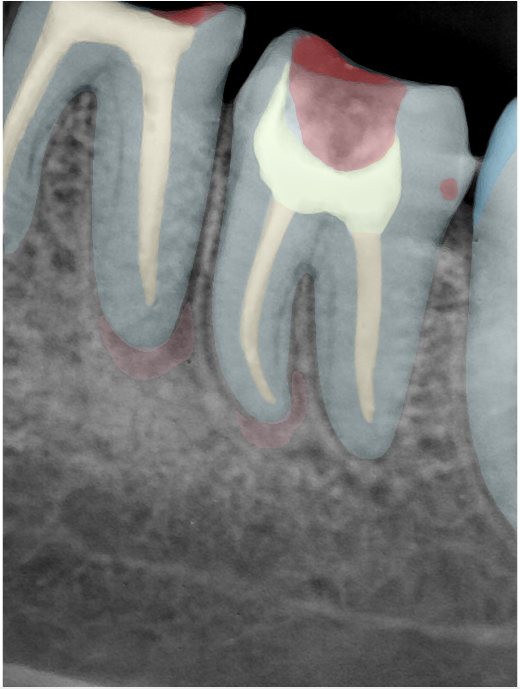 | 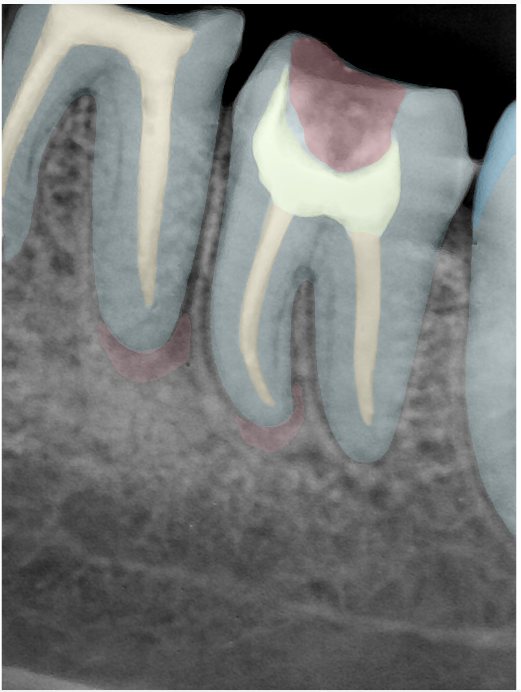 | 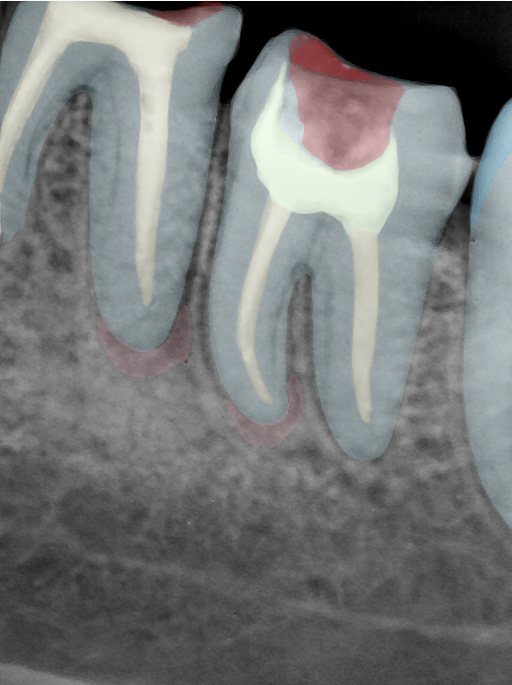 |
| 131330.jpg | 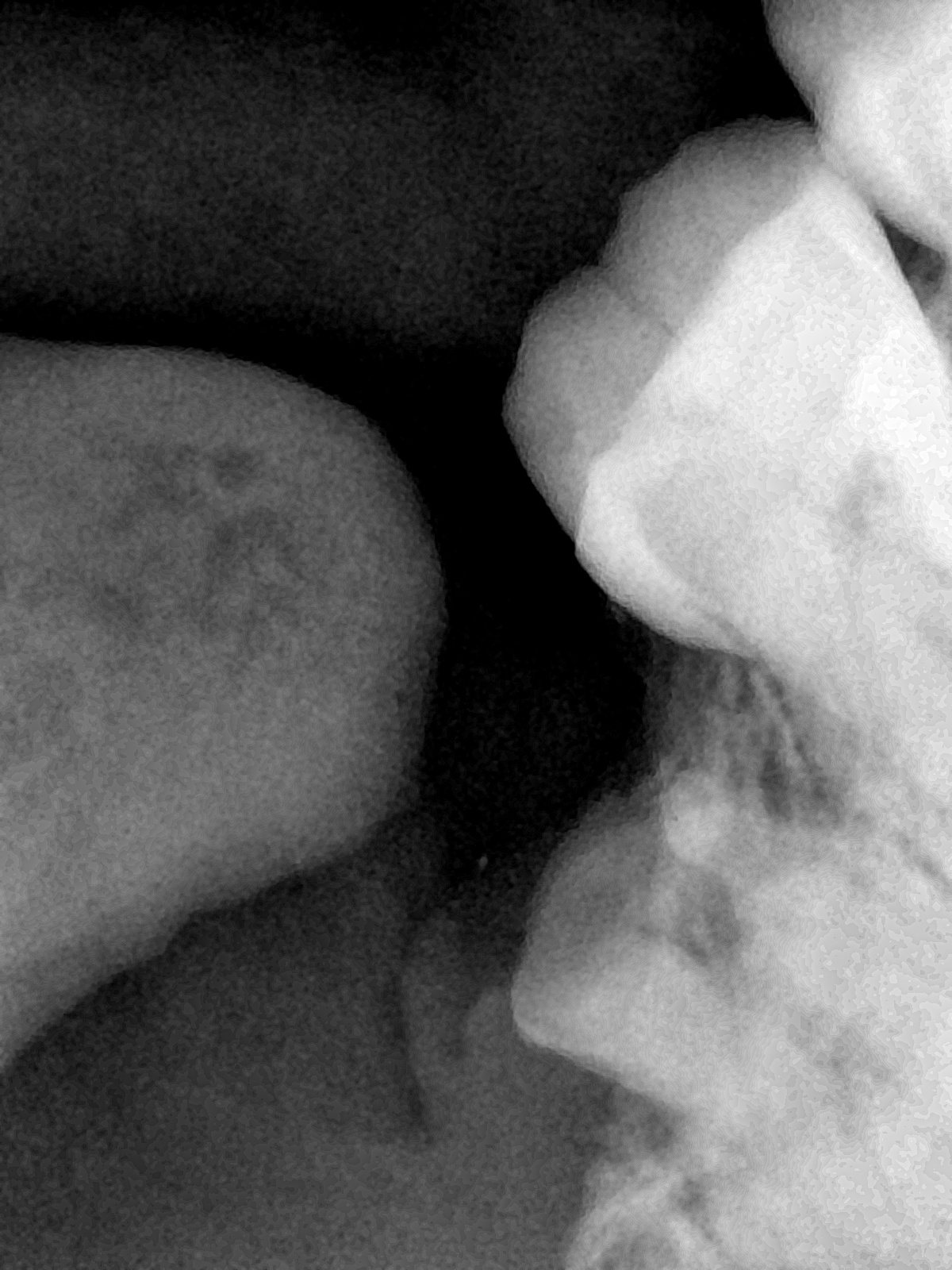 | 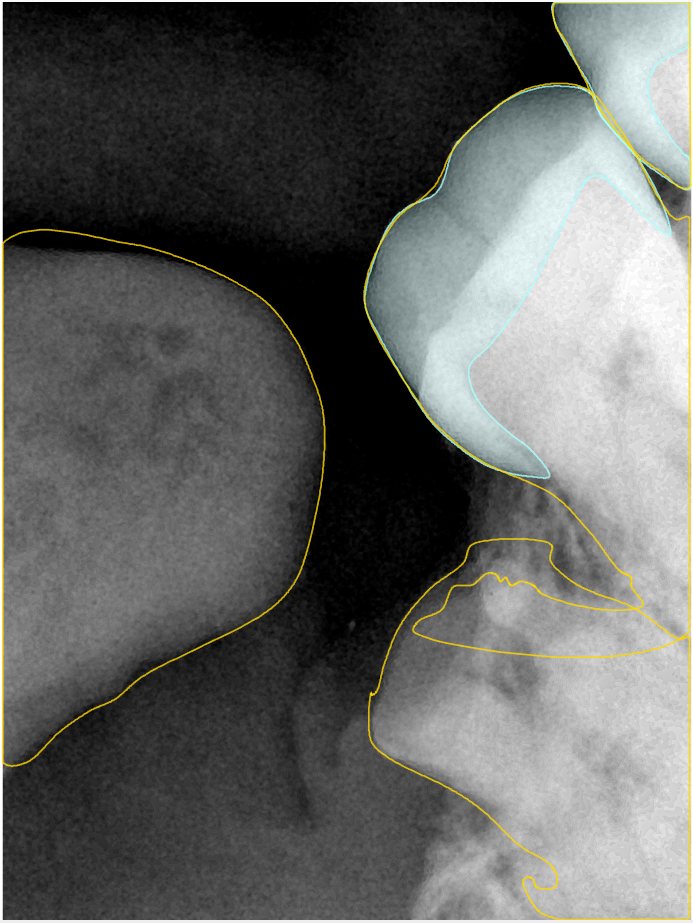 | 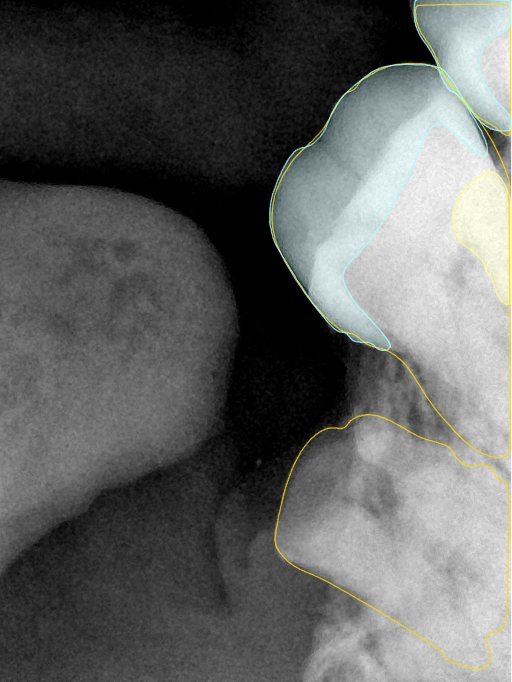 | 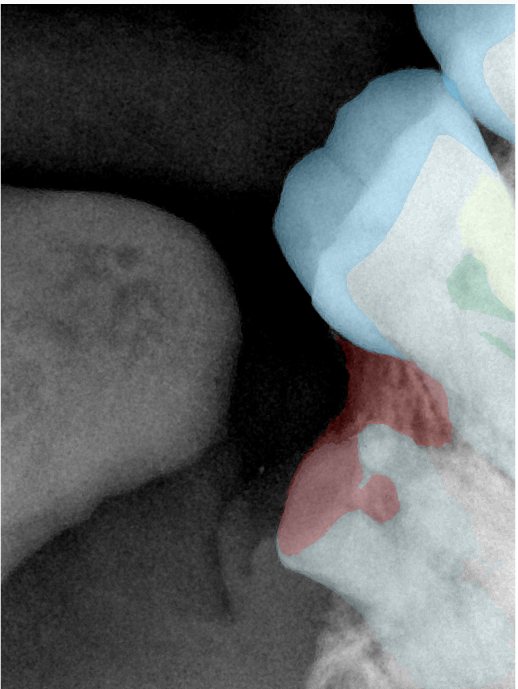 | 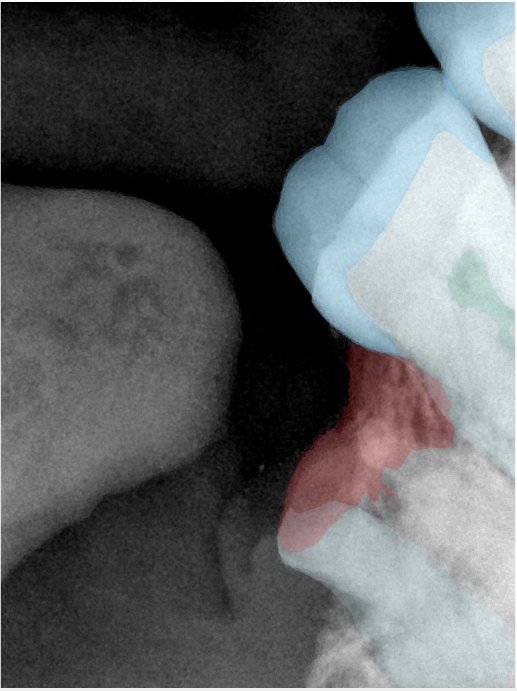 | 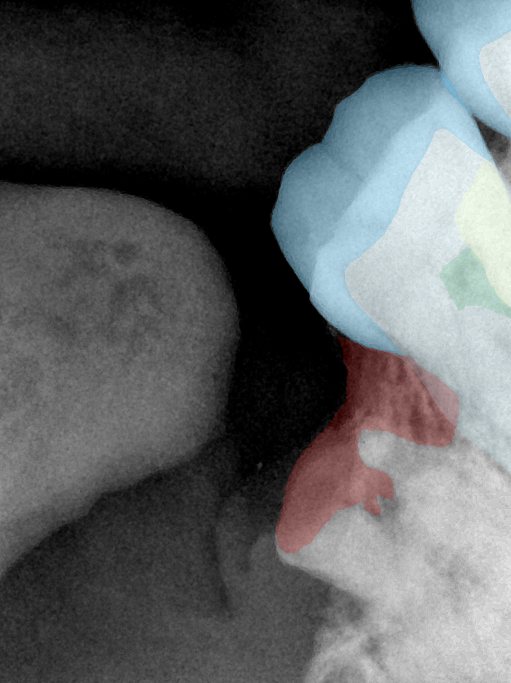 |
| 131331.jpg | 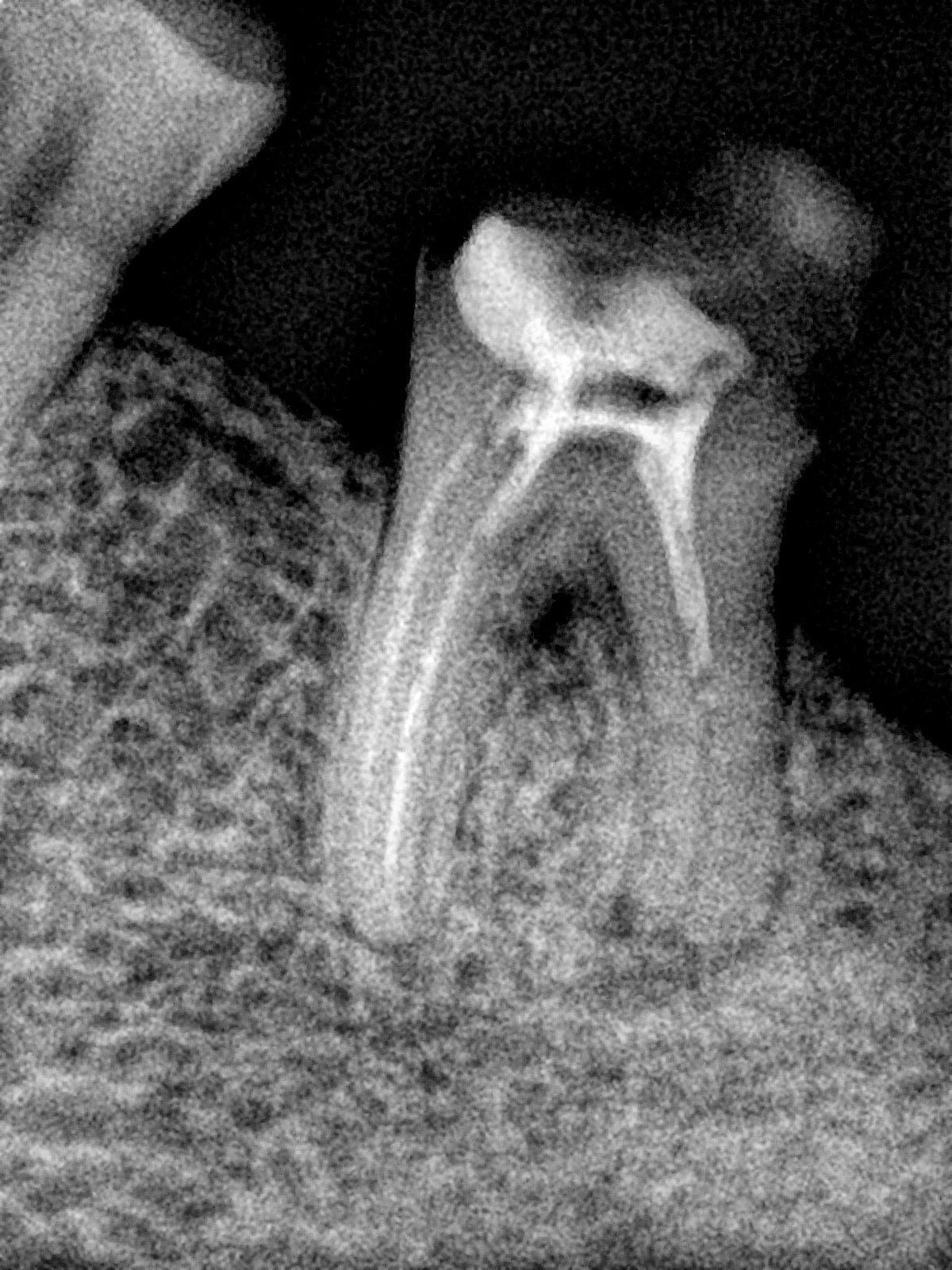 | 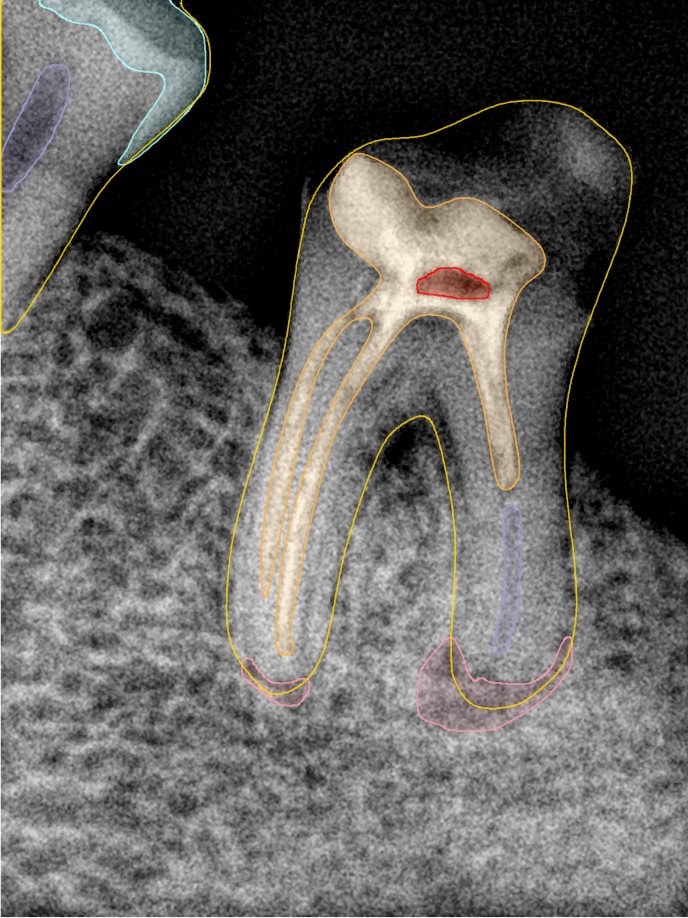 | 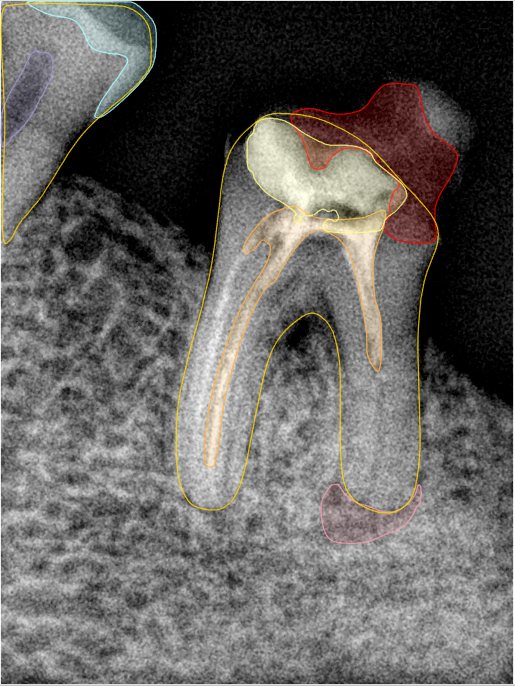 | 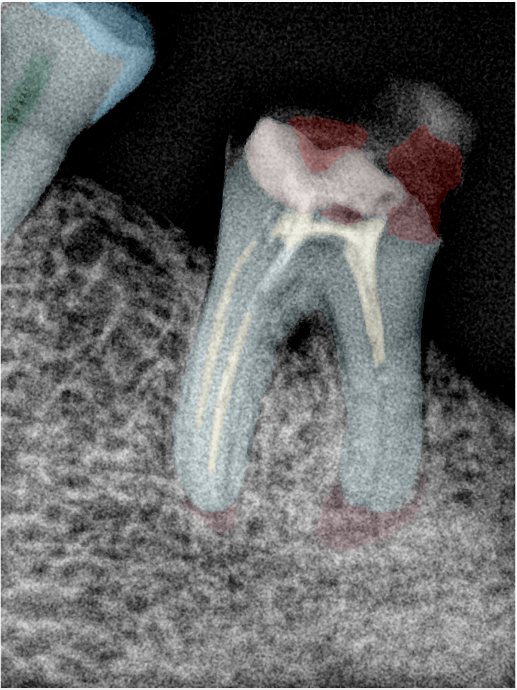 | 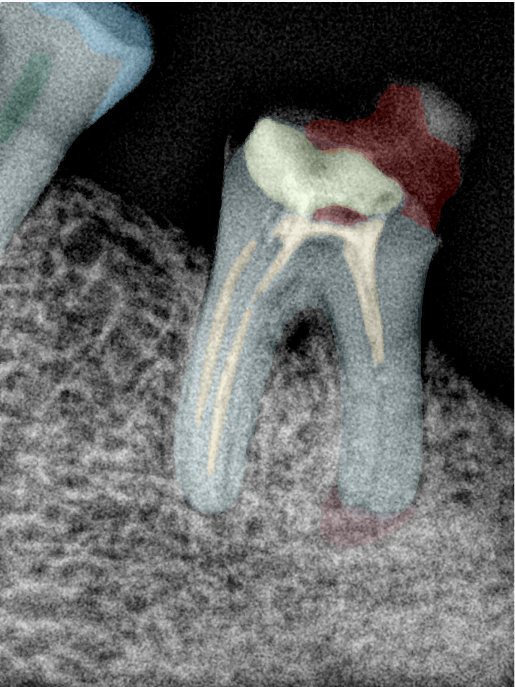 | 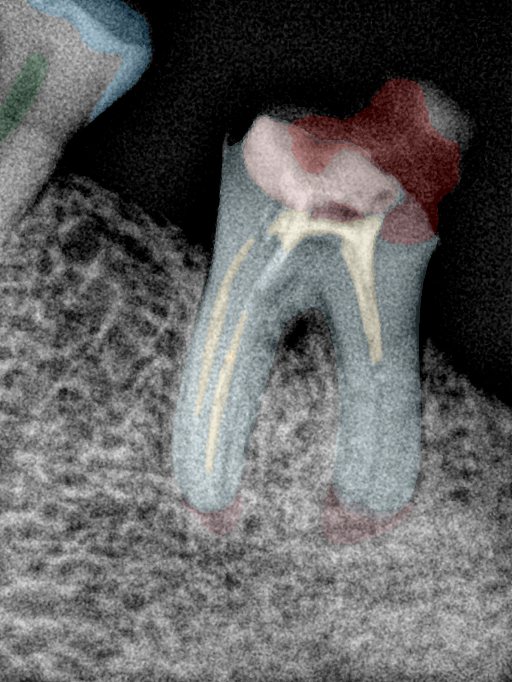 |
| 131332.jpg | 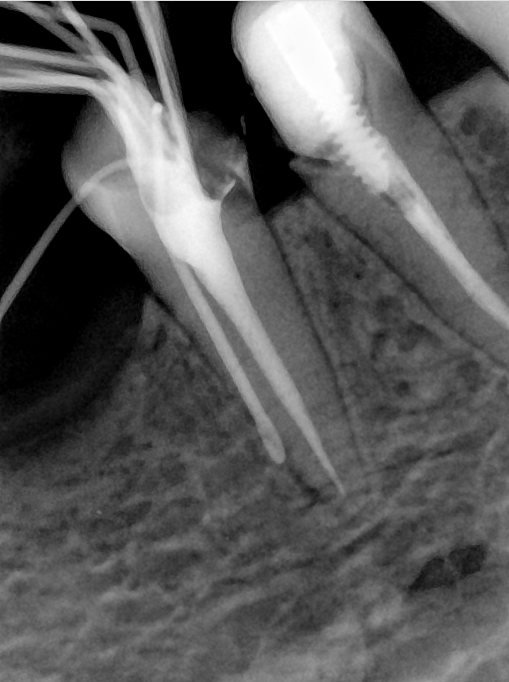 | 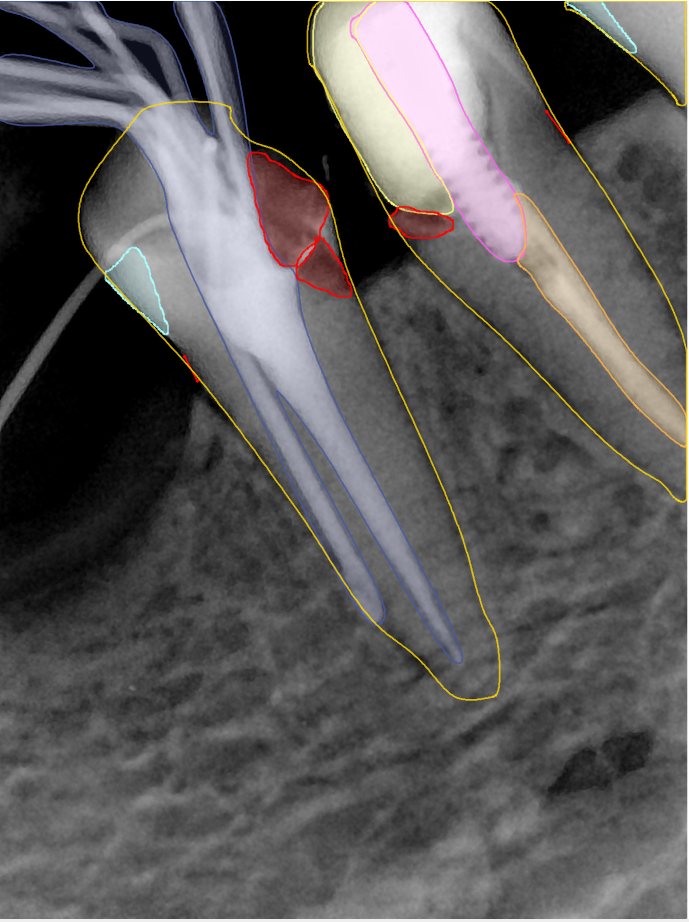 | 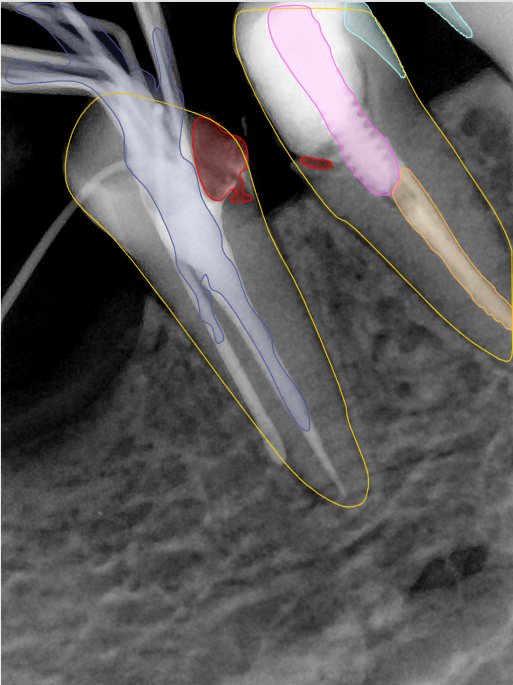 | 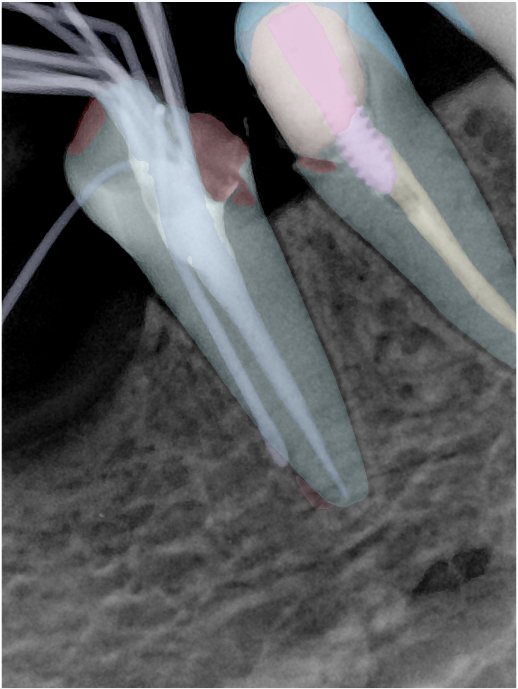 | 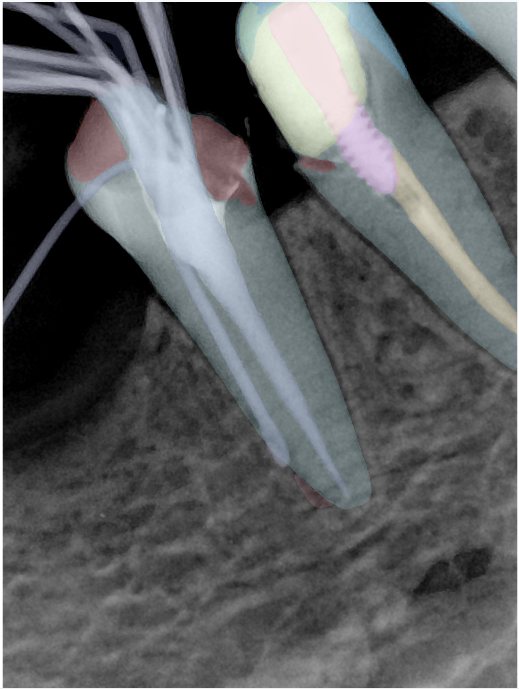 | 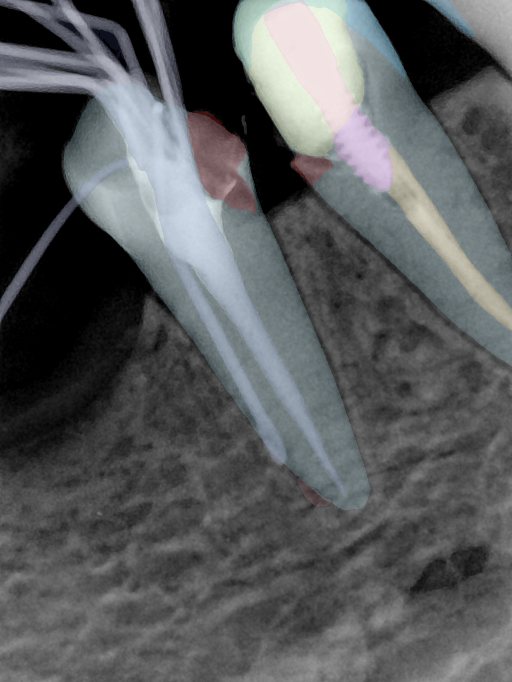 |
| 131333.jpg |  | 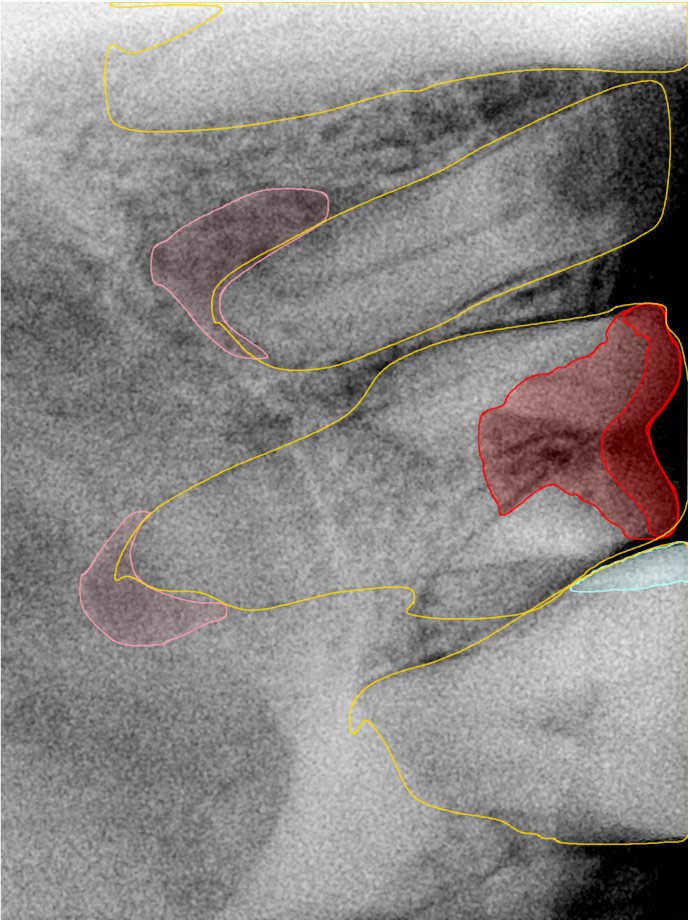 | 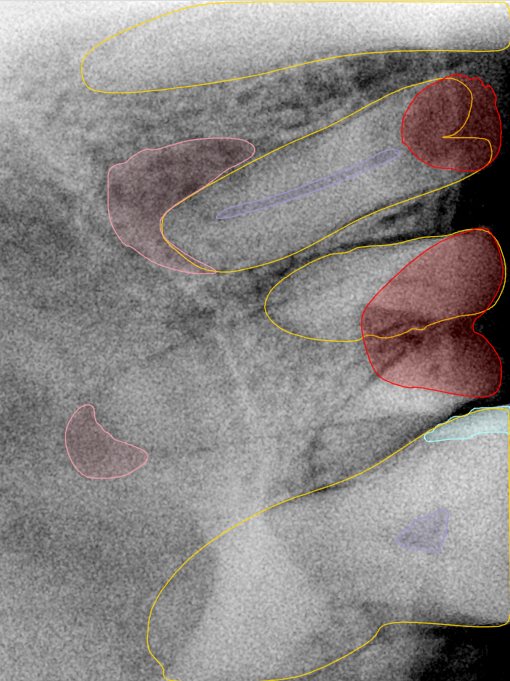 | 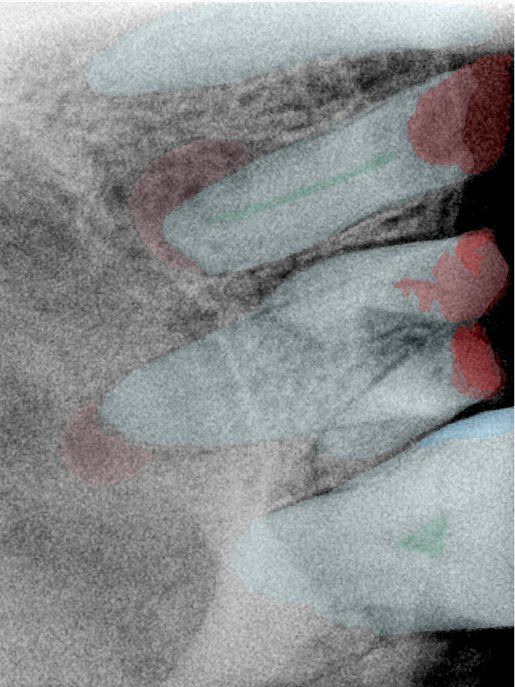 | 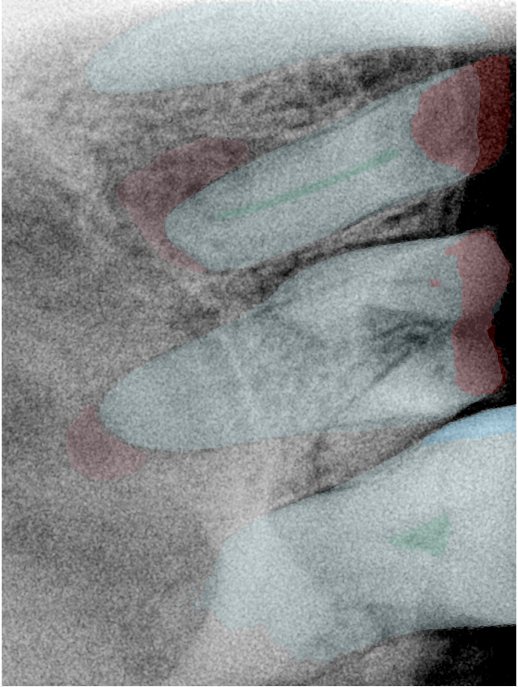 | 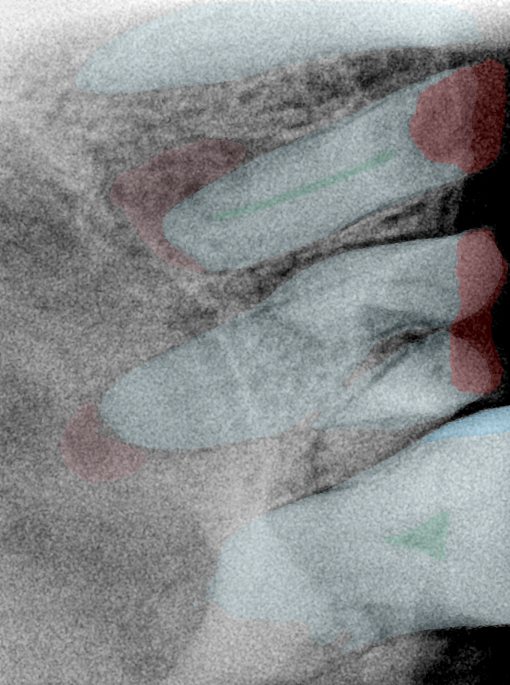 |
| 131334.jpg | 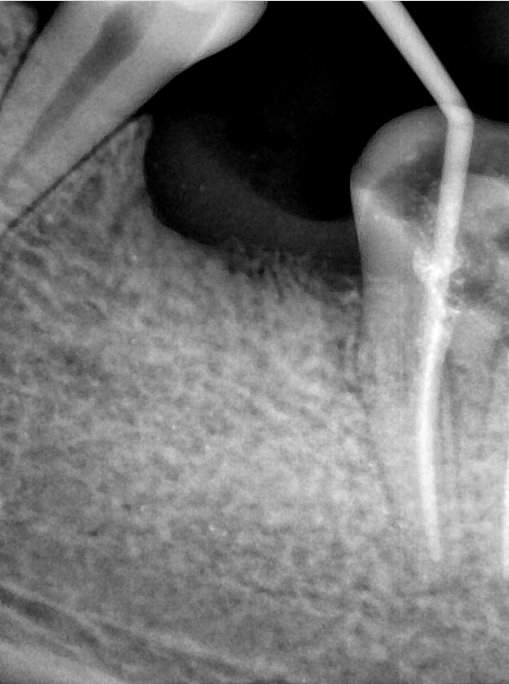 | 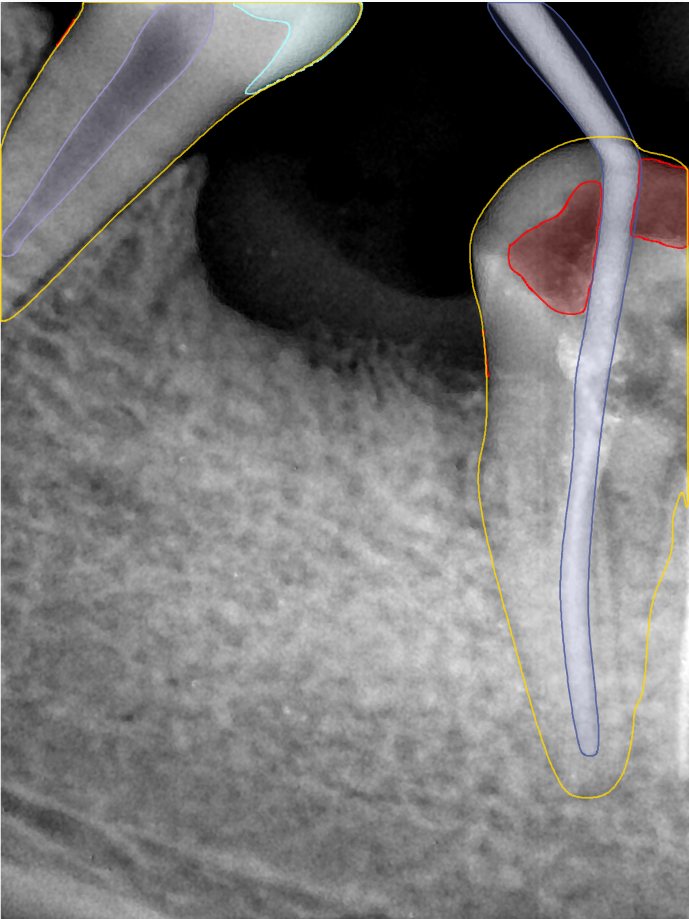 | 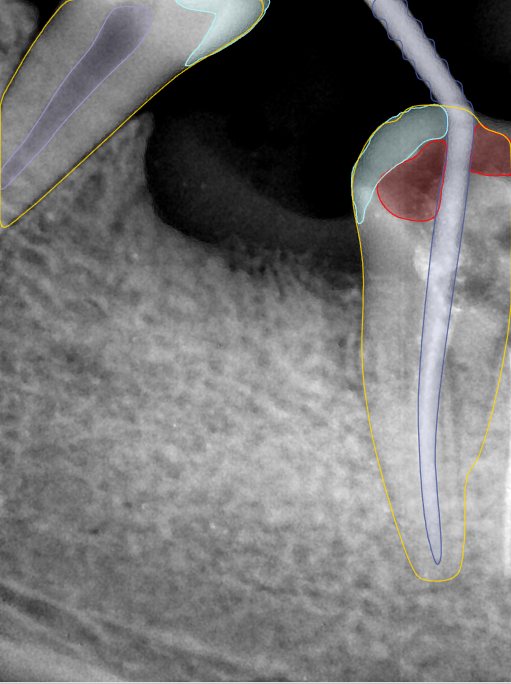 | 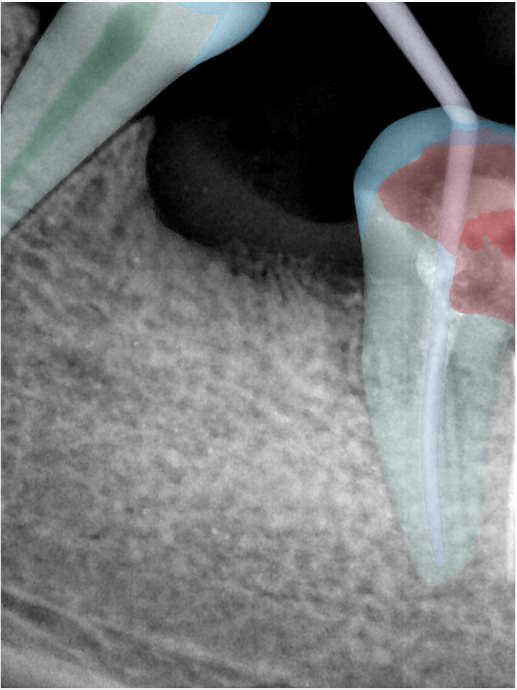 | 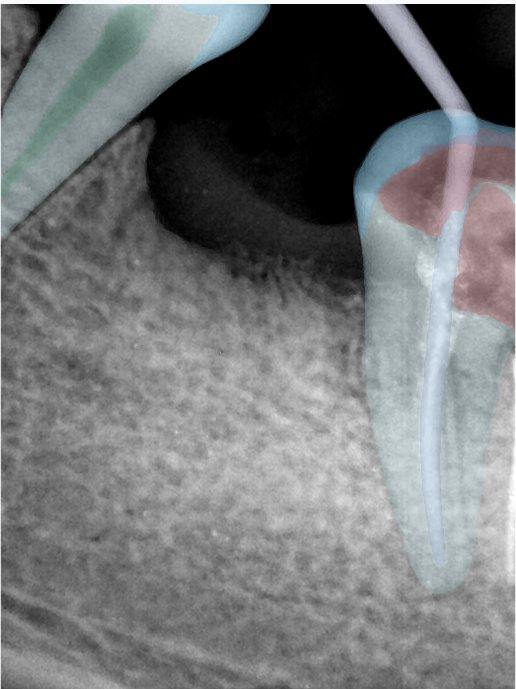 | 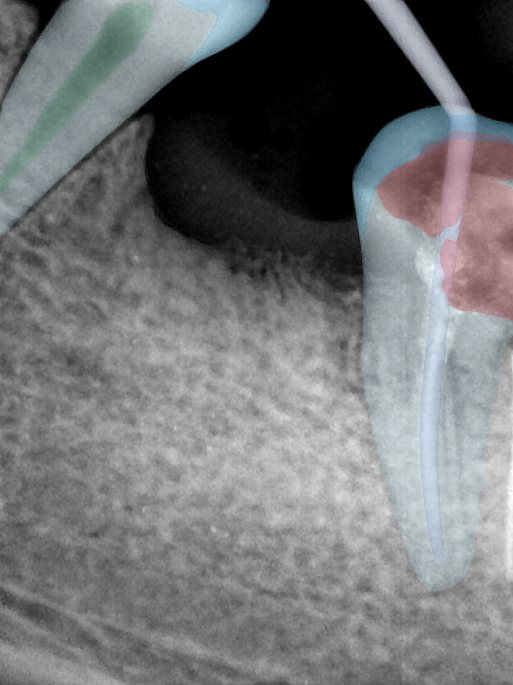 |
| 131336.jpg | 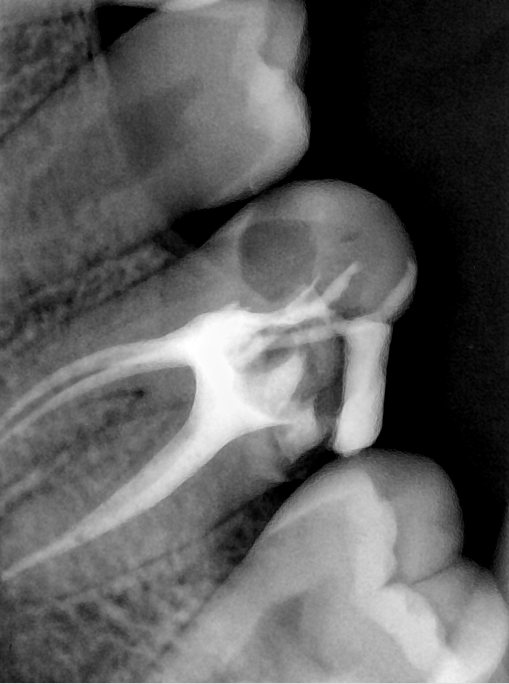 | 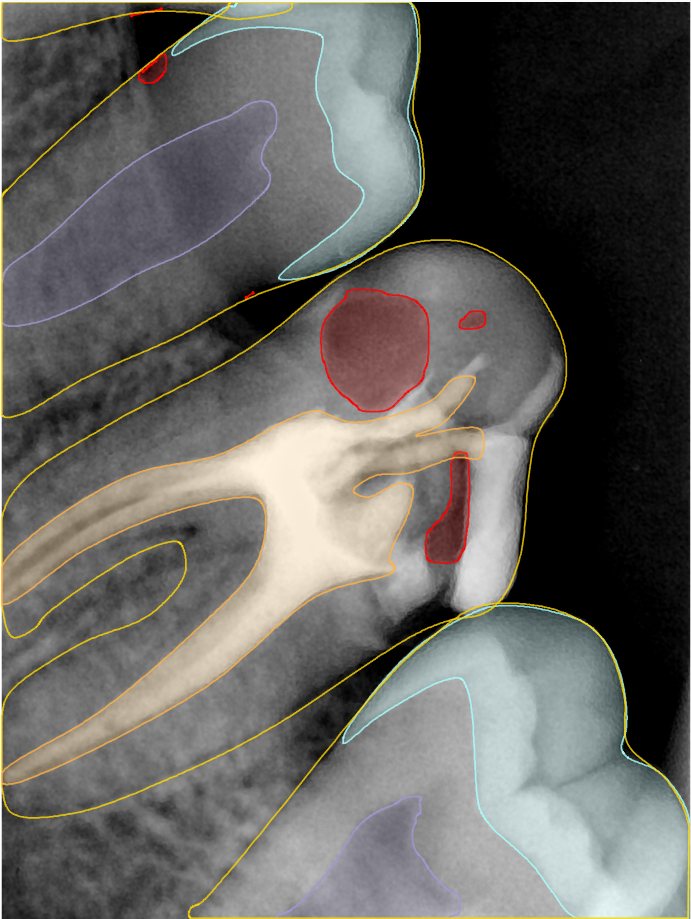 | 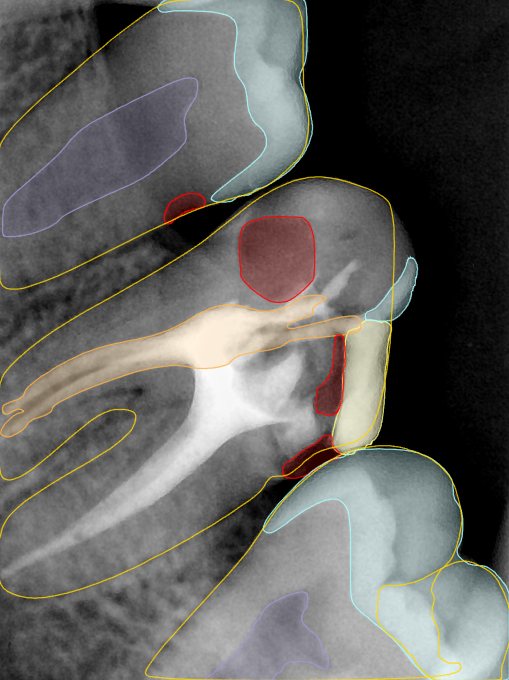 | 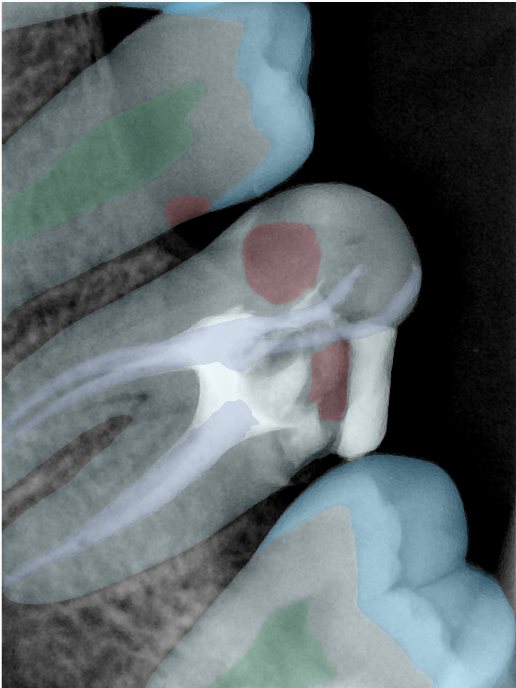 | 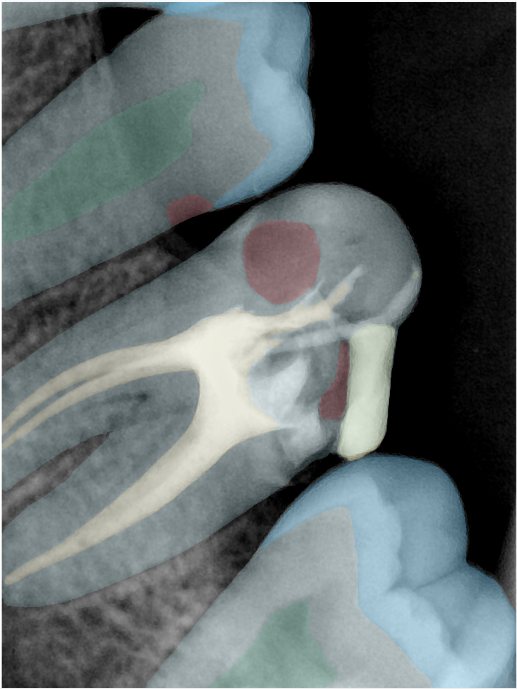 | 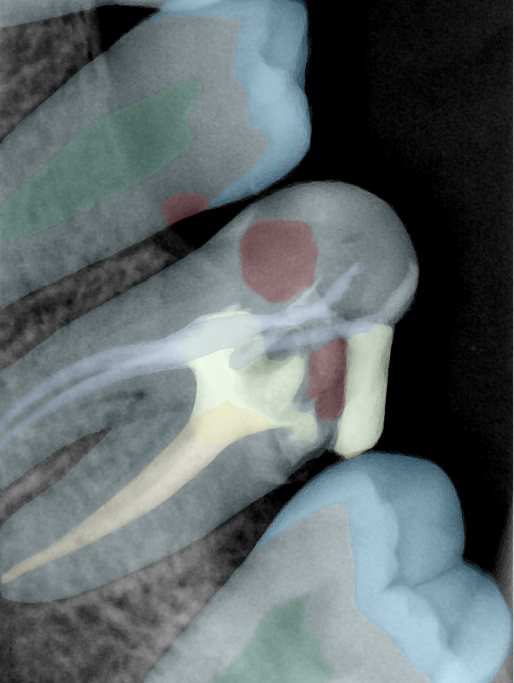 |
| 131337.jpg | 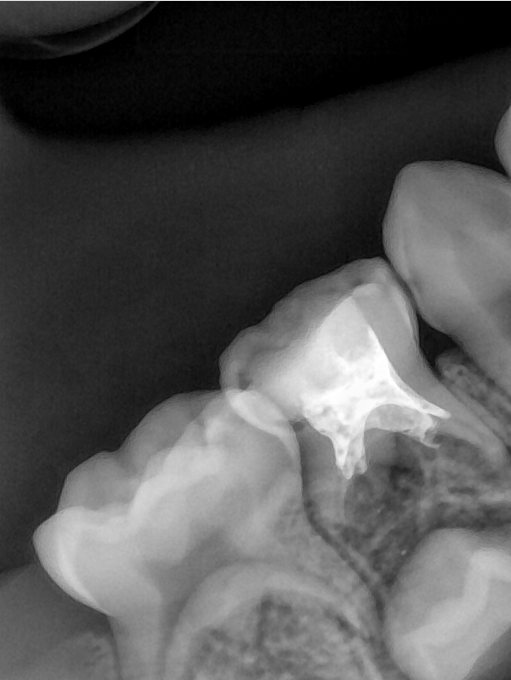 | 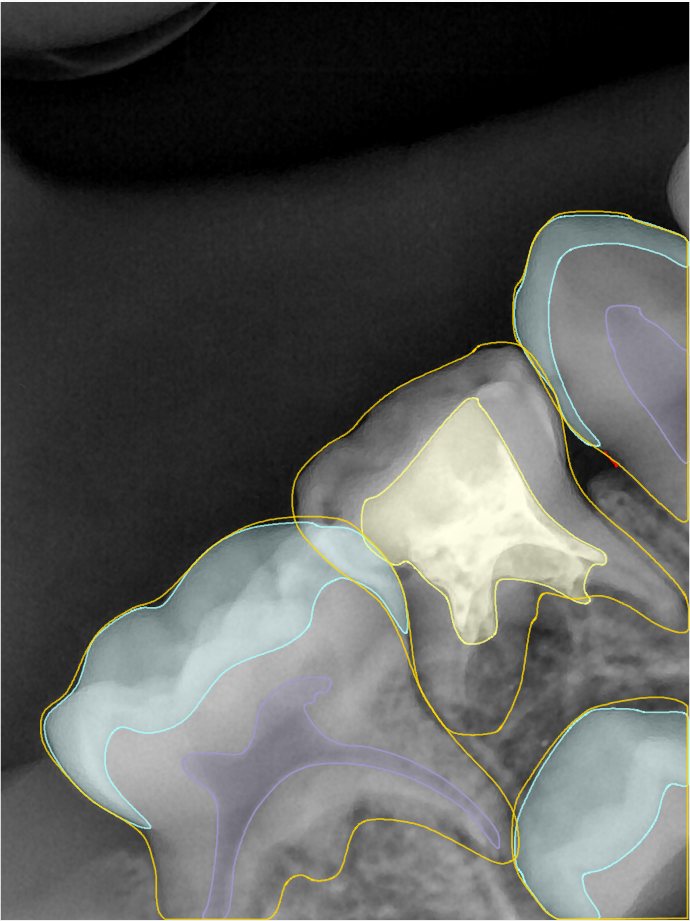 | 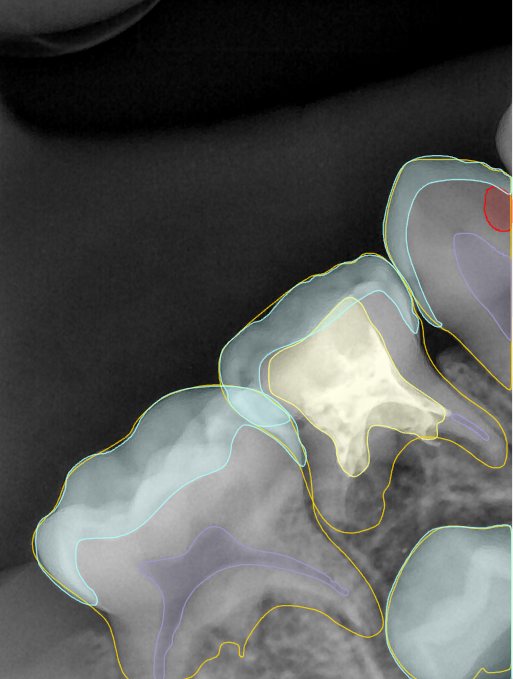 | 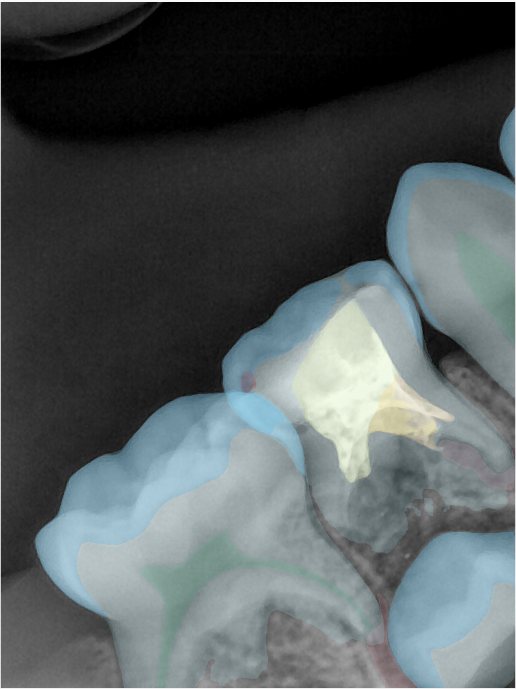 | 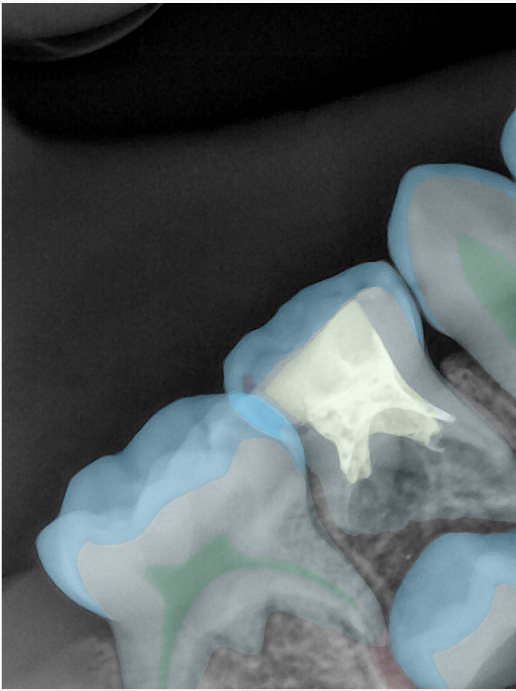 | 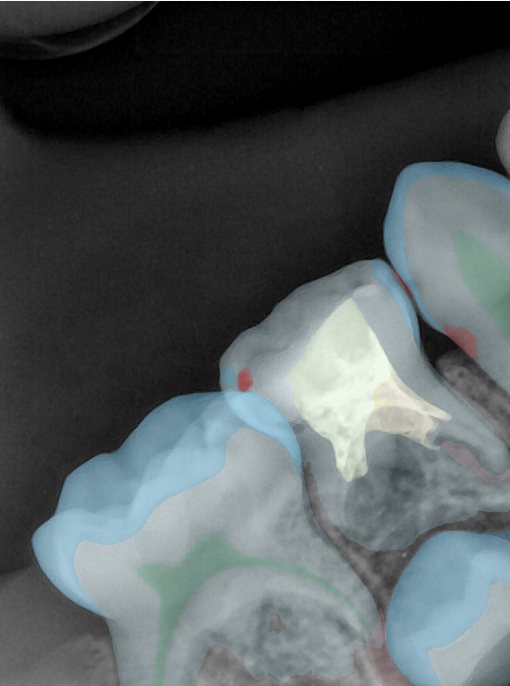 |
| 131338.jpg | 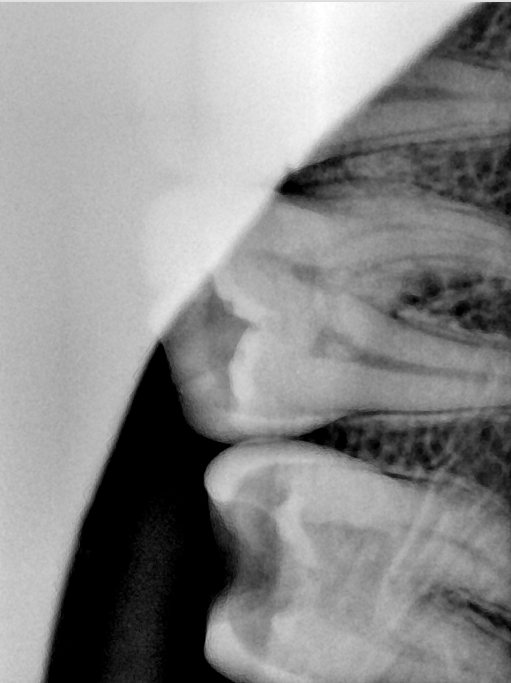 | 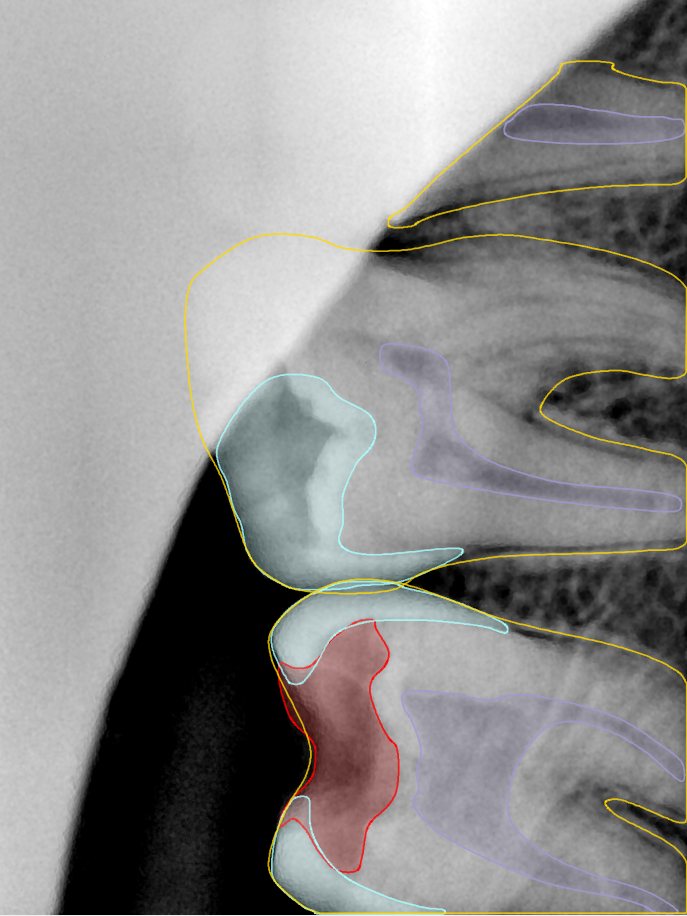 | 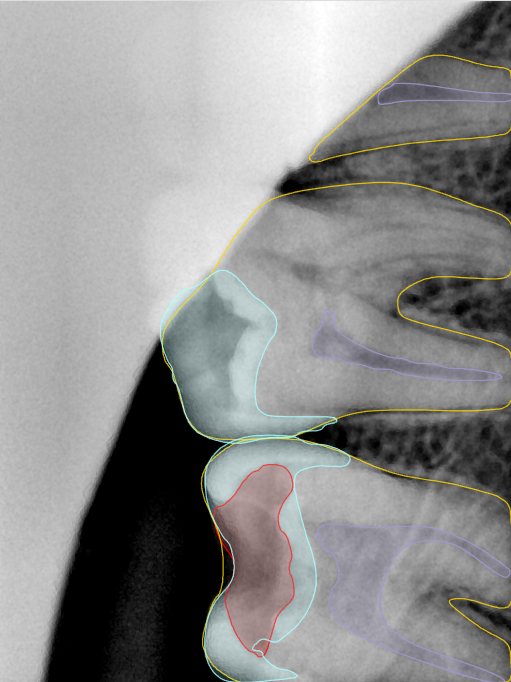 | 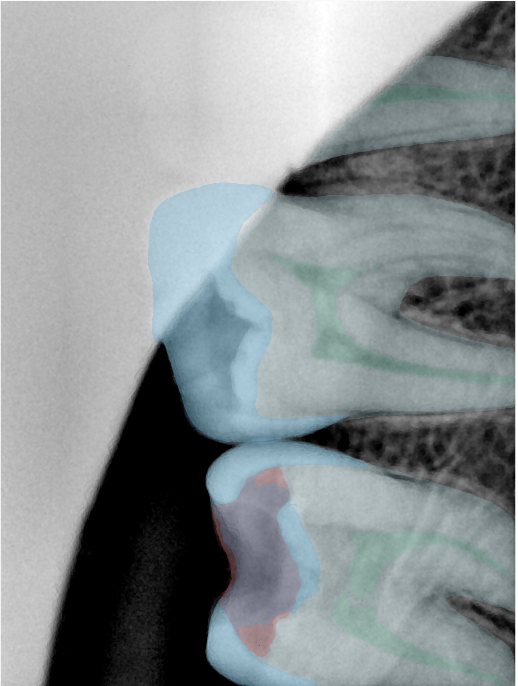 | 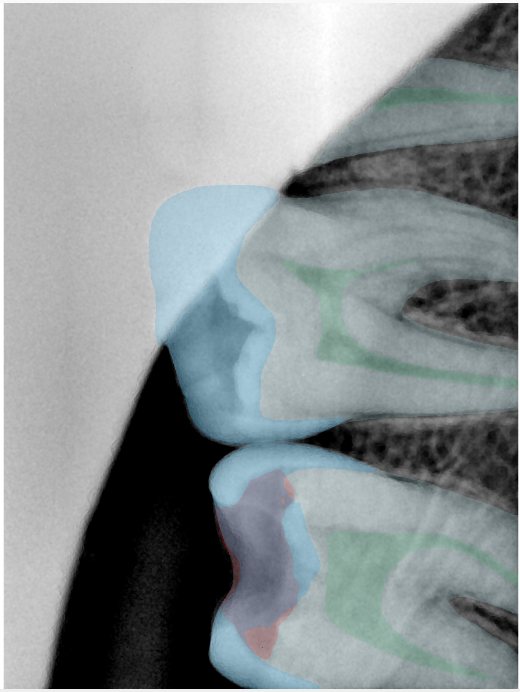 | 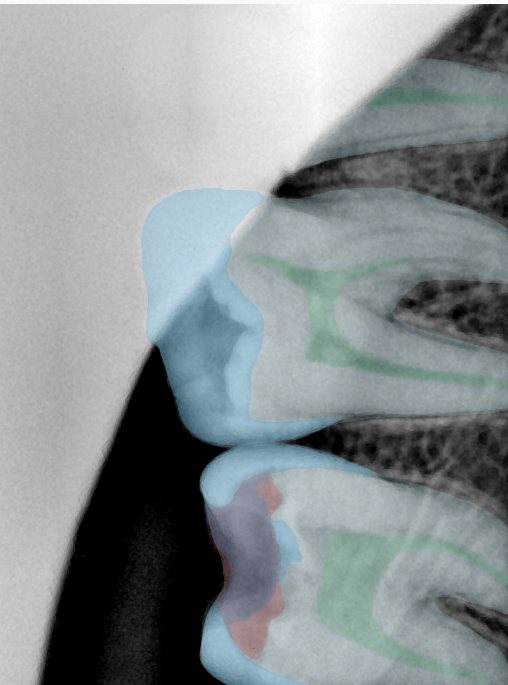 |
| 131339.jpg | 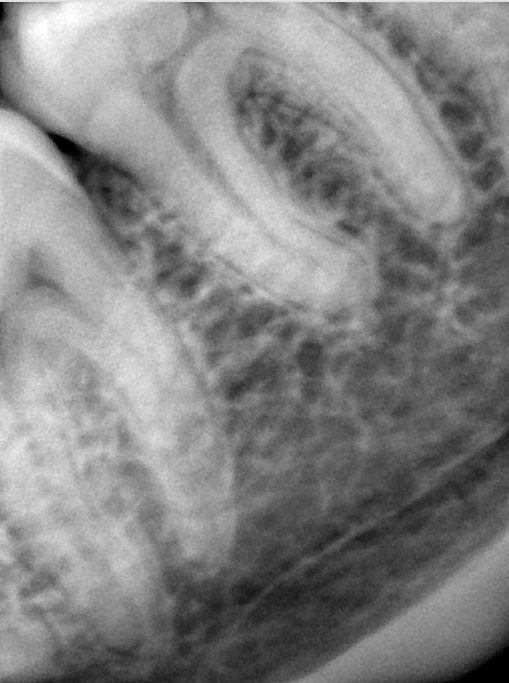 | 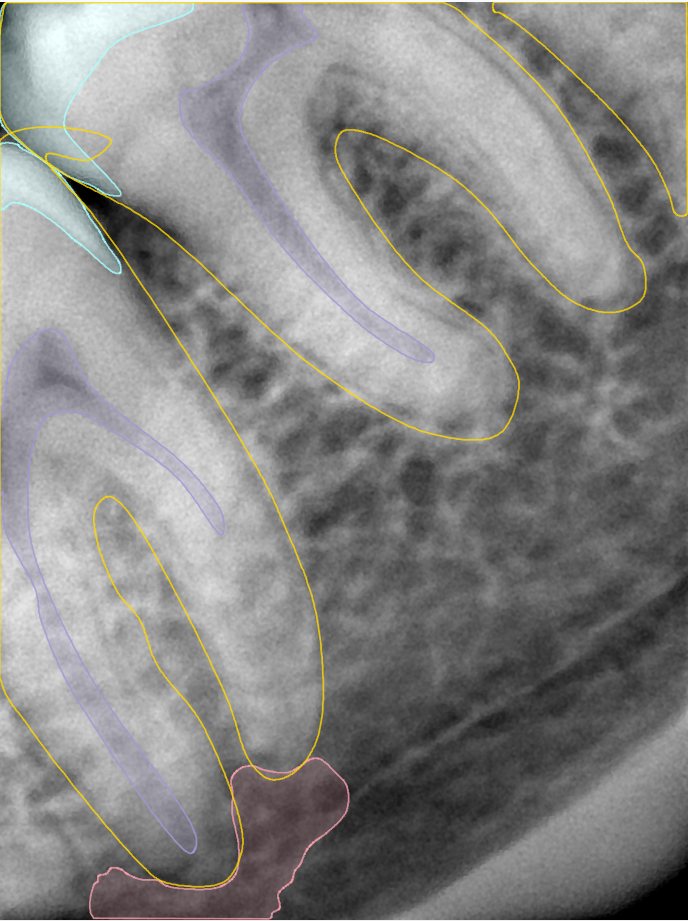 | 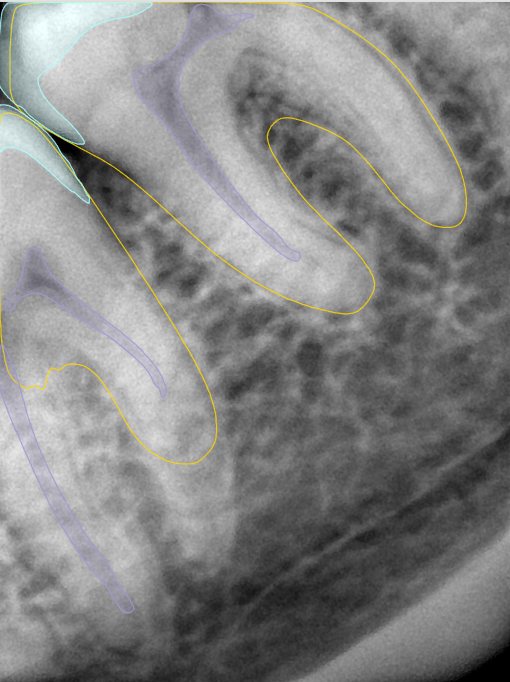 | 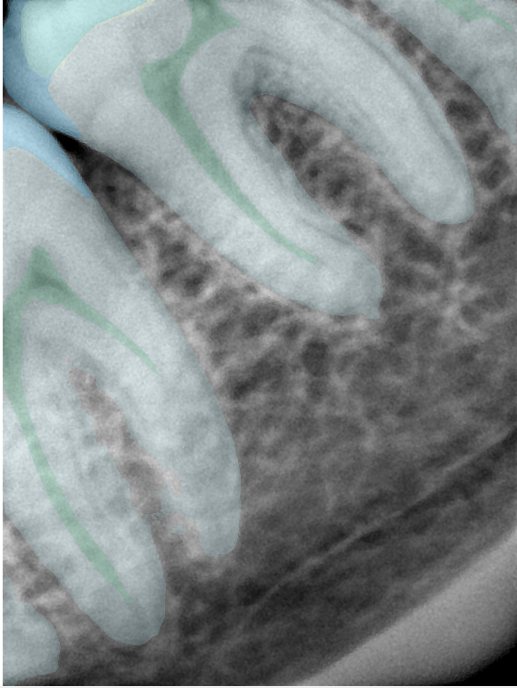 | 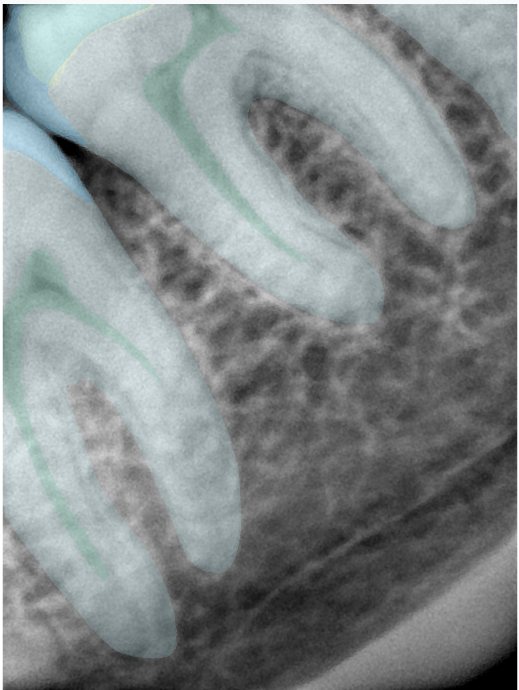 | 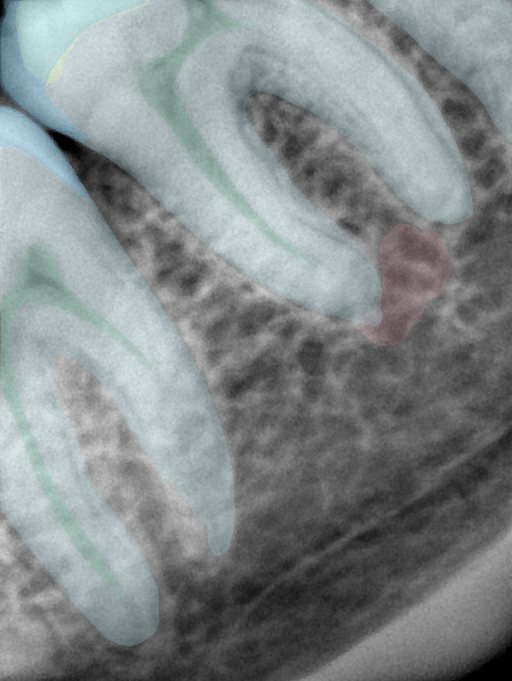 |
| 131340.jpg | 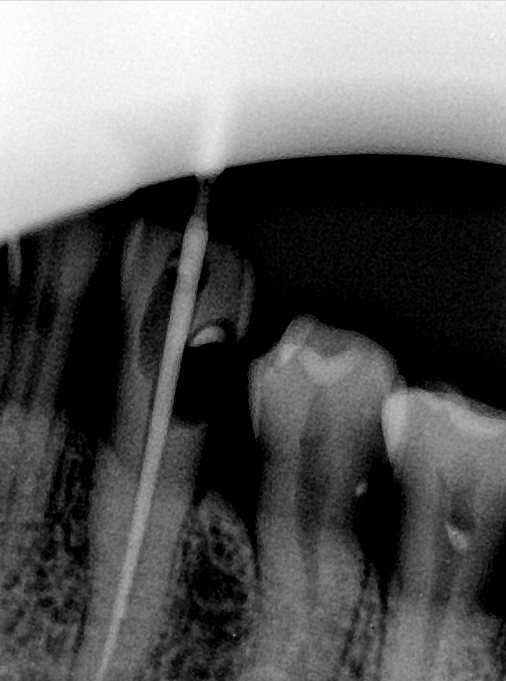 | 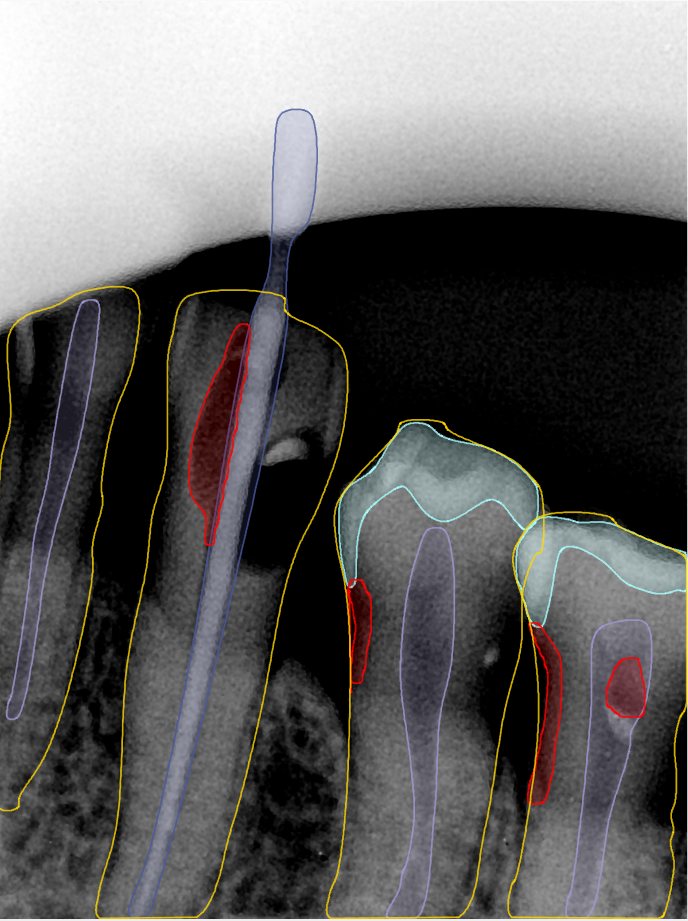 | 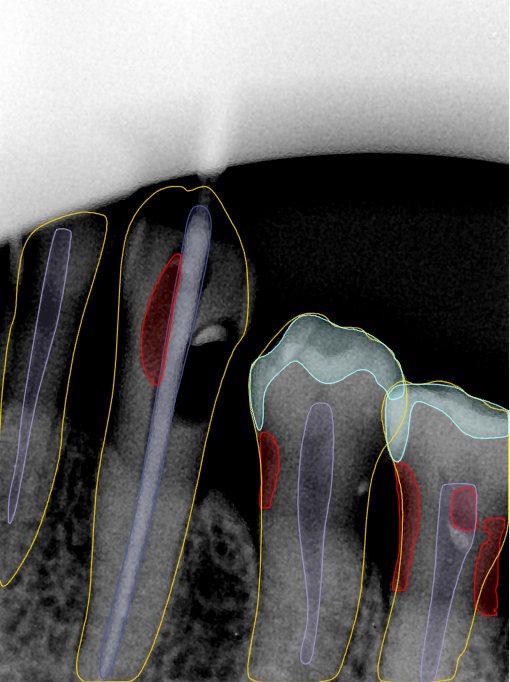 | 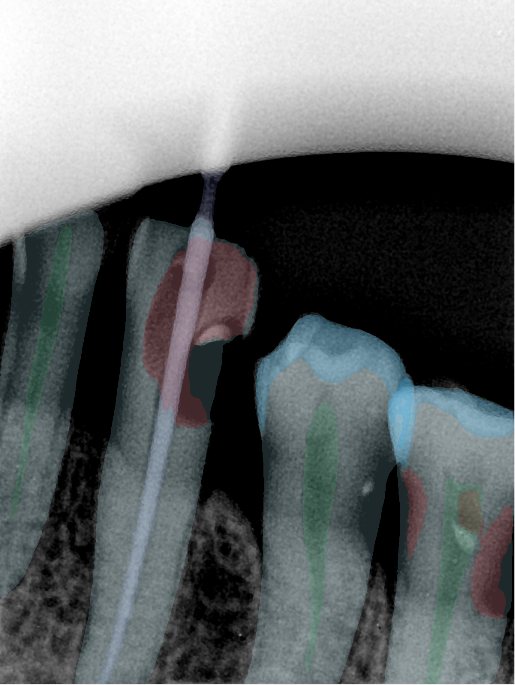 | 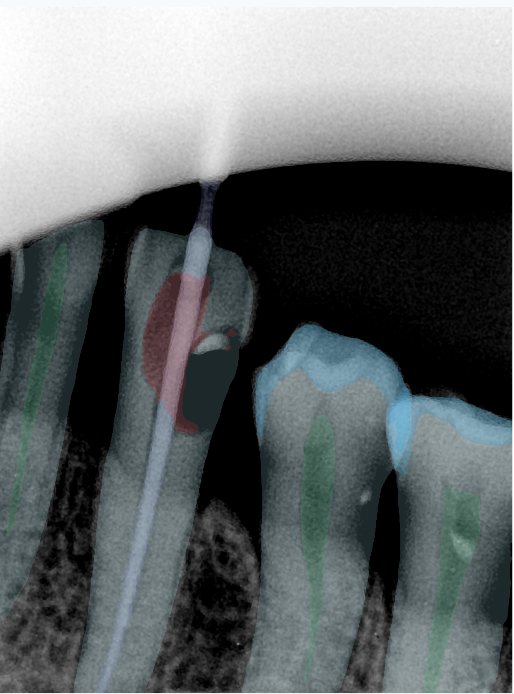 | 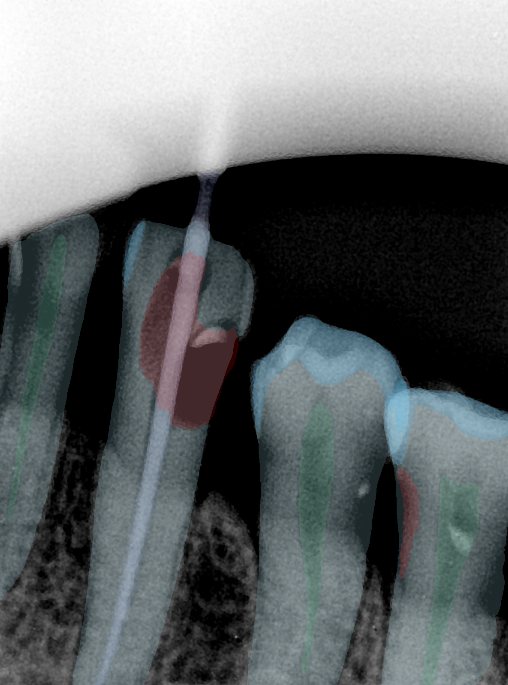 |
| 131341.jpg | 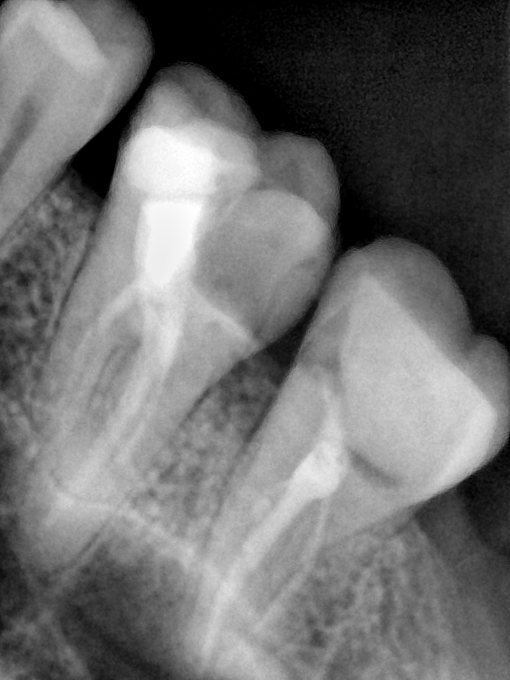 | 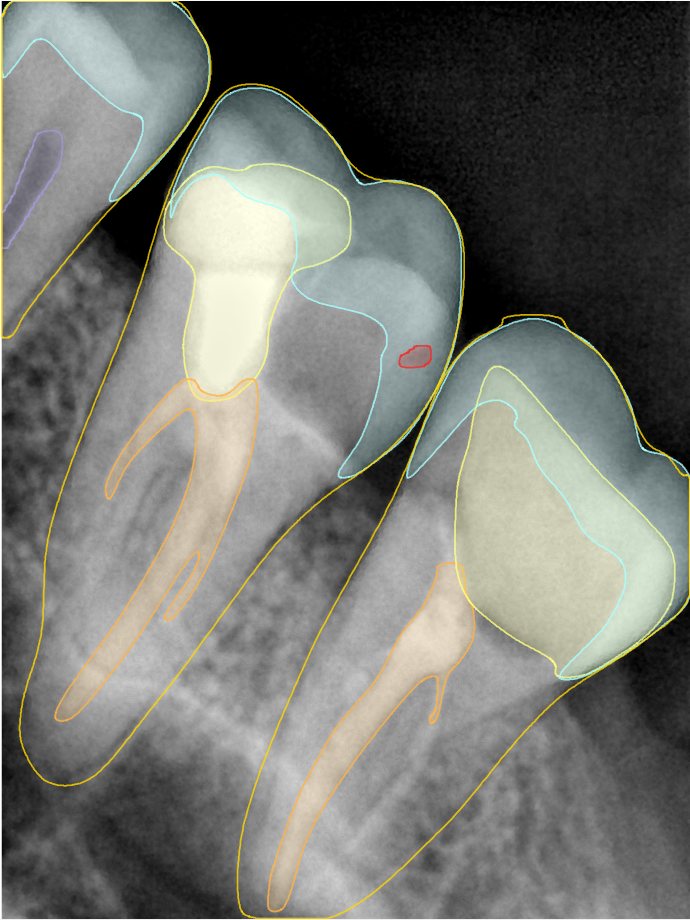 | 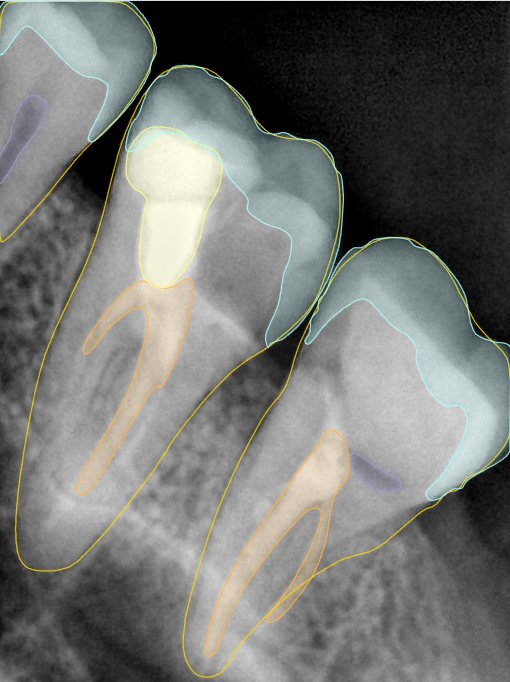 | 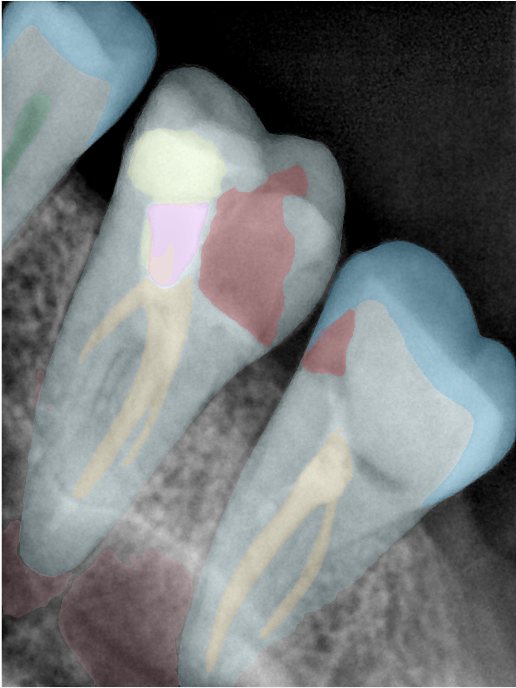 | 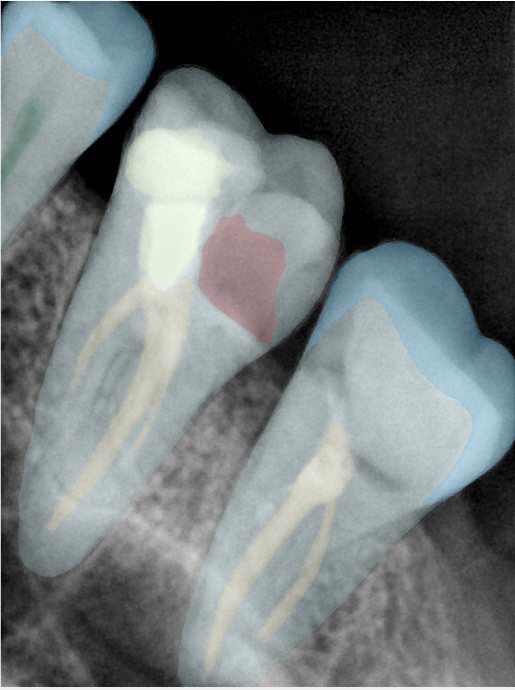 | 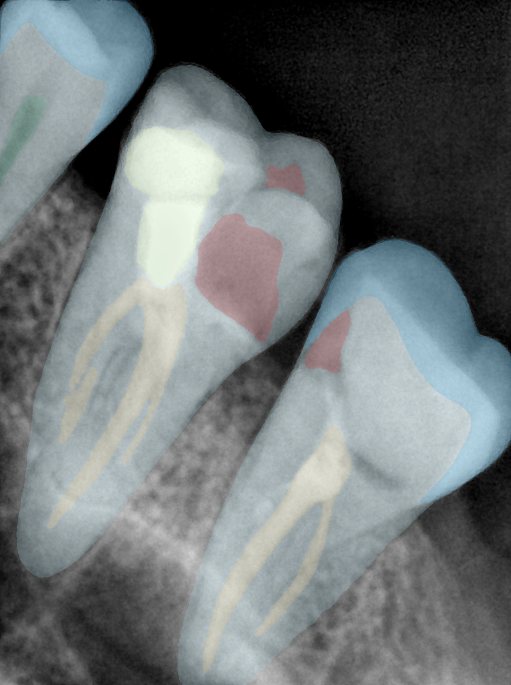 |
| 131342.jpg | 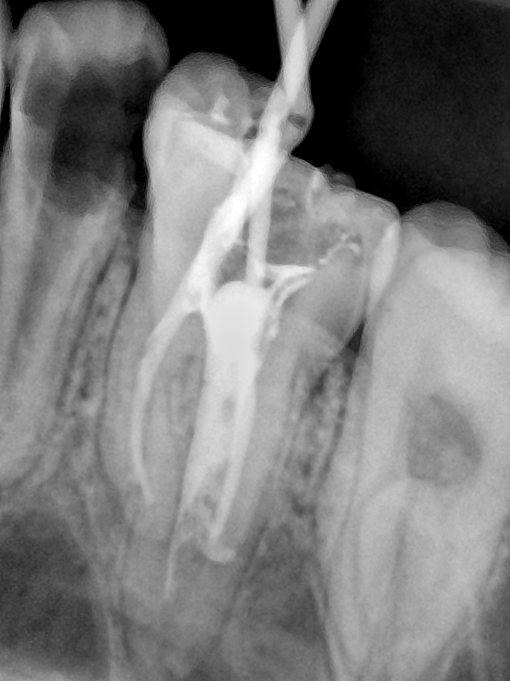 | 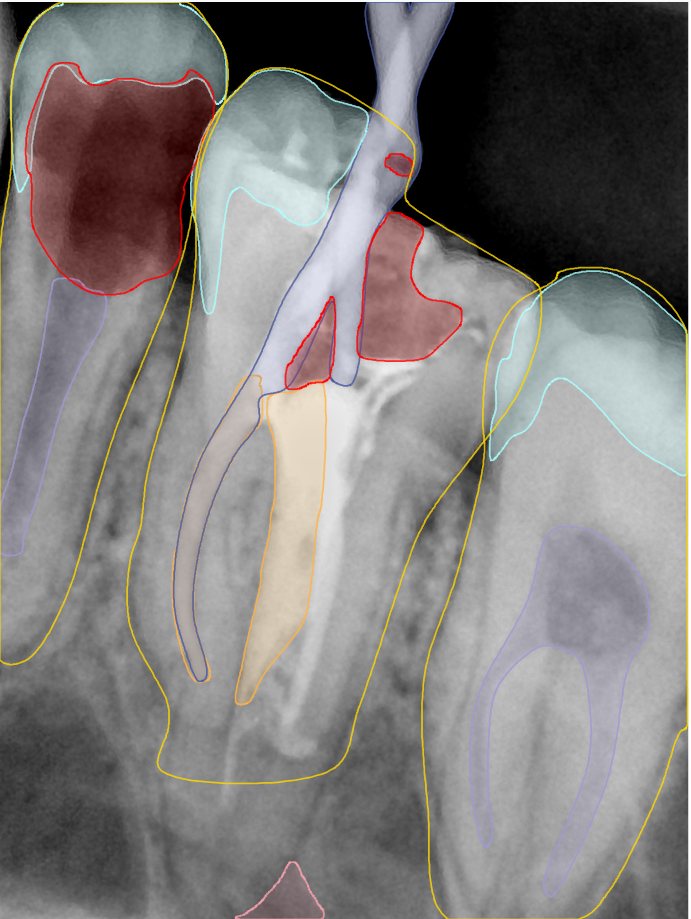 | 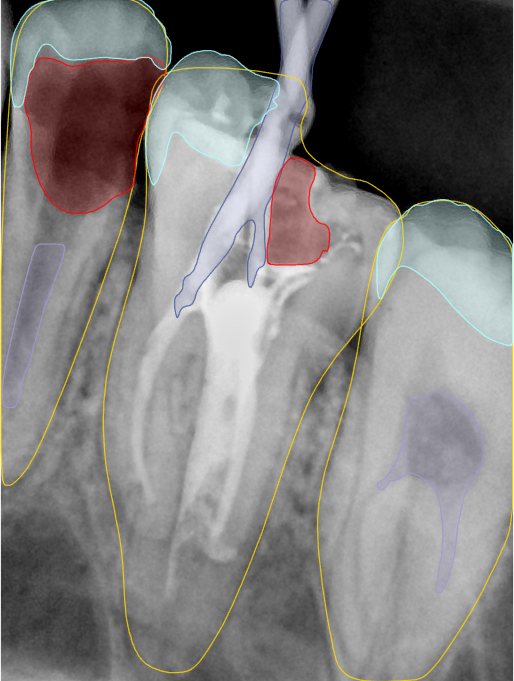 | 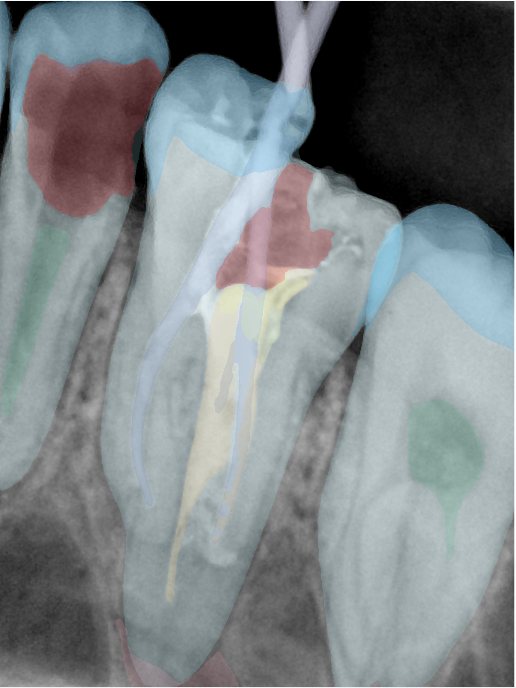 | 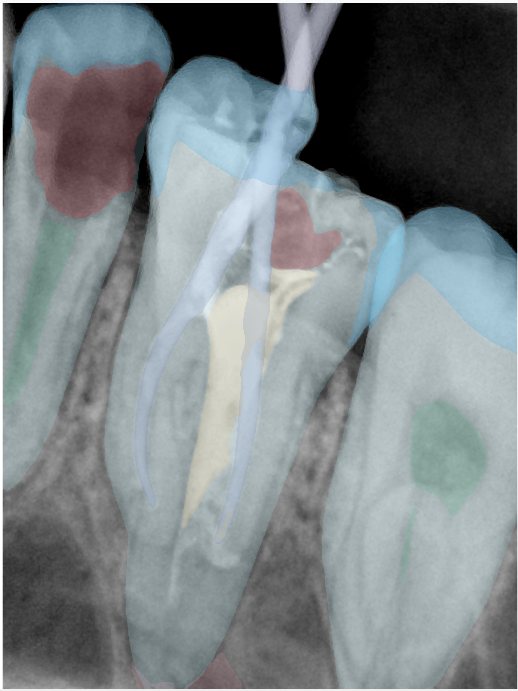 | 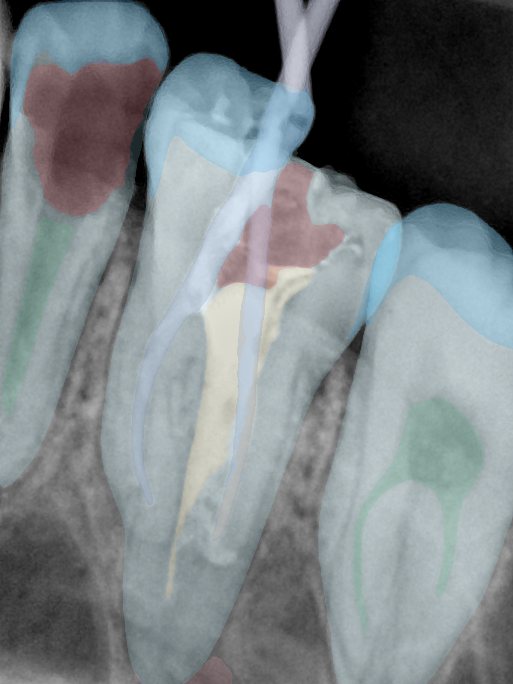 |
| 131344.jpg |  | 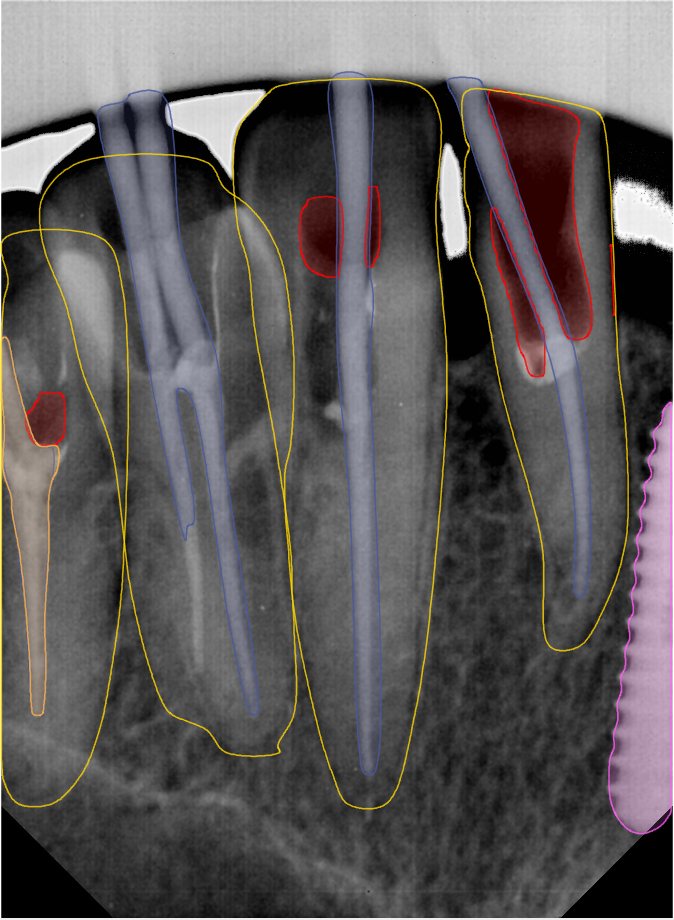 | 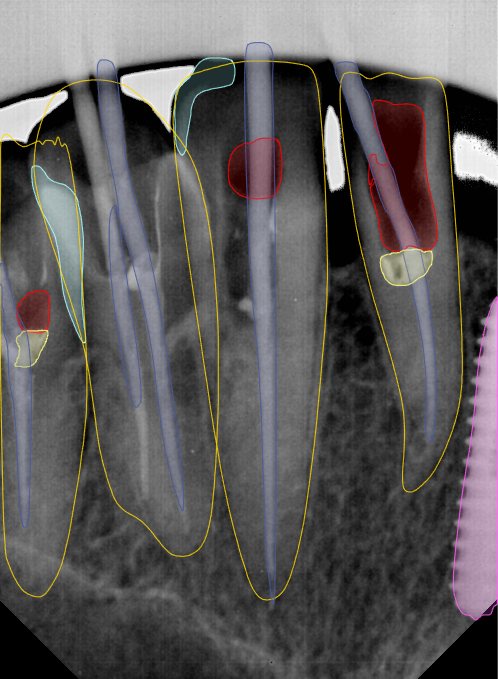 | 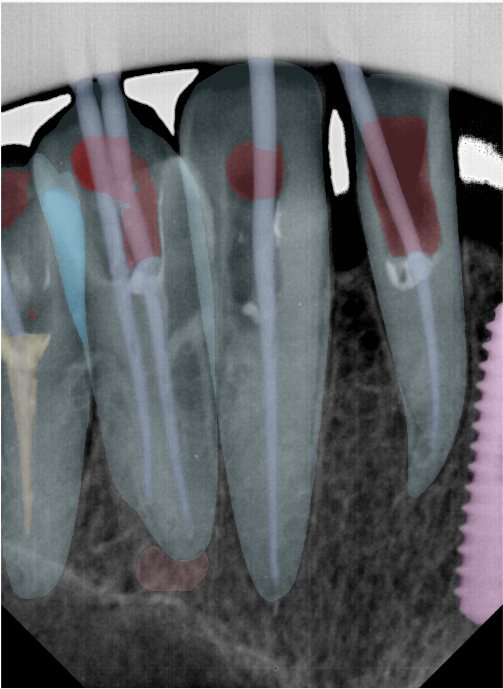 | 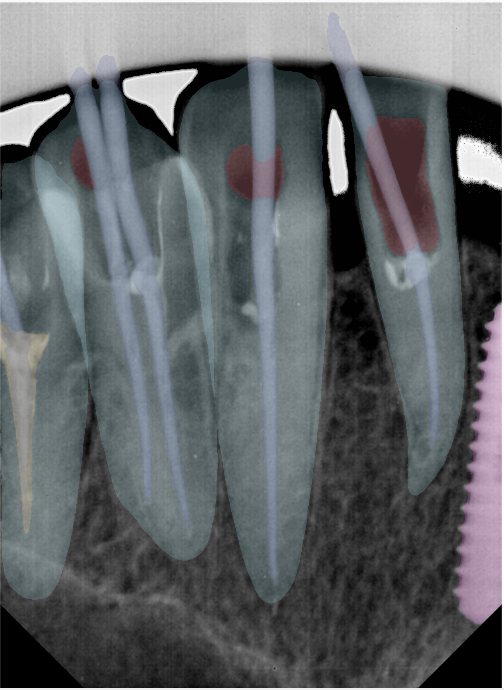 | 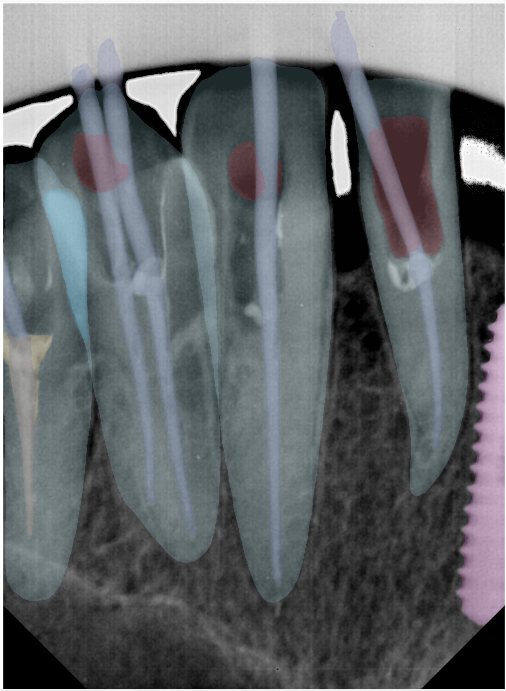 |
| 131345.jpg | 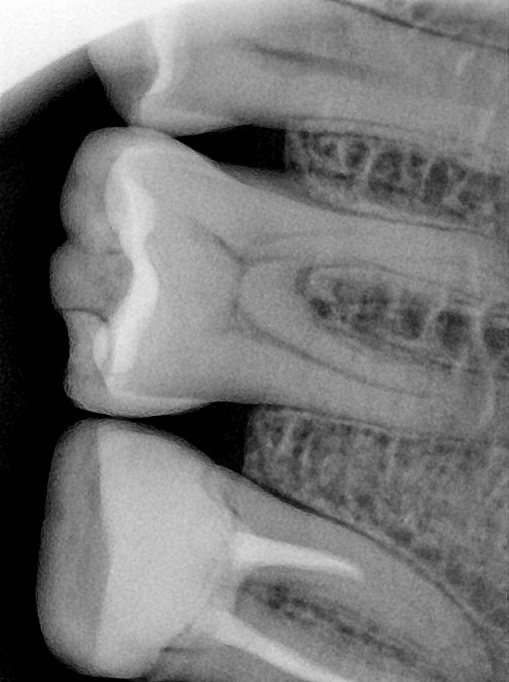 | 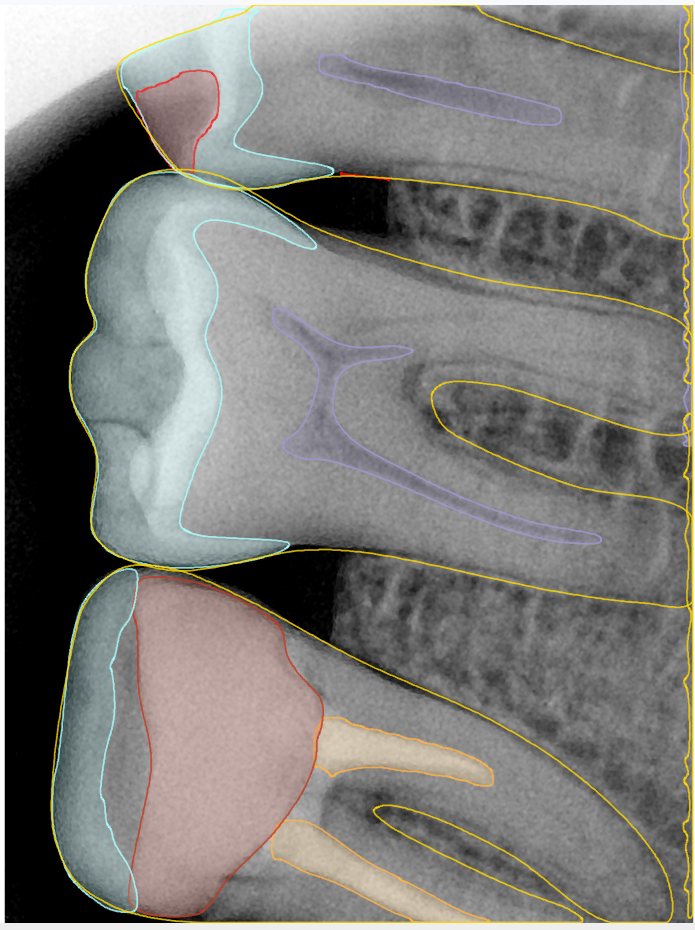 | 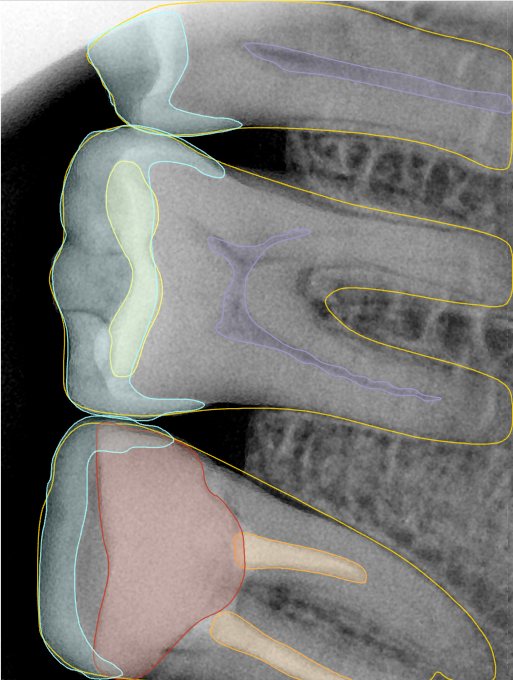 | 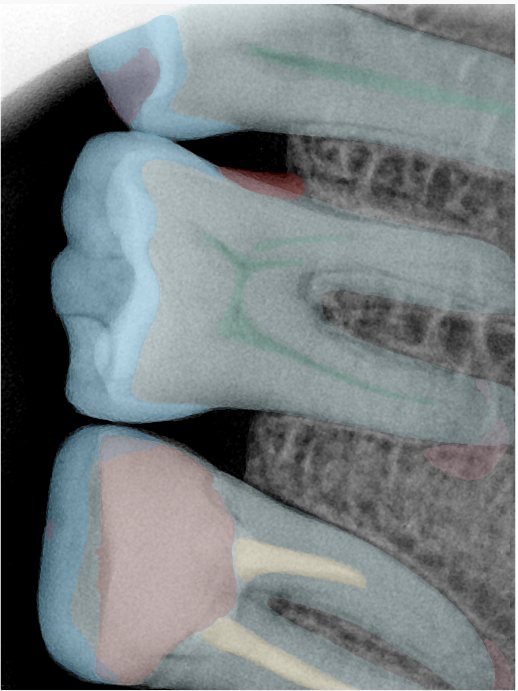 | 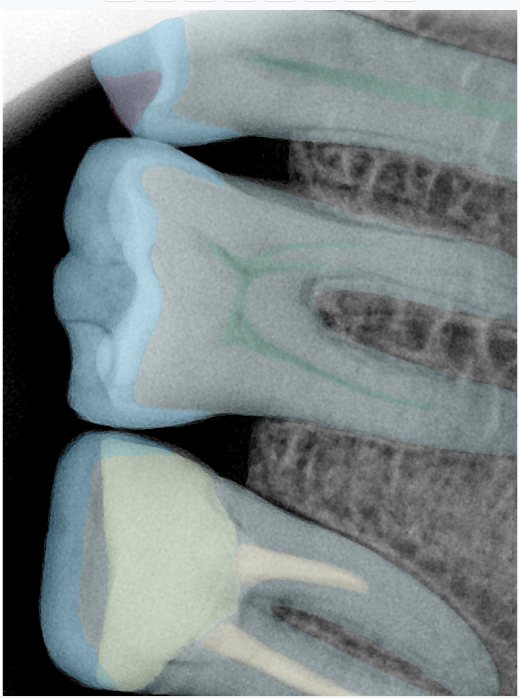 | 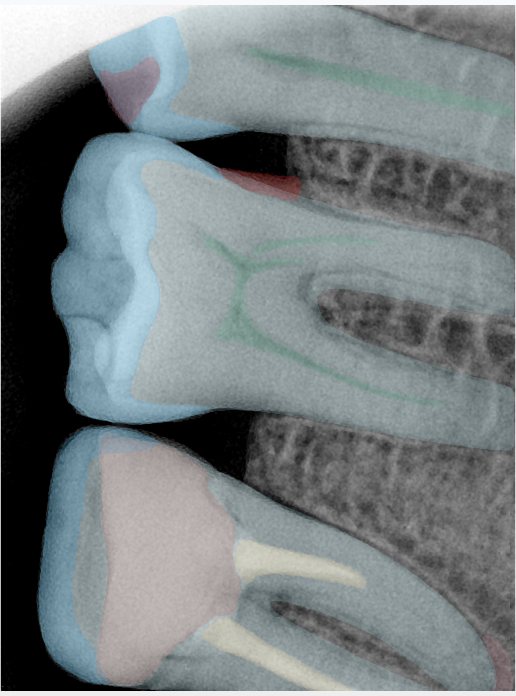 |
| 131346.jpg | 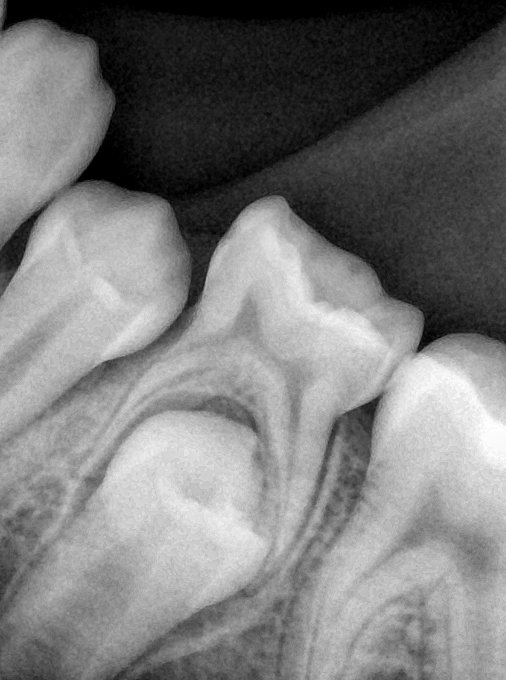 | 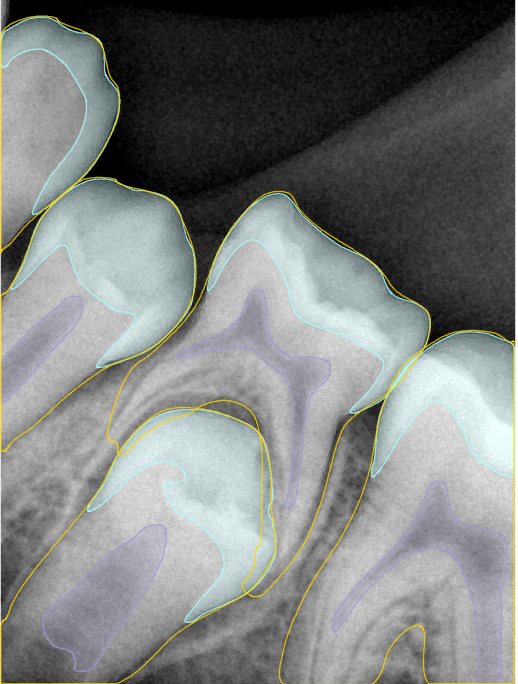 | 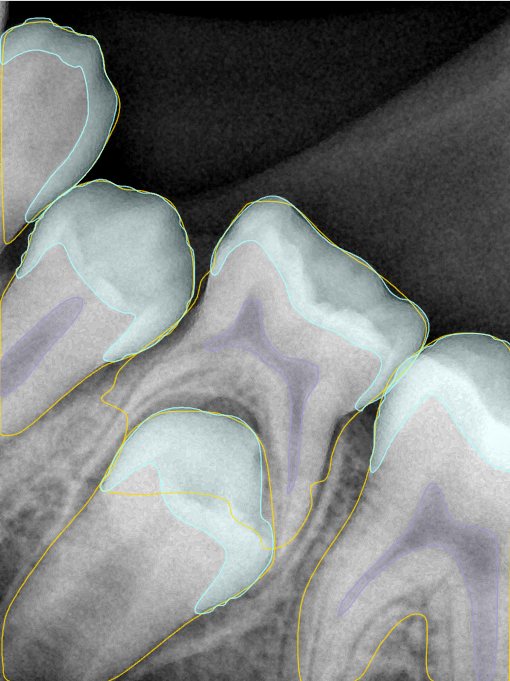 | 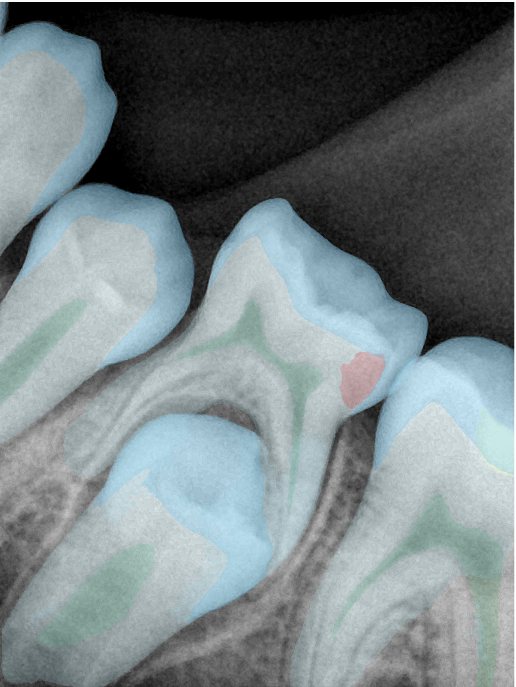 | 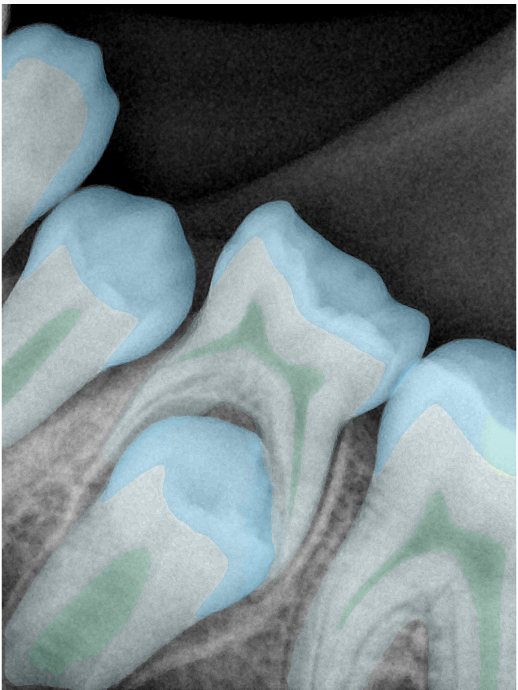 | 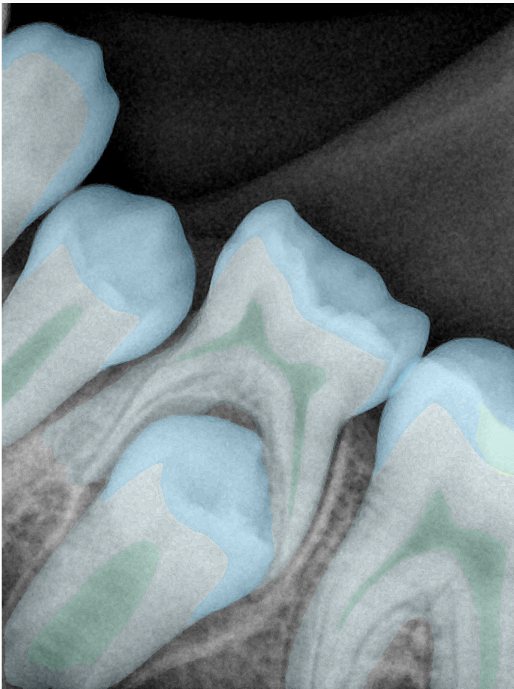 |
| 131347.jpg |  | 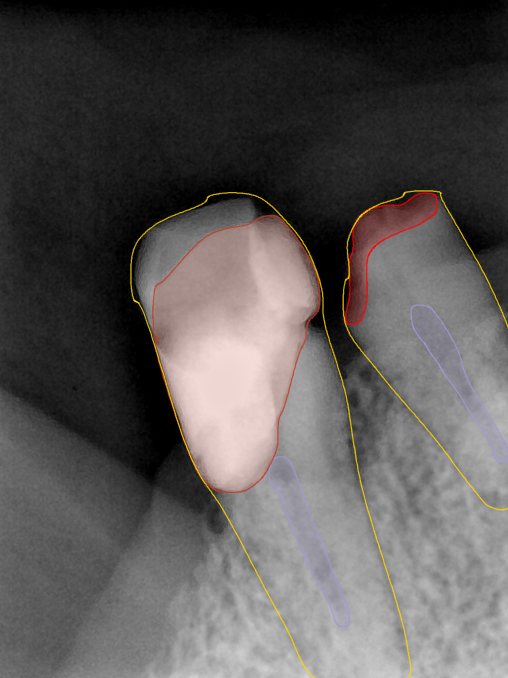 | 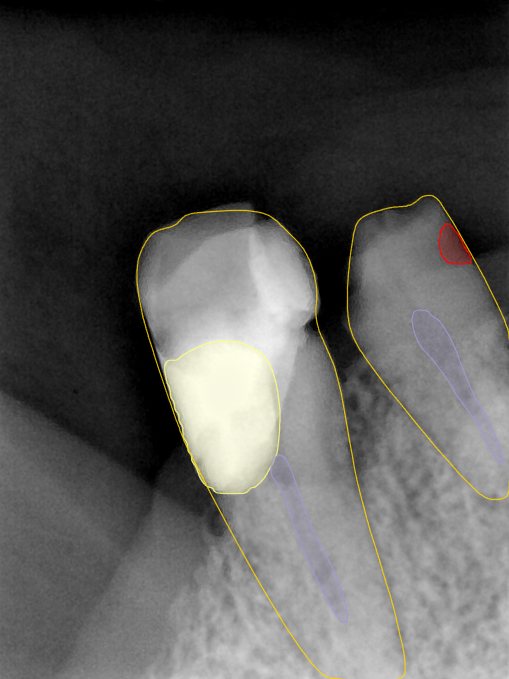 | 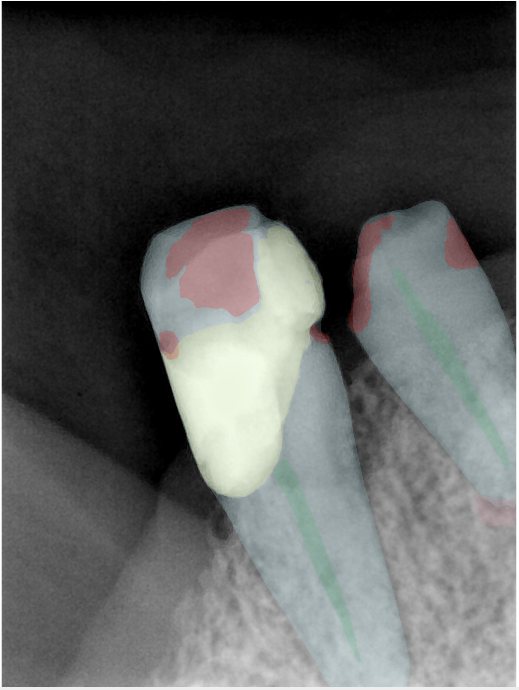 | 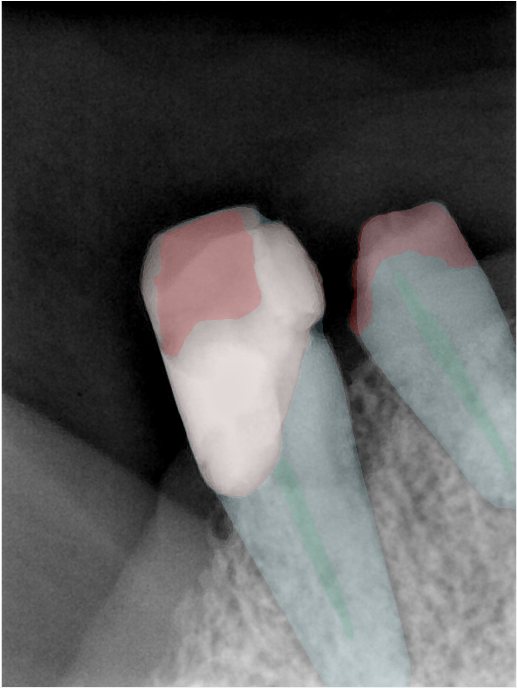 | 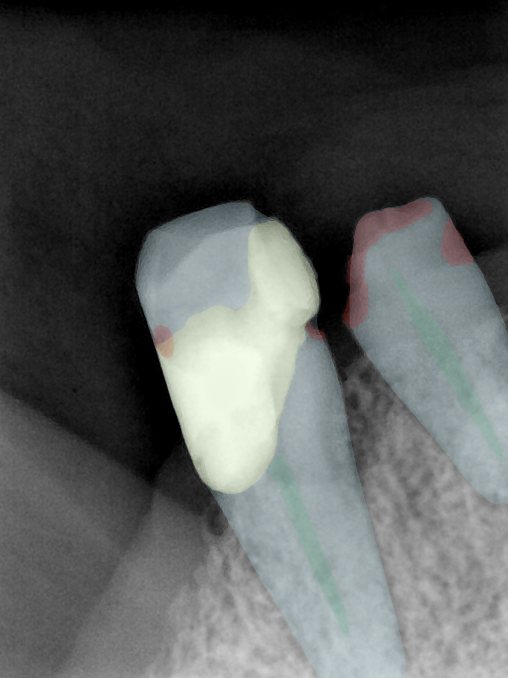 |
| 131348.jpg |  | 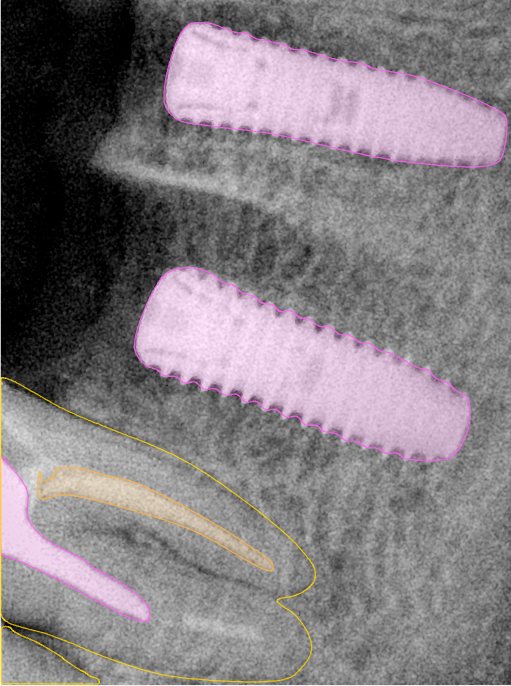 | 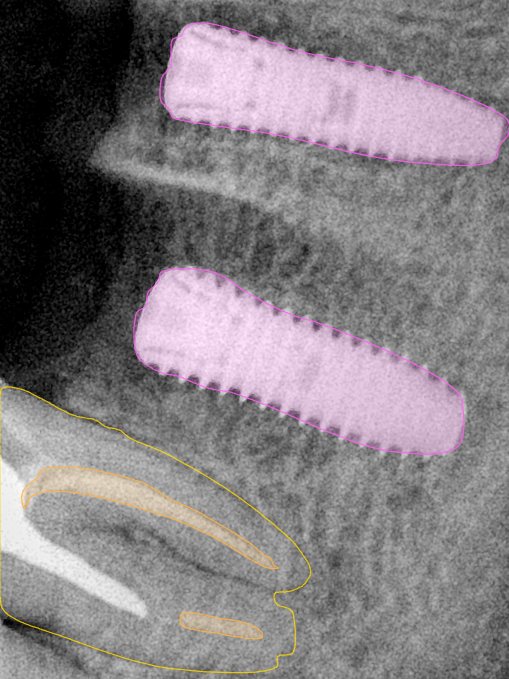 | 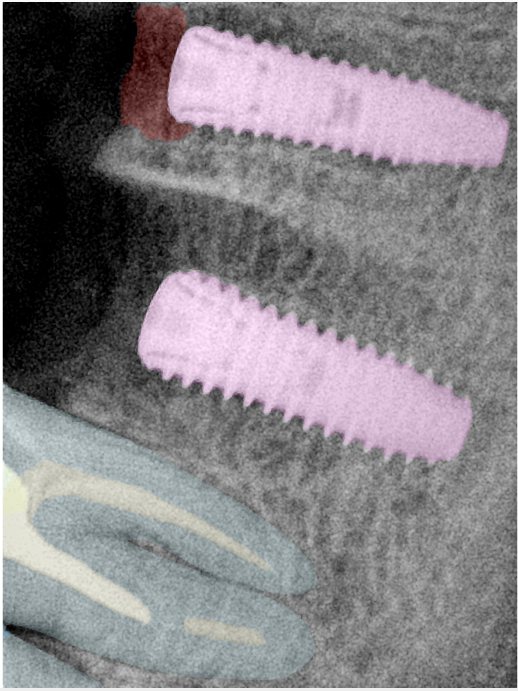 | 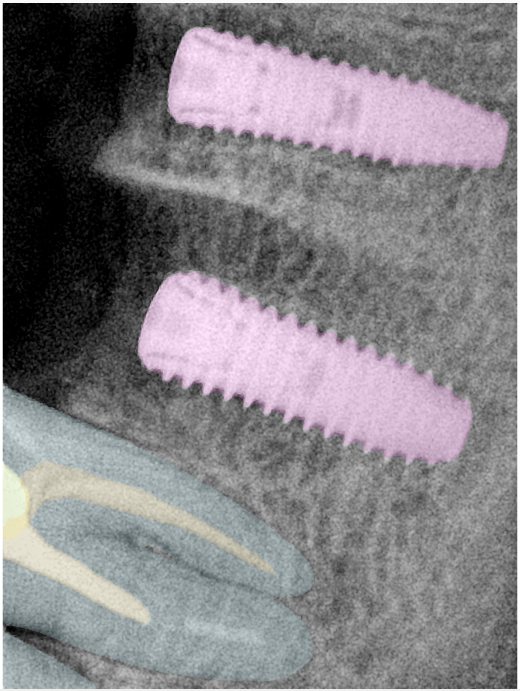 | 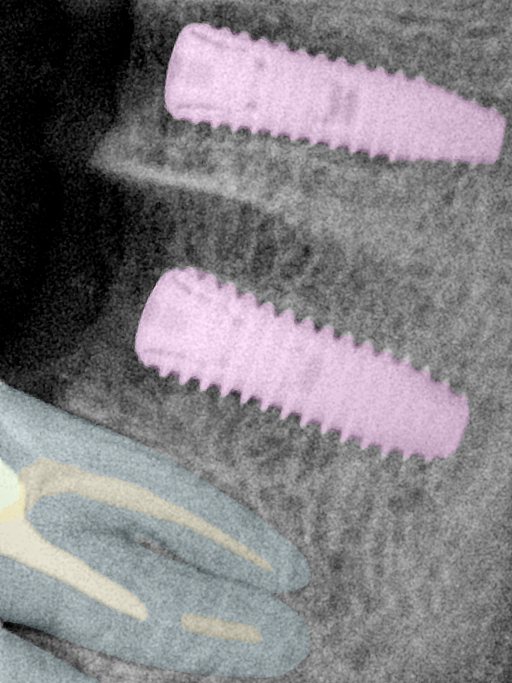 |
| 131349.jpg |  | 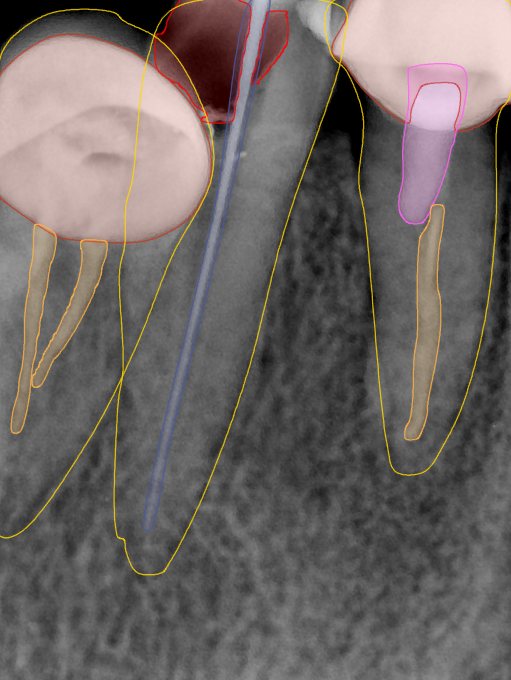 | 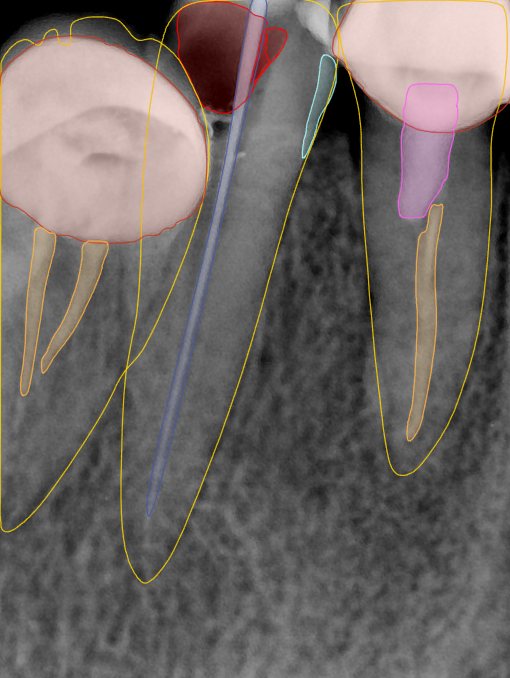 | 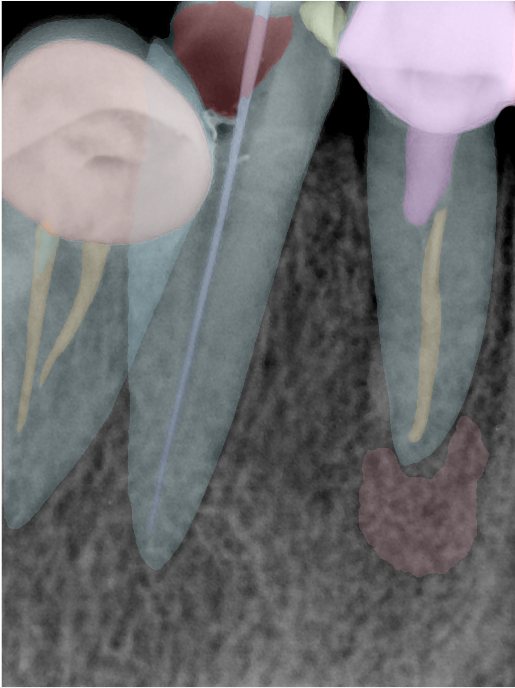 | 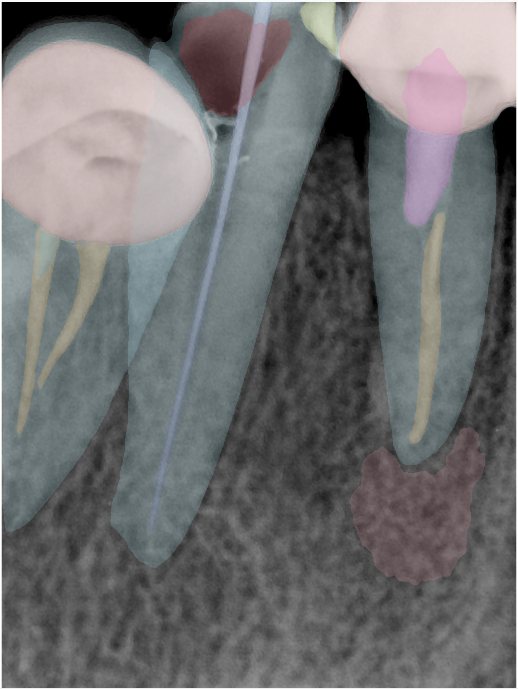 | 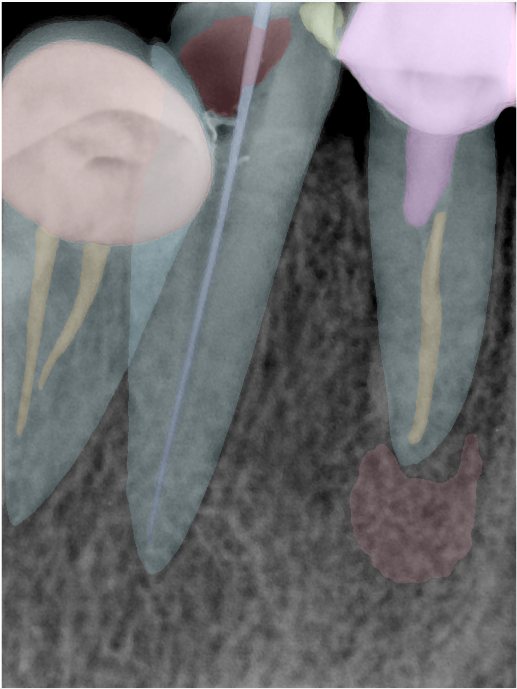 |
| 131350.jpg | 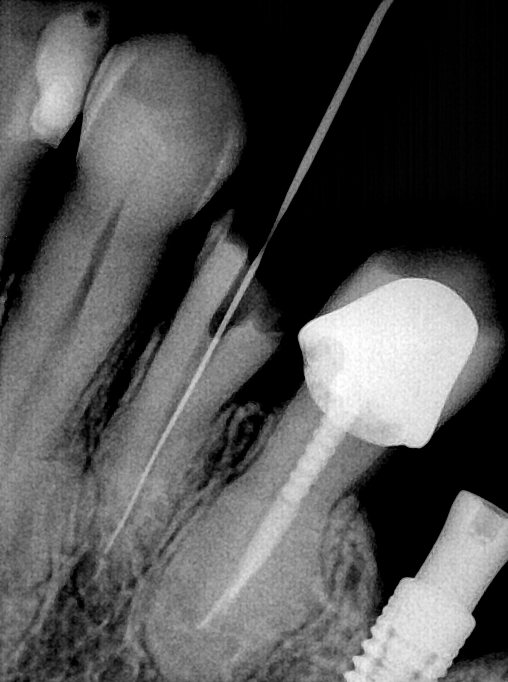 | 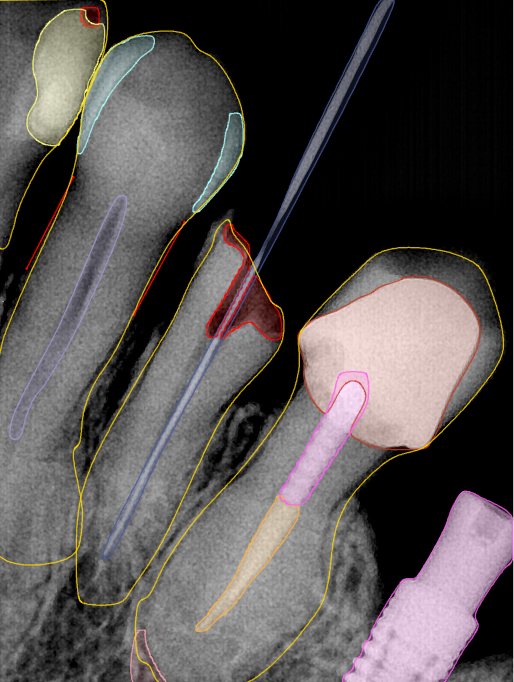 | 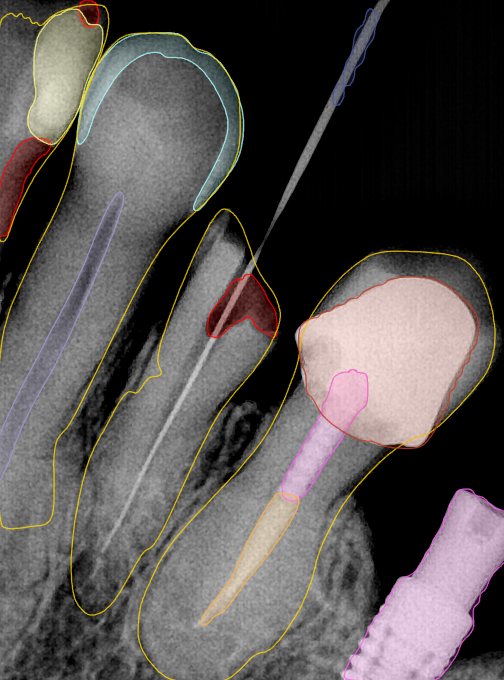 | 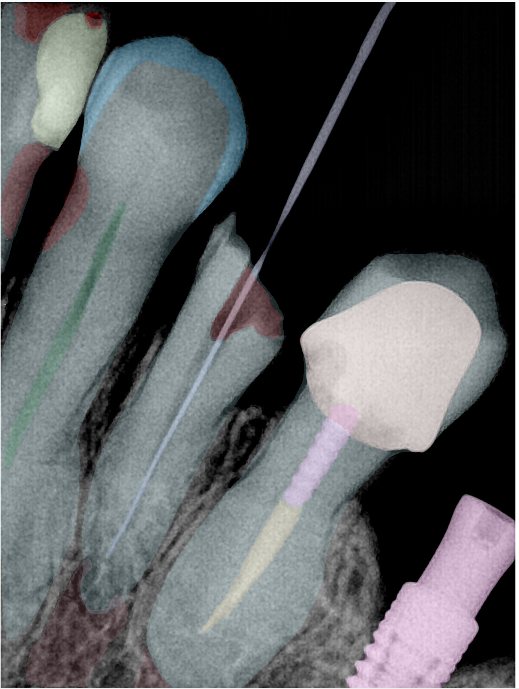 | 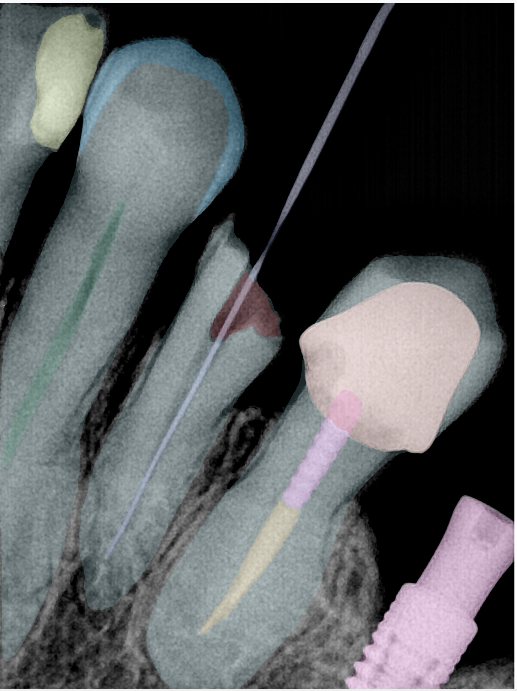 | 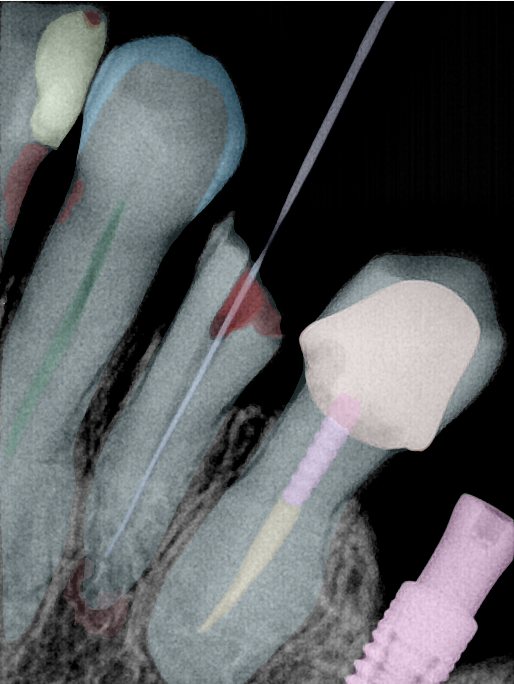 |
| 131354.jpg | 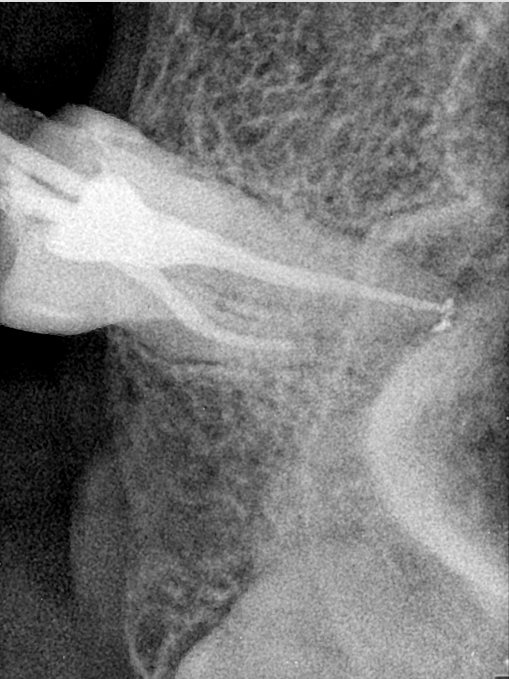 | 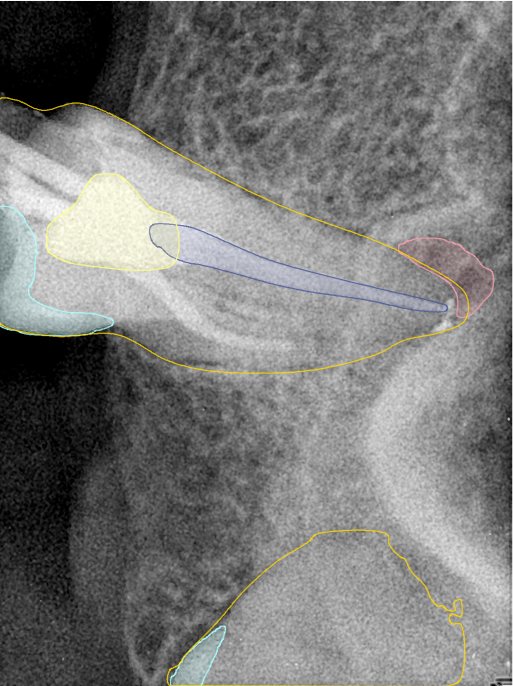 | 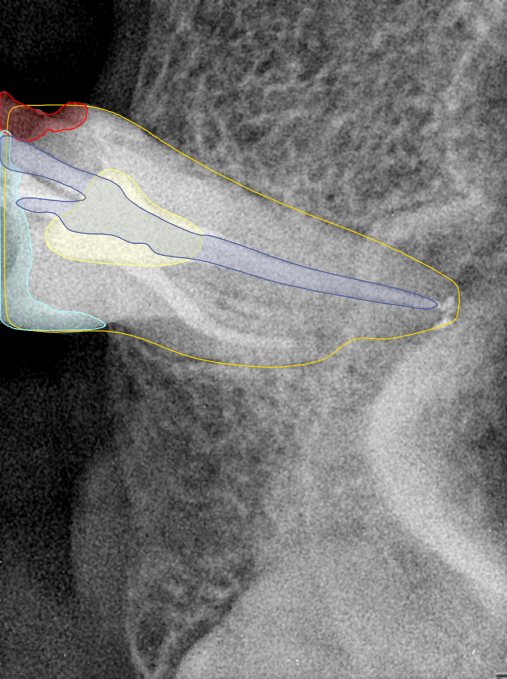 | 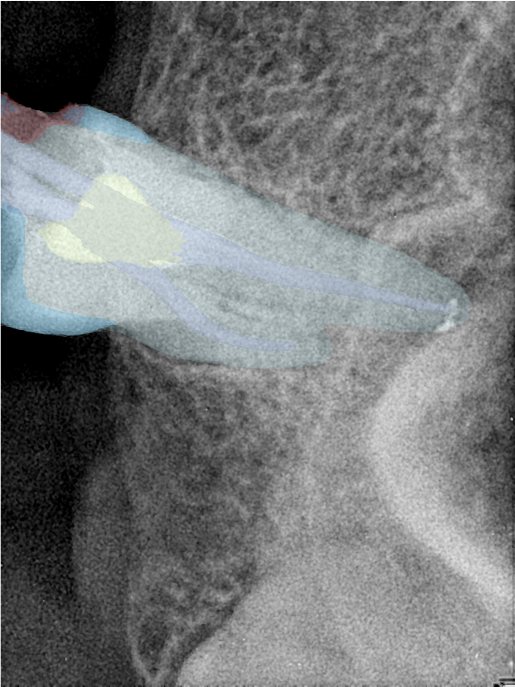 | 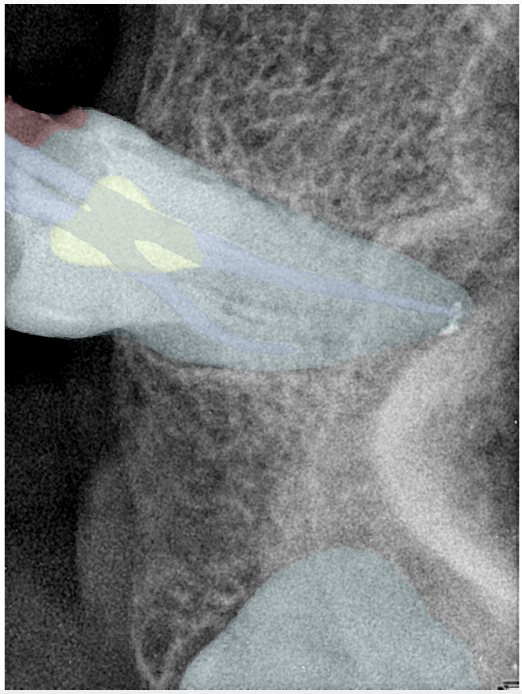 | 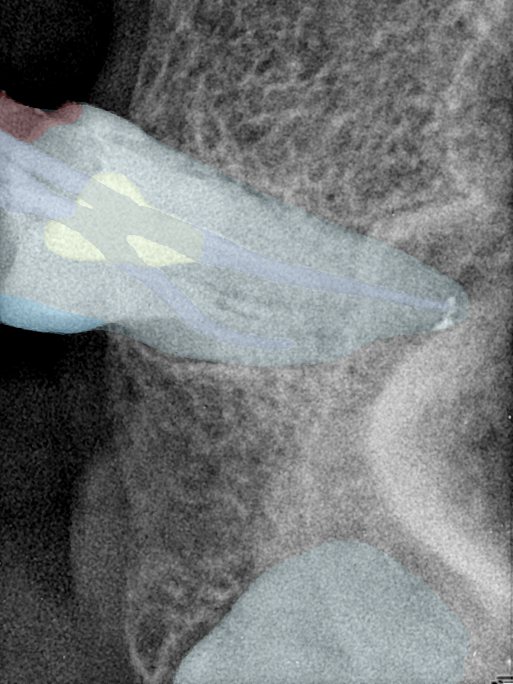 |
| 131355.jpg | 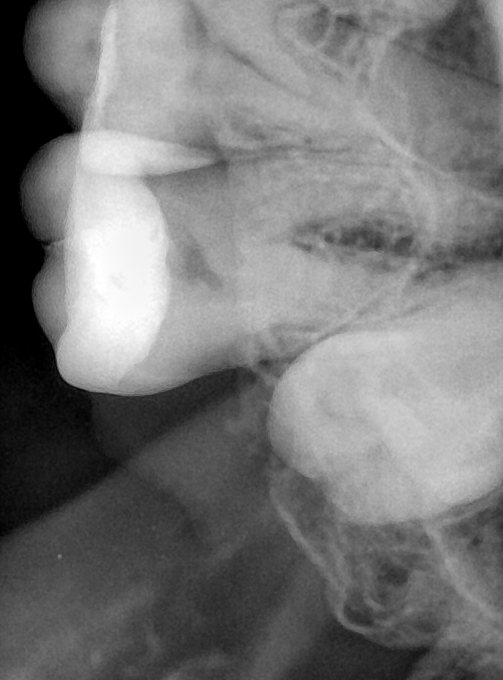 | 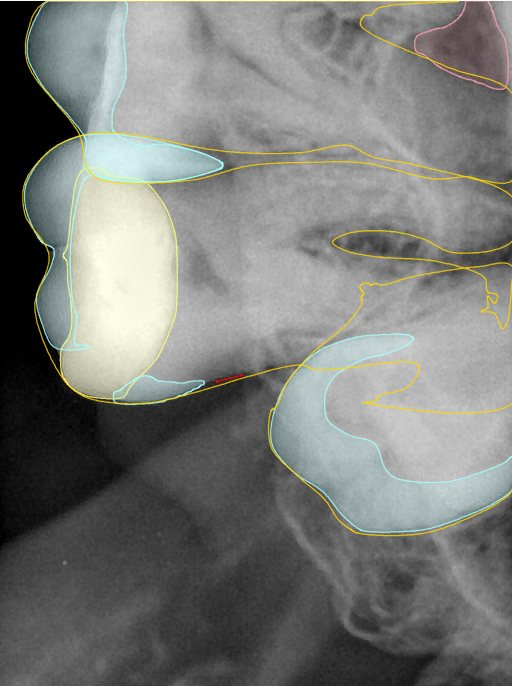 | 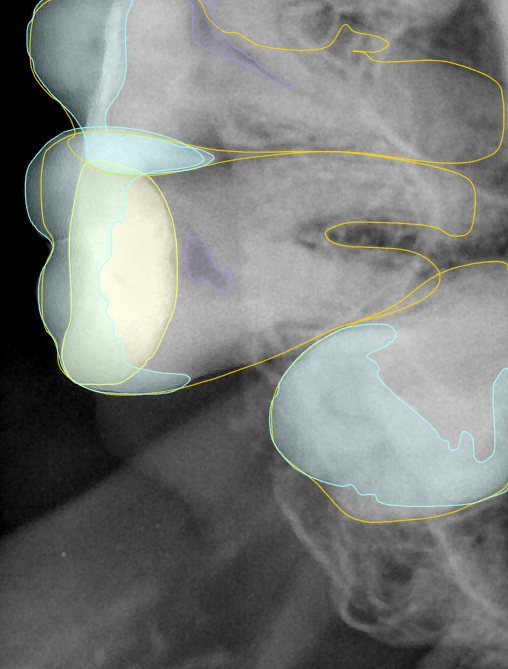 | 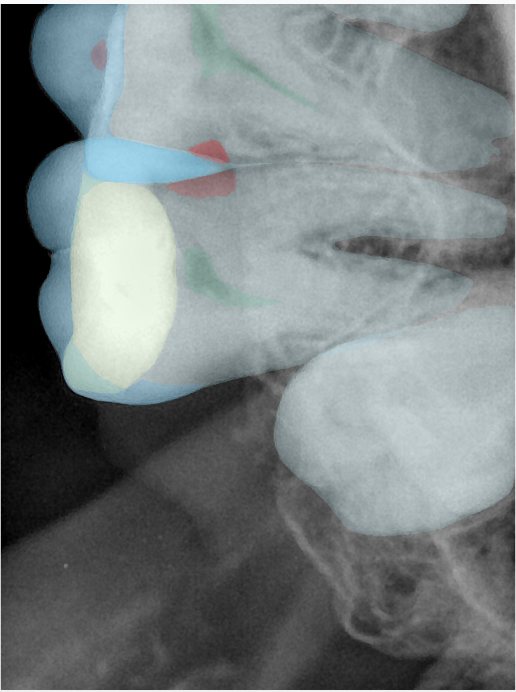 | 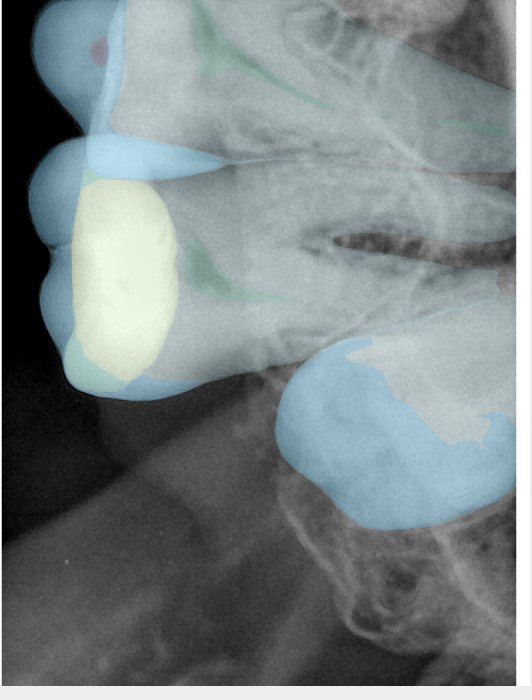 | 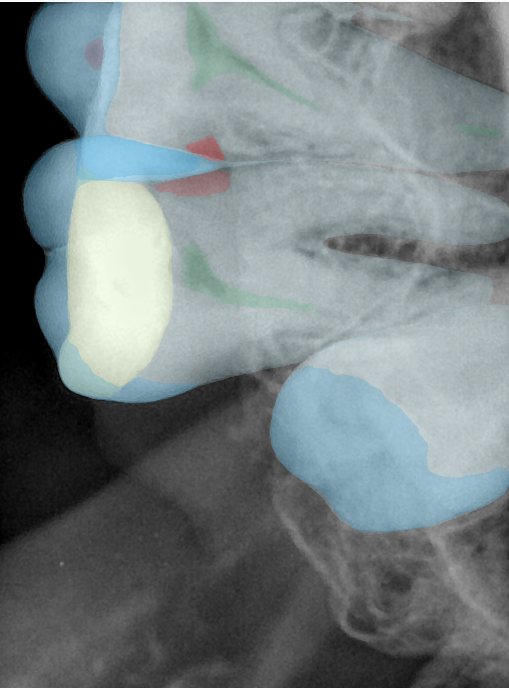 |
| 131356.jpg | 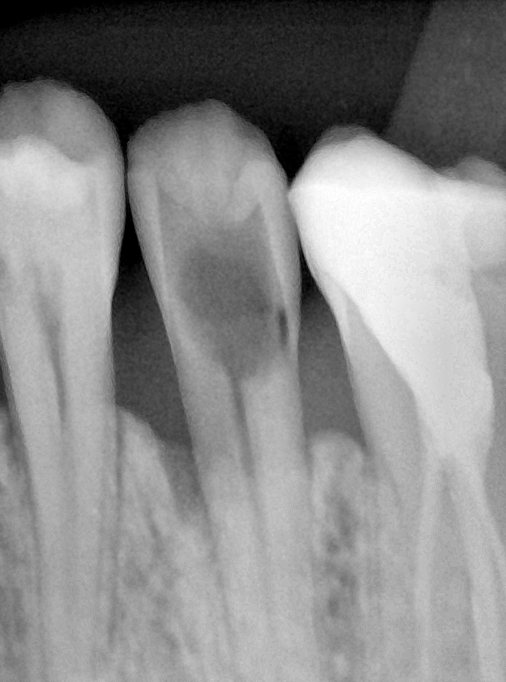 | 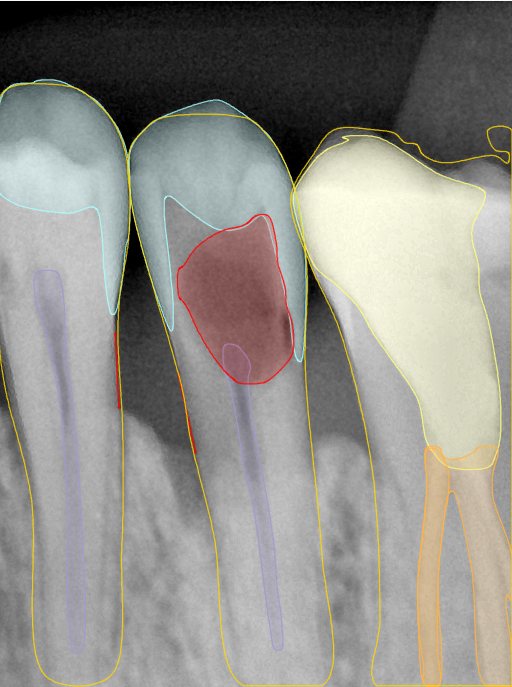 | 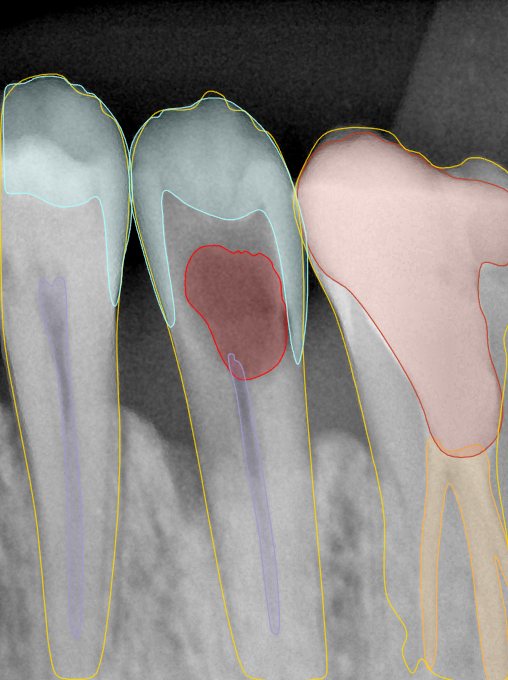 | 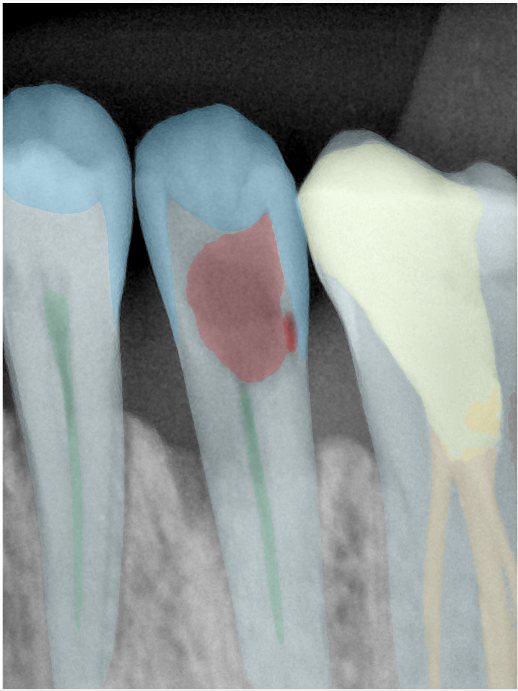 | 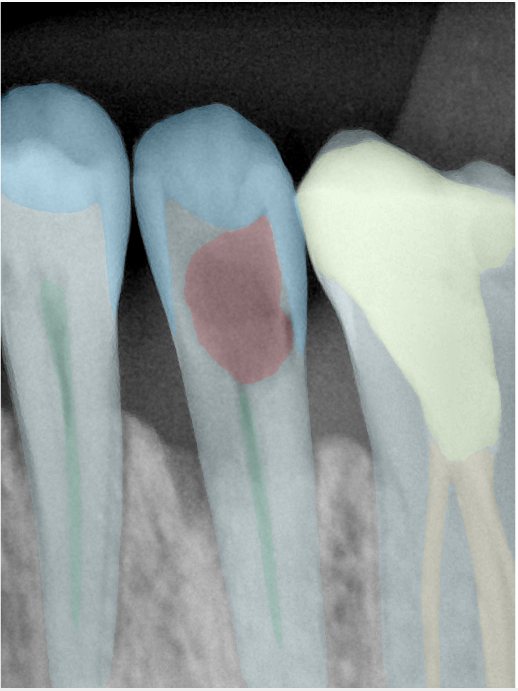 | 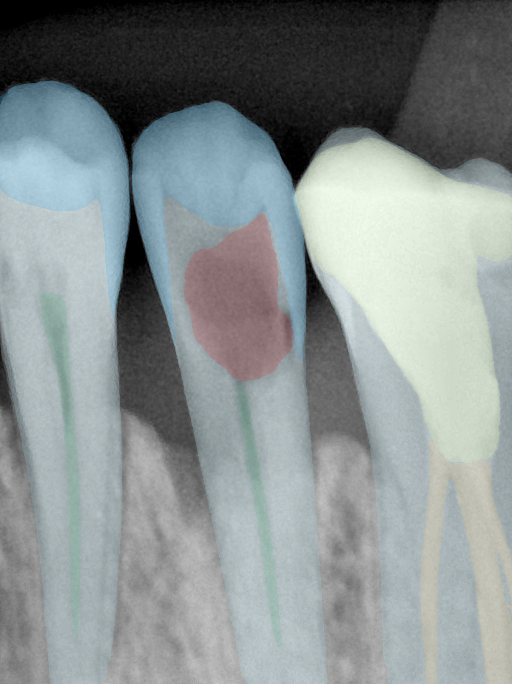 |
| 131357.jpg | 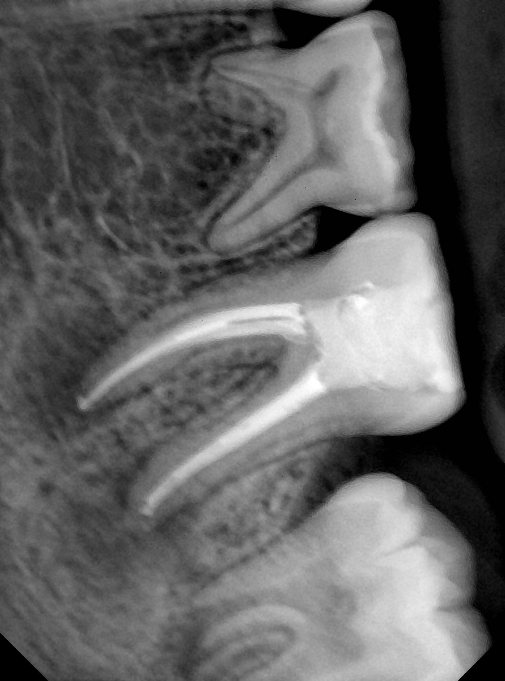 | 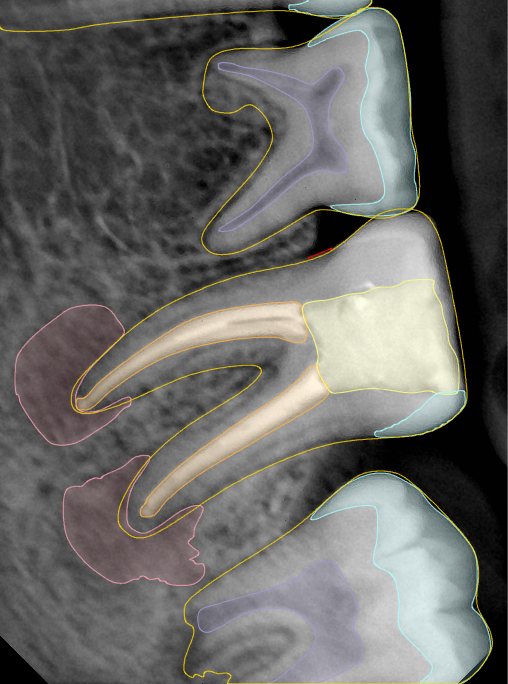 | 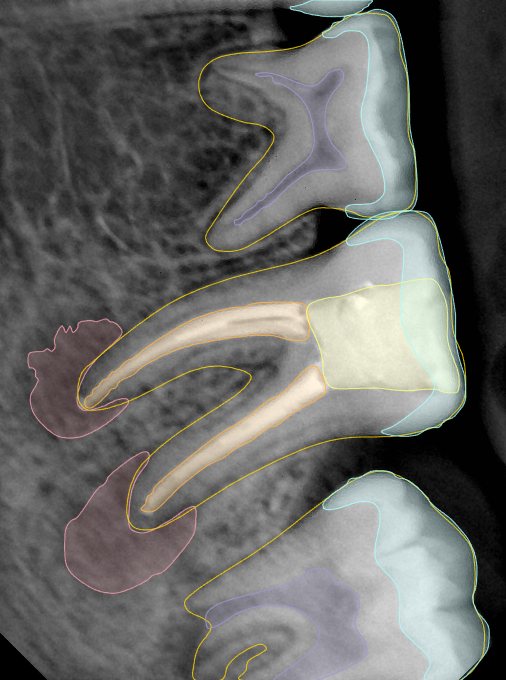 | 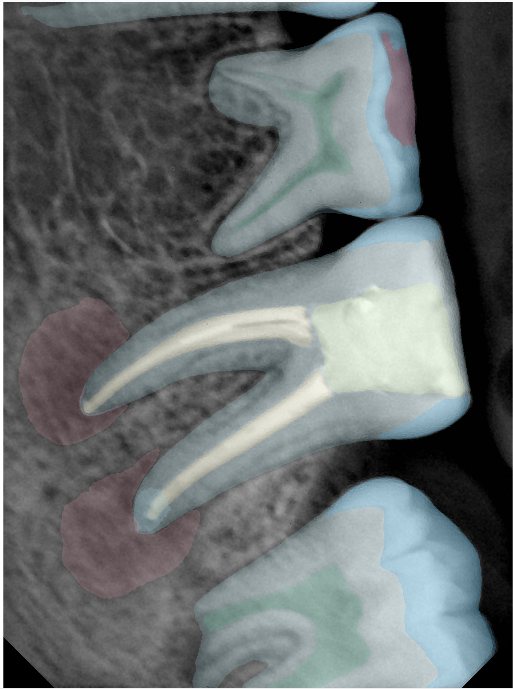 | 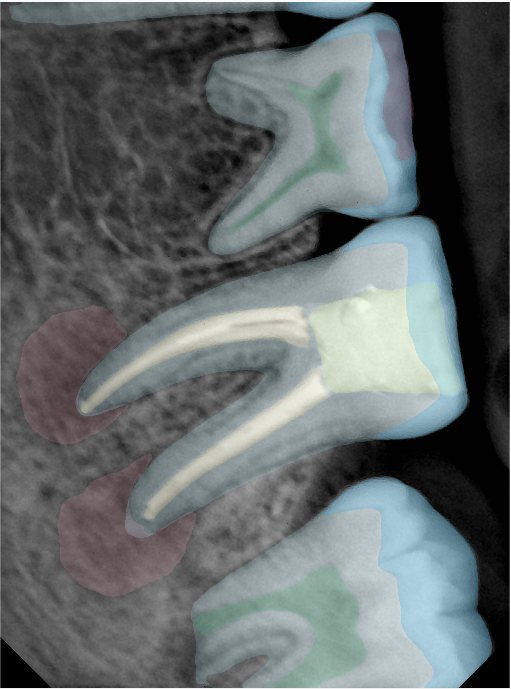 | 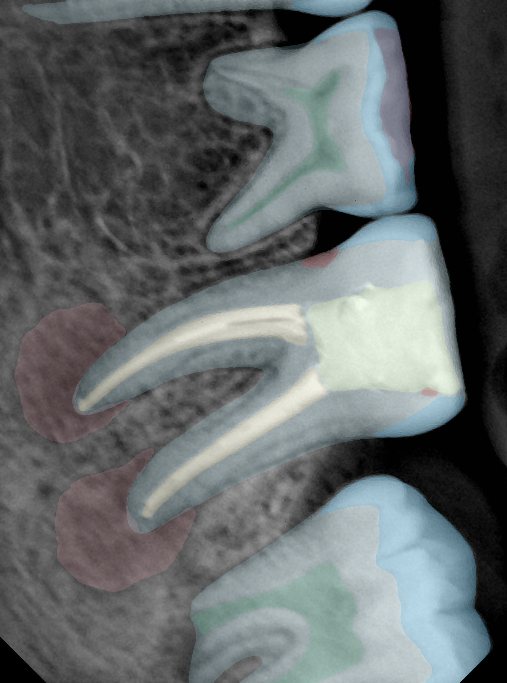 |
| 131360.jpg | 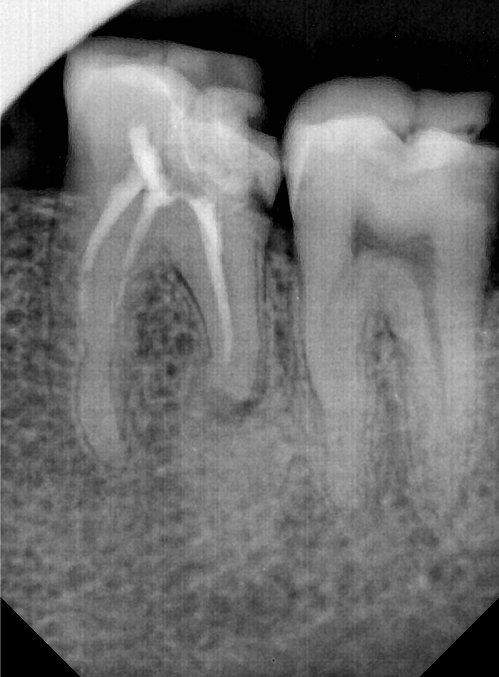 | 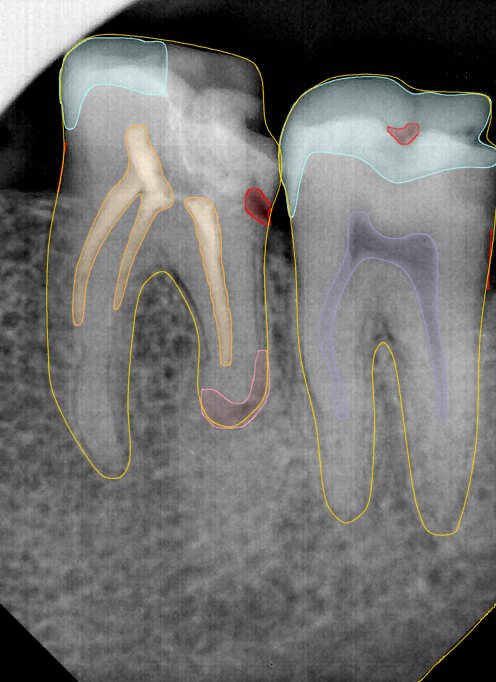 | 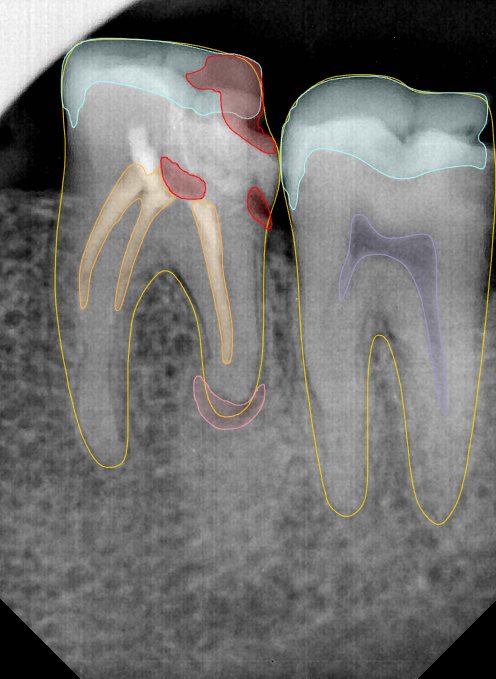 | 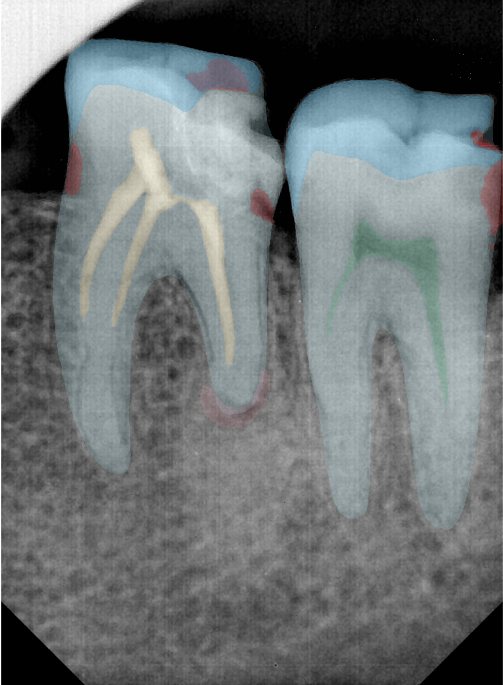 | 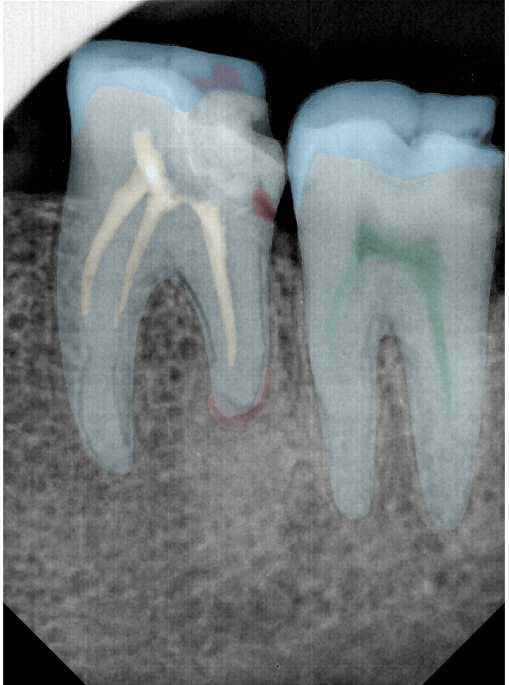 | 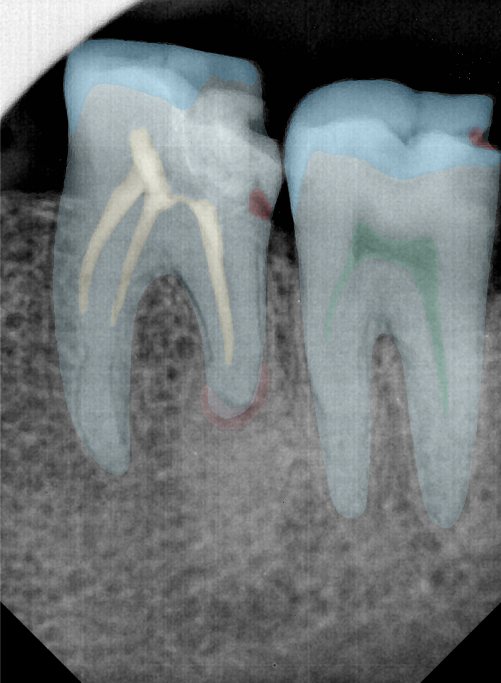 |
| 131362.jpg | 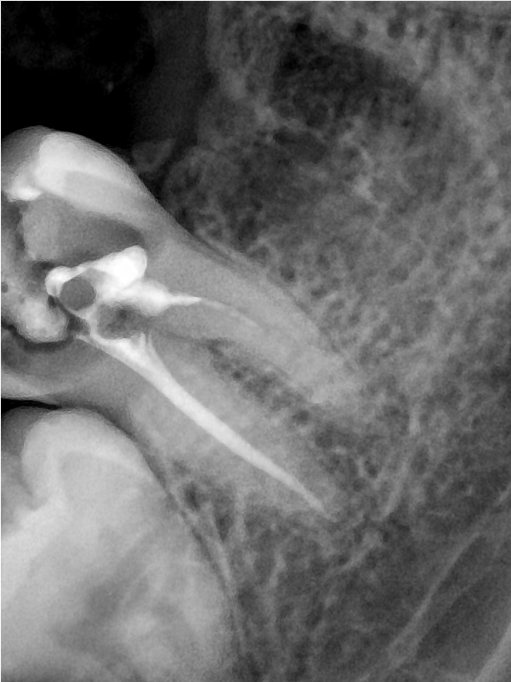 | 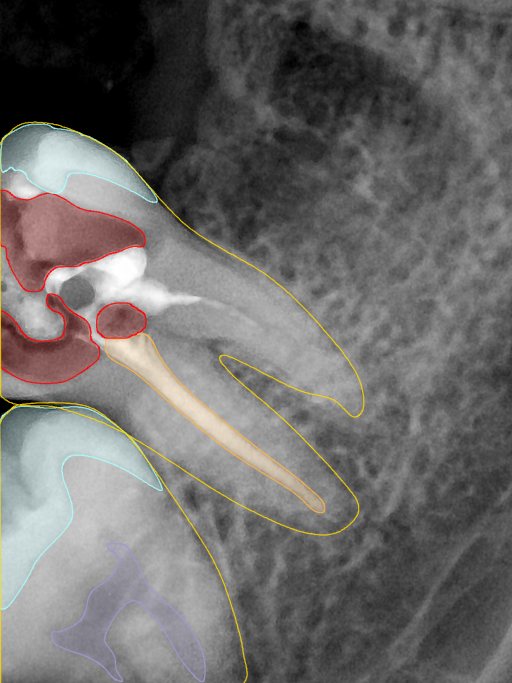 | 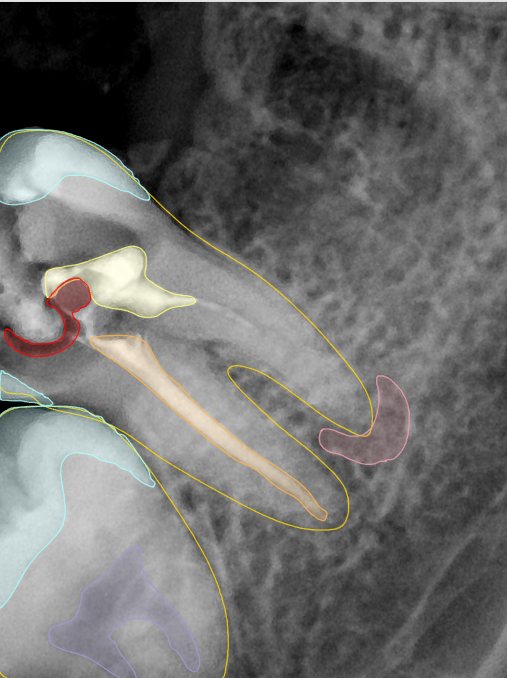 | 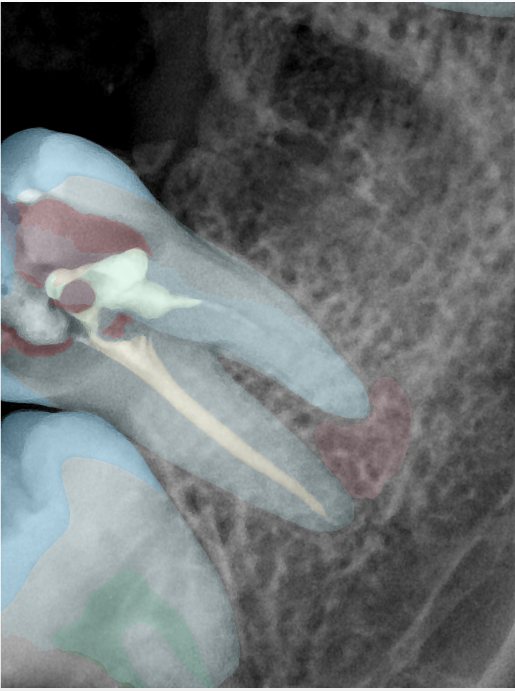 | 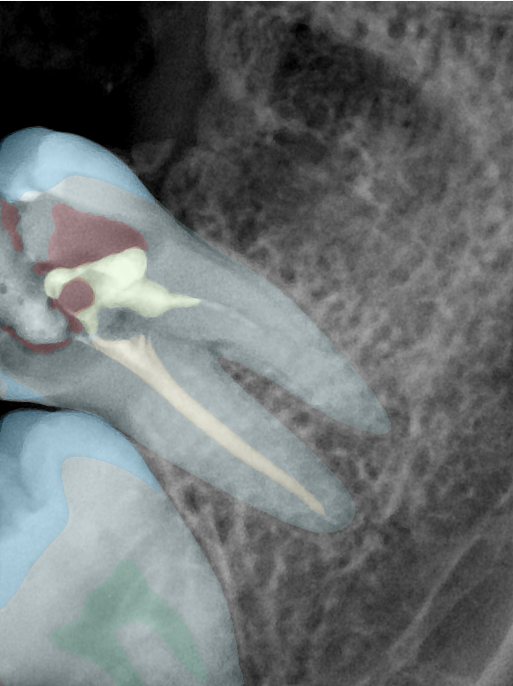 | 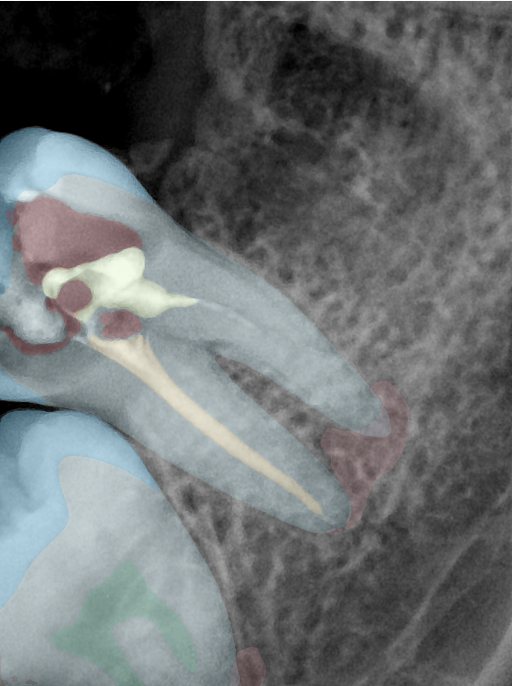 |
| 131363.jpg | 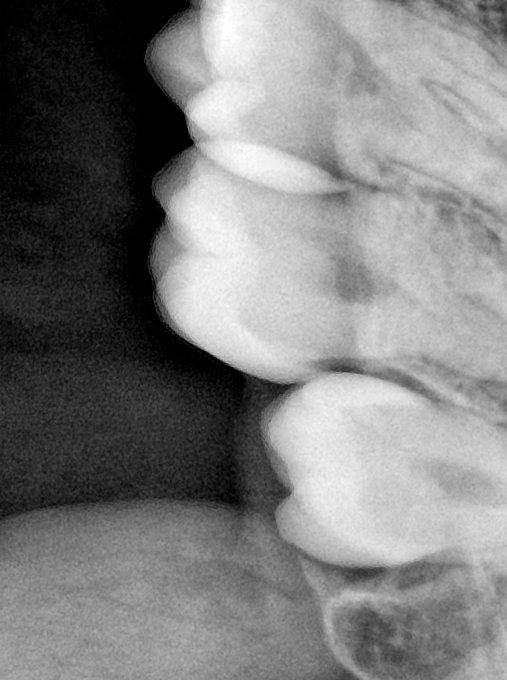 | 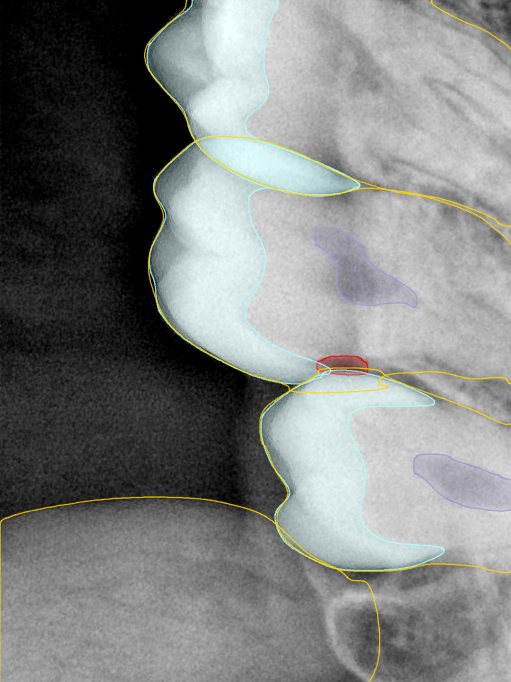 | 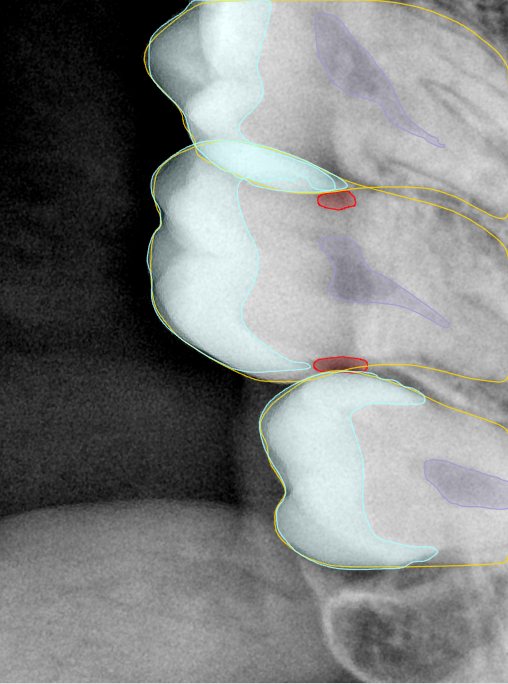 | 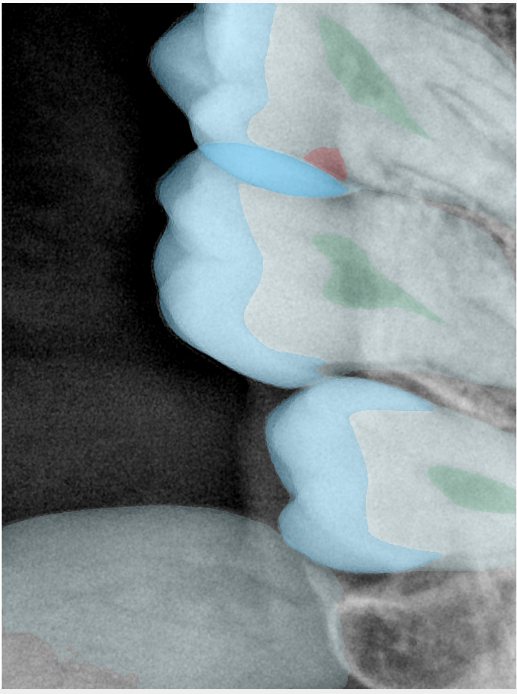 | 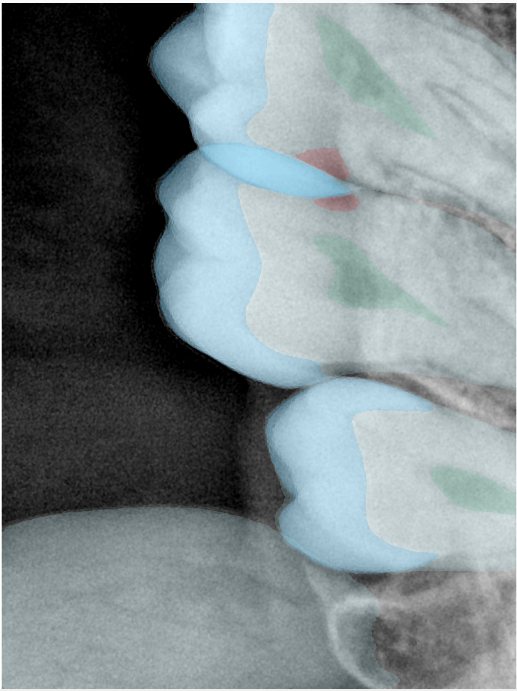 | 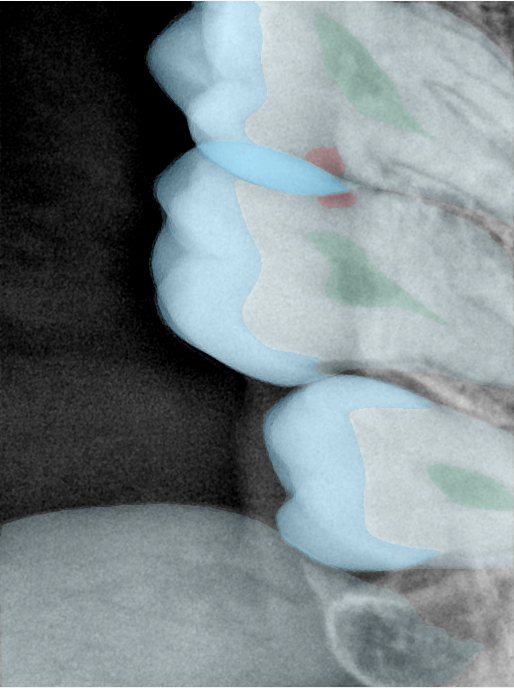 |
| 131364.jpg | 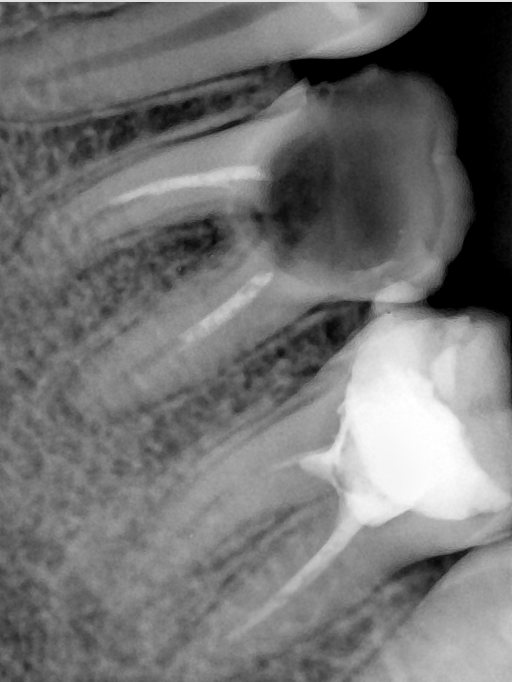 | 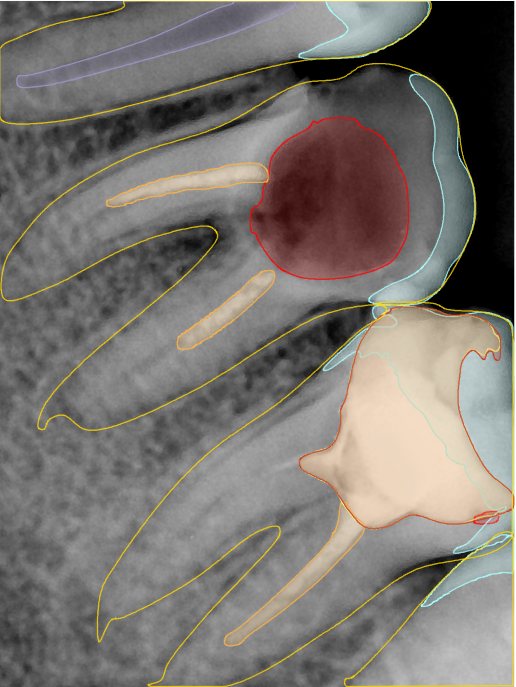 | 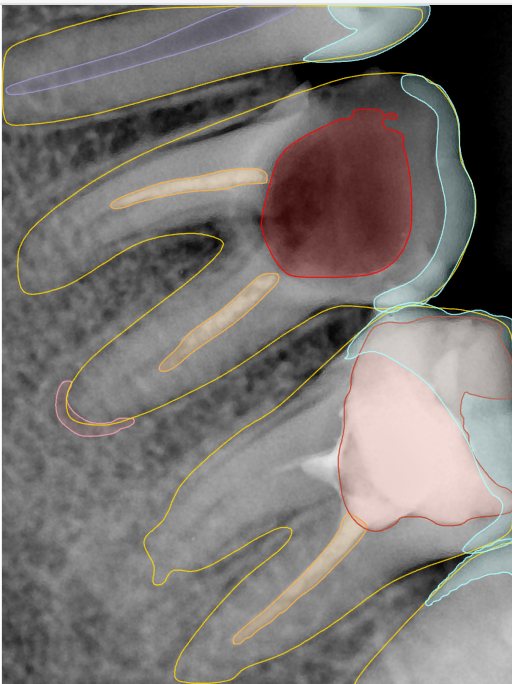 | 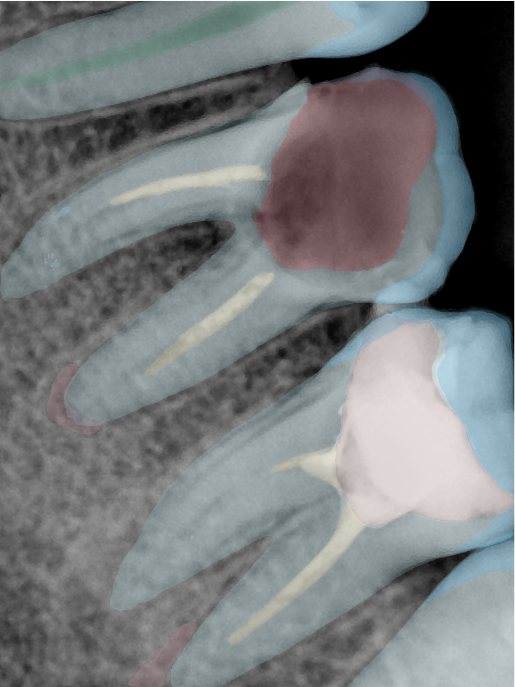 | 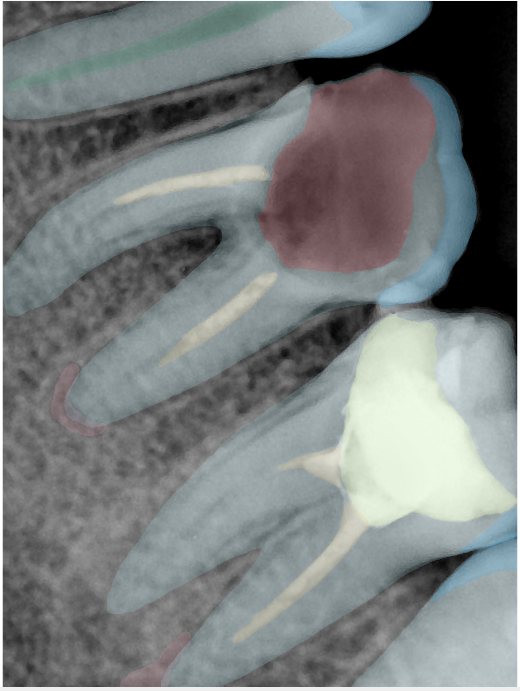 | 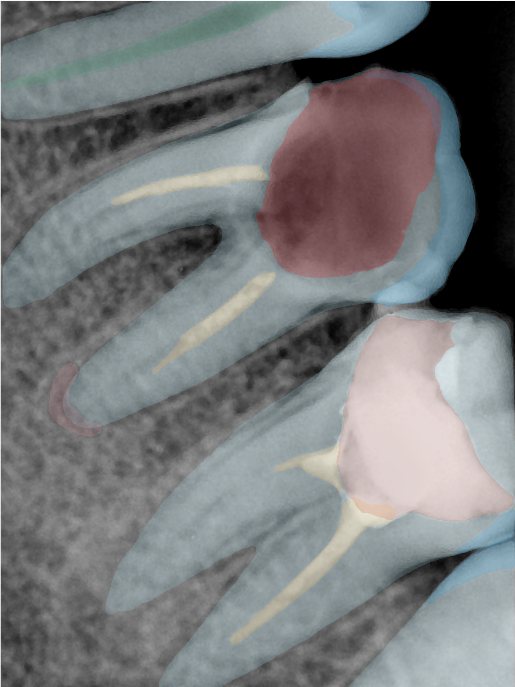 |
| 131365.jpg | 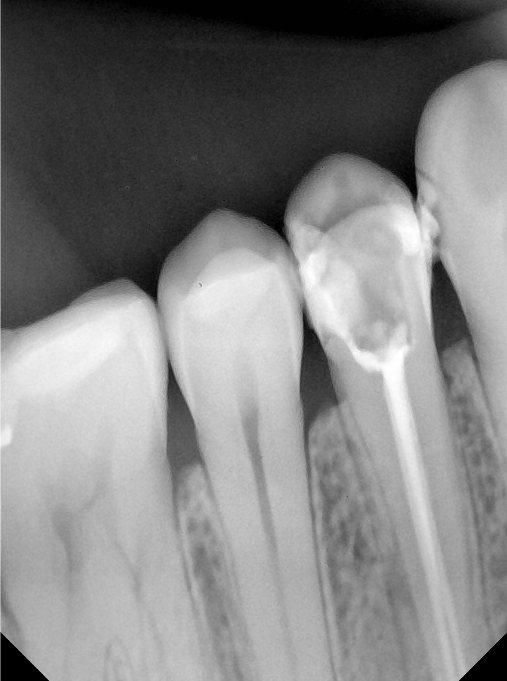 | 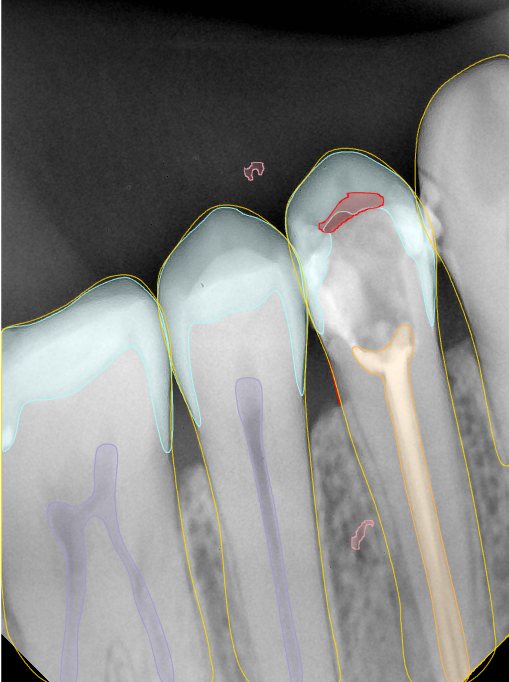 | 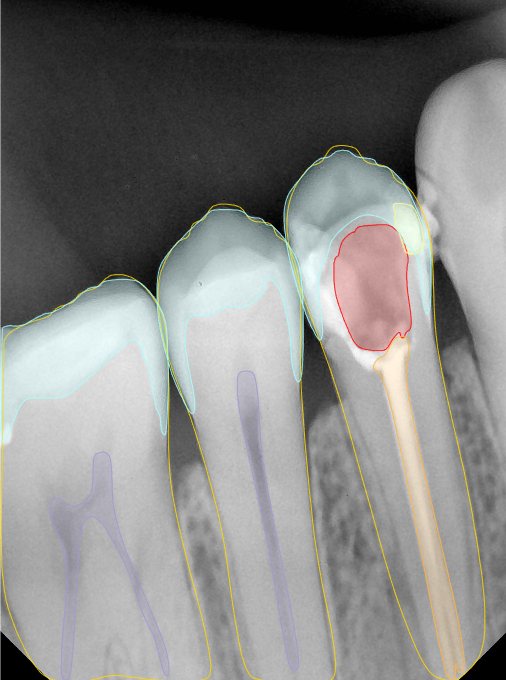 | 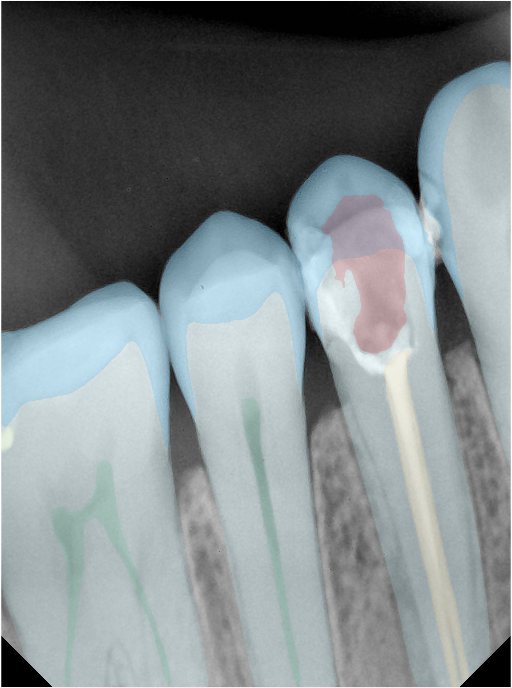 | 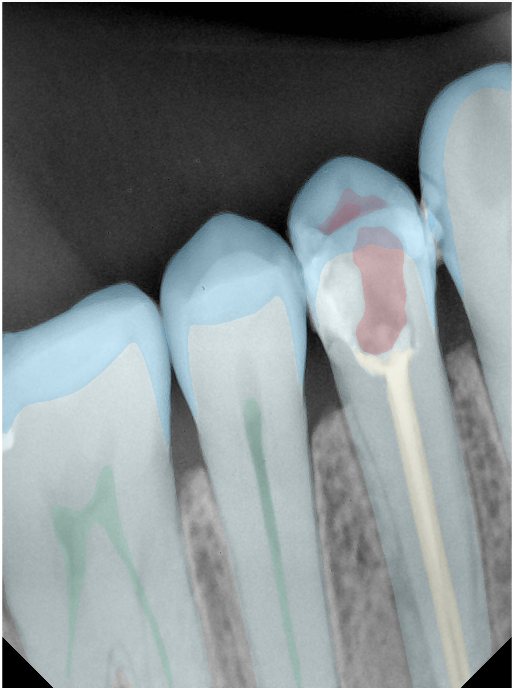 | 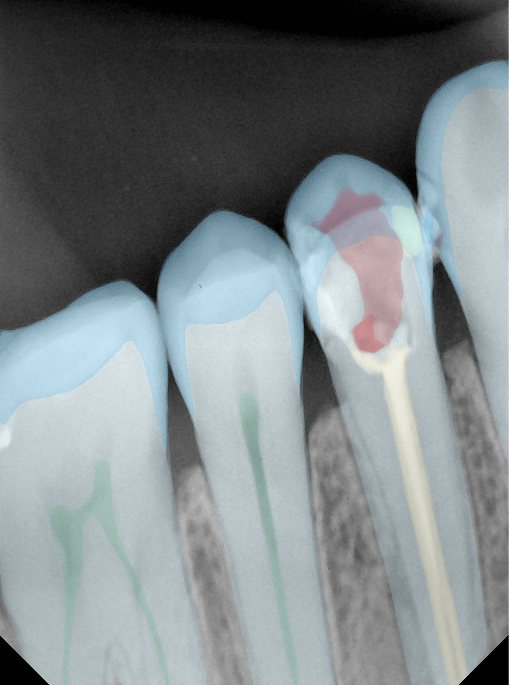 |
PPOCRv5-ncnn 移动端速度测试
记录
近期测试了 PPOCRv5-ncnn 在移动端的推理速度,当前观察到的速度大约在 11 FPS 左右。
观察
- 文本数量越多,整体速度下降越明显
- 这类内容更适合放在“技术分享”里,后面可以继续补模型版本、设备信息和更细的测试条件
DeamNet ncnn Windows
项目概览
这是一个基于 ncnn 的 DeamNet 非官方简化实现,重点是把模型推理流程整理成更适合 Windows 环境部署和实际落地的形式。
从当前仓库内容来看,这个项目已经具备比较完整的工程信息:依赖环境、调用方式、结果对照和基础性能数据都已经给出,因此这一页可以更自然地当作一个小型技术记录来读,而不是只看仓库简介。
环境与使用方式
当前依赖环境主要包括:
- Visual Studio 2019 / 2022
- NCNN 预编译版本
- OpenCV 4.6.0
编译完成后,可以直接按下面的方式执行推理:
./<xxx.exe> <image-path>
灰度图结果对比
下面这组结果展示了同一输入下,原始实现与 ncnn 推理输出之间的对照情况。
| Input | Pytorch | ncnn |
|---|---|---|
 |  |  |
 |  |  |
这部分最有价值的点在于:项目不仅实现了 ncnn 版本,还实际把输出结果和原始 Pytorch 结果做了可视化对照。
彩色图结果对比
彩色图的结果也已经给出,可以更直观看到移植后的输出情况。
| Input | Pytorch | ncnn |
|---|---|---|
 |  |  |
运行时间
项目说明里给出了一组在 AMD Ryzen 5 5600G 上、以 Gray25 为主的测试结果:
| 分辨率 | CPU | 核显 + Vulkan |
|---|---|---|
| 256x256 (Gray) | 4.63 | 1.80 |
| 512x512 (Gray) | 18.35 | 3.72 |
| 1200x1600 (Gray) | Run failed | 24.41 |
这些数据已经能说明一个很实际的问题:在当前测试条件下,Vulkan 路线比纯 CPU 更有意义,但在更大输入尺寸下仍然需要继续补稳定性和完整 benchmark。
后续值得补充的方向
- ncnn 推理工程结构
- 模型输入输出处理
- 与其他去噪模型的速度与效果对比
- 不同后端下的稳定性记录
参考
- Ren et al., Adaptive Consistency Prior Based Deep Network for Image Denoising, CVPR 2021
技术栈
- C++
- ncnn
- Denoising
链接
Raw Image Process
项目概览
这个仓库围绕 RAW 格式图像后处理展开,更像一个持续整理中的方法与实验入口,而不是已经完全封装好的独立工具项目。
目前能明确看出的方向是:围绕 RAW 图像处理流程,把后续值得长期积累的内容集中到一个仓库里,方便后面持续补实验、补说明、补结果。
可以继续展开的内容
- Bayer 到 RGB 的处理流程
- 白平衡、去噪、锐化等经典步骤
- 不同参数和不同数据上的效果对比
- 处理链路中的中间结果可视化
如果后续仓库里补上流程图、示例图和实验结果,这一页就可以进一步整理成更完整的图像处理文档。
技术栈
- Python
- Image Processing
- RAW
链接
DruNet ncnn Windows
项目概览
这是一个基于 ncnn 的 DRUNet 非官方简化实现,目标是把图像去噪模型整理成更轻量、也更适合 Windows 环境部署的形式。
从当前仓库内容来看,这个项目已经不只是“把模型跑通”,而是开始进入工程整理阶段:依赖环境、调用方式和一组基础性能数据都已经明确下来,适合作为后面继续补部署细节和 benchmark 的基础版本。
环境与使用方式
当前项目依赖环境主要包括:
- Visual Studio 2019 / 2022
- NCNN 预编译版本
- OpenCV 4.6.0
编译完成后,当前的调用方式比较直接:
./<xxx.exe> <image-path>
这也说明项目当前重点更偏向推理落地,而不是封装成复杂的上层接口。
结果与性能
项目说明里已经给出一组基础运行时间,测试平台是 AMD Ryzen 5 5600G,目前公开的数据主要集中在 Vulkan 推理:
| 分辨率 | 核显 + Vulkan |
|---|---|
| 256x256 | 2.62 |
| 1200x1600 | 19.73 |
这组结果虽然还不算完整,但已经足够作为后续继续补 CPU、独显和更多输入尺寸测试的基线。
项目说明中还提到了灰度图和彩色图的结果对照,不过当前仓库公开路径下没有对应的结果图片文件,因此这里先不放失效图片,后面如果仓库补齐资源,可以直接把对比图接进来。
后续值得补充的方向
- 模型转换和推理流程
- Windows 端部署细节
- 速度、显存和效果对比
- 与原始 Pytorch 输出的一致性说明
参考
- Zhang et al., Plug-and-Play Image Restoration with Deep Denoiser Prior, TPAMI 2021
技术栈
- C++
- ncnn
- Denoising
链接
Low Light Image Enhancement
项目概览
这个仓库更像一个低照度图像增强方法的整理入口,用来汇总已经实现过的方法、实验记录和后续可以继续扩展的工程经验。
它当前并不是围绕某一个单独算法写成的项目页,而是偏向“方法集合”式的仓库结构。这样的好处是后续可以持续往里补不同增强思路的对比、数据集表现和部署经验。
当前适合沉淀的内容
- 不同方法的主观视觉效果对比
- 常用数据集与评价指标
- 训练、推理与部署之间的差异
- 不同增强策略在亮度恢复、噪声放大和色偏上的表现
如果后面仓库补上示例图、方法分类和更系统的实验记录,这一页会更适合整理成“低照增强方法总览”。
技术栈
- Python
- Enhancement
- Vision
链接
Thoughts(技术杂谈)
这里放不需要写成长文、但值得记一笔的技术碎片。
适合放的内容包括:
- 一次短测试的结论
- 某个坑点的快速记录
- 一个暂时还不想扩写成完整文章的想法
后续可以直接继续往下追加。
Mabinogi Lounge(Mabinogi 水区)
这里专门留给 Mabinogi 相关的日常记录、截图、闲聊和活动笔记。
目前还没有单独拆出的页面,后面可以继续往这个分区里补内容。
Site Migration Log(网站迁移与更新记录)
Updated: 2026-04-12(更新日期)
本文记录个人主页从旧站点结构迁移到当前 mdBook 结构的过程,以及目前已经完成的主要调整,便于后续继续维护。
迁移背景
原仓库基于旧的 GitHub Pages / Jekyll 风格模板,内容里混有不少并不属于个人主页的模板残留。当前版本已经将站点重构为更适合长期写作和文档整理的 mdBook 结构,目标是:
- 用统一的文档站方式管理技术内容、Mabinogi 记录和 Maintenance(维护)文档
- 保留清晰的左侧章节导航和右侧页内目录
- 让个人主页更适合持续写文章,而不是一次性作品集
当前结构
当前内容主要位于 src/ 下:
about.md:关于页,同时作为站点主入口blog/:Guides(技术分享)与Thoughts(技术杂谈)notes/:Mabinogi 分区maintenance/:迁移记录与 Maintenance(维护)文档archive.md:Archive(内容归档)页面SUMMARY.md:左侧导航目录定义
主题相关定制位于 theme/:
custom.css:站点样式覆盖page-toc.js:右侧页内目录生成逻辑giscus.js:评论区注入逻辑root-redirect.js:根路径跳转逻辑sidebar-numbering.js:左侧目录编号重写逻辑
已完成的迁移工作
1. 站点框架迁移
- 从旧模板切换到
mdBook - 清理不属于个人主页的模板残留内容
- 统一为文档站结构,而不是传统博客首页加碎片化页面
2. 导航重组
- 将首页和关于页合并为
About - 左侧导航改为站点章节入口,不再混入文章内部标题
- 当前主分区整理为
Tech Notes(技术笔记) / Mabinogi / Maintenance(维护) / Archive(归档) Tech Notes(技术笔记)下包含Guides(技术分享)和Thoughts(技术杂谈)Archive(内容归档)移动到了左侧导航最下方
3. 页面布局调整
- 布局整体参考
theajack.github.io/rust的文档站形式 - 左侧保留书籍式目录导航
- 右侧目录根据当前 Markdown 标题自动生成
- 右侧目录固定在页面右侧,滚动时高亮当前标题
- 页面底部翻页箭头调整为更接近目标文档站的形式
4. 评论系统迁移
- 原仓库使用
giscus - 当前站点已经将评论区迁移到
mdBook - 评论区会在页面正文底部自动插入,无需每篇文章单独写脚本
About页面评论已映射回旧主页历史线程
更新记录
- 2026-04-12:统一导航命名为英文在前、中文补充的形式,并清理结构说明里不再使用的
projects/相关表述
本地预览与构建
构建
mdbook build
本地预览
mdbook serve 在当前 Windows 环境下有端口绑定问题时,可以使用:
mdbook build
python -m http.server 3000 --directory book
然后访问:
http://127.0.0.1:3000/
后续可继续优化的方向
- 继续打磨顶部菜单栏与正文宽度比例
- 为项目页补更统一的封面或摘要结构
- 继续清理历史内容中的乱码和旧文案
- 为常用文章模板补统一的写作骨架
备注
这份文档用于记录站点迁移和界面调整过程。后续如果还有结构性修改,建议继续直接追加到这里。
Homepage Migration to mdBook(个人主页迁移到 mdBook)
Updated: 2026-04-12(更新日期)
为什么迁移
原来的个人主页基于 Jekyll 学术模板,虽然能用,但目录结构偏重,夹杂了论文、讲座、教学等大量与当前个人站点无关的模板内容,不适合长期维护技术页面、Mabinogi 分区和 Maintenance(维护)文档。
这次做了什么
- 将站点改成真正的
mdBook结构 - 用
src/SUMMARY.md统一维护左侧目录 - 重新整理成
Tech Notes(技术笔记) / Mabinogi / Maintenance(维护) / Archive(归档)这套结构 - 将技术内容拆成
Guides(技术分享)和Thoughts(技术杂谈) - 把
Archive(内容归档)放到左侧导航最下方 - 改为通过 GitHub Pages 自动构建和发布
本次更新
- 2026-04-12:统一
Maintenance(维护)、Archive(归档)、Mabinogi Lounge(Mabinogi 水区)等命名,并同步整理结构说明
现在怎么维护
Guides(技术分享)和Thoughts(技术杂谈)写在src/blog/- Mabinogi 相关内容写在
src/notes/ - Maintenance(维护)记录写在
src/maintenance/ - Archive(内容归档)页面写在
src/archive.md
为什么 mdBook 更合适
对于长期维护的个人技术站点来说,mdBook 的目录组织、章节跳转和全文检索更接近“文档 / 手册”的体验,比临时拼起来的首页模板更稳定,也更适合后续持续扩写。
Rust 发展历程
Rust 不是凭空冒出来的一门语言。它出现的背景,和现代软件工程对安全性、性能、协作效率的持续要求直接相关。对个人开发者来说,它是一门值得投入学习成本的语言;对团队来说,它又是一种能够重新定义工程边界的工具。
为何又来一门新语言?
很多语言都在尝试解决工程问题,但往往只能覆盖其中一部分。
- 脚本语言上手快,但性能和静态约束有限。
- 系统语言性能强,但内存安全和并发安全成本高。
- 工程语言生态成熟,但底层控制能力又不够灵活。
Rust 试图把这些矛盾重新组合:既要接近底层性能,也要提供现代语言的安全约束和工具链体验。
缓解内卷
这里说的“缓解内卷”,不是说学了 Rust 就不用竞争,而是它能让竞争方式发生变化。
- 你不再只是在常规 CRUD、脚本堆叠、普通业务开发里拼熟练度。
- 你会被迫理解内存、生命周期、错误处理、并发模型和接口边界。
- 这些能力会把你从“能写代码的人”往“能设计系统的人”推。
Rust 的门槛本身就是筛选器。它不一定适合所有人,但确实能让会用它的人形成更强的技术辨识度。
效率
讨论 Rust 时,效率不能只看运行速度。更有价值的是把效率拆开来看。
学习效率
Rust 的学习效率在前期并不高。
- 需要理解所有权、借用、生命周期这些核心概念。
- 编译器报错虽然详细,但一开始会显得“严格过头”。
- 很多以前靠经验规避的问题,在 Rust 里会被明确暴露出来。
但一旦度过前期,学习收益会非常高。因为 Rust 教给你的不是某个框架 API,而是一整套更严谨的工程思维。
运行效率
Rust 的运行效率是它最容易被认可的一面。
- 没有 GC 带来的不可控停顿。
- 对内存布局和资源管理有足够强的控制能力。
- 很适合做高性能服务、系统工具、编译器、游戏基础设施和推理部署组件。
如果你的项目既要快、又要稳、又不想把大量时间花在排查野指针和悬空引用上,Rust 的价值就会很明显。
开发效率
Rust 的开发效率很有争议,因为它不是那种“开局最快”的语言。
短期看:
- 写起来更慢。
- 改一个接口,编译器会把受影响的地方全部拎出来。
- 需要更早做结构设计。
长期看:
- 重构更可控。
- 并发代码更放心。
- 边界条件更早暴露。
- 上线后因为低级错误导致的返工会减少。
所以 Rust 更像是“把问题前置”,而不是“把问题消灭”。只是问题在编译期解决,通常比在线上解决便宜得多。
个人的好处
Rust 对个人最大的价值,不只是多掌握一门语言,而是强迫你升级自己的技术判断标准。
成为更好的程序员
写 Rust 会逼你回答很多在其他语言里可以回避的问题。
- 数据到底归谁拥有?
- 这个接口会不会泄漏内部状态?
- 并发访问是否真的安全?
- 错误应该在哪里处理?
久而久之,你在写其他语言时也会更谨慎,设计会更清楚,边界会更明确。
增加不可替代性
真正稀缺的不是“会用某个框架的人”,而是能处理复杂工程问题的人。
Rust 相关岗位虽然总量未必最大,但往往更集中在高性能基础设施、区块链、数据库、AI 推理、系统工具链、安全产品这些更强调硬实力的方向。能胜任这些方向的人,替代成本通常更高。
团队的好处
团队采用 Rust,真正获得的不是“更时髦的技术栈”,而是更稳定的协作边界。
- 很多代码规范不再靠口头约定,而是靠编译器强制执行。
- 复杂模块的维护成本更可控。
- 重构时不容易因为隐式副作用而牵一发动全身。
- 在高并发或底层模块里,可以更有信心地做性能优化。
这类收益在小项目里未必立刻显现,但在长期维护的工程里会越来越明显。
开源
Rust 社区和开源生态是它快速发展的关键原因之一。
- 官方工具链整体体验统一。
- 社区对文档、示例和工程质量比较重视。
crates.io提供了相对清晰的包管理体验。- 很多项目愿意把性能敏感模块逐步改写为 Rust。
Rust 的开源生态仍在继续成长,但它最有价值的一点,是很多项目不仅“能用”,而且在工程质量上也更值得参考。
相比其他语言 Rust 的优势
Rust 的优势不是全方位碾压,而是在某些关键维度上更平衡。
Go
和 Go 相比,Rust 的抽象能力、零成本抽象、类型表达力通常更强。
- Go 更适合快速搭建服务和统一团队风格。
- Rust 更适合对性能、安全、底层控制要求更高的场景。
如果你更重视“先跑起来”,Go 更轻;如果你更重视“边界严格、性能稳定、底层可控”,Rust 更有优势。
C++
和 C++ 相比,Rust 最大的优势是现代化的安全模型和一致性更强的工具链。
- 同样能做系统级开发。
- 但 Rust 在内存安全、依赖管理、构建体验上更现代。
- 很多 C++ 项目中的经典风险点,在 Rust 中会被更早限制。
它不一定能完全替代 C++,但在新项目里,Rust 往往是更理性的默认选择。
Java
Java 在企业应用和生态成熟度上依然非常强,但 Rust 更适合需要极致资源控制和低开销运行时的地方。
- Java 更适合大型业务系统、成熟中间件和组织化开发。
- Rust 更适合底层服务、代理层、推理引擎、插件和系统组件。
两者不是正面冲突关系,而是落点不同。
Python
Python 的优势是开发速度、生态广度和 AI 领域的统治力;Rust 的优势是性能、部署稳定性和类型约束。
- Python 适合实验、脚本、数据处理和模型训练外围流程。
- Rust 适合把性能瓶颈模块、部署模块和工具链组件做得更可靠。
实际工程里,两者经常是互补关系,而不是二选一。
使用现状
Rust 现在已经不是“小众兴趣语言”了,但也还没有成为所有场景下的默认方案。
- 在系统工具、CLI、数据库、区块链、浏览器组件、安全产品中存在感越来越强。
- 在 AI 推理部署、边缘计算、高性能网关这类场景里也越来越常见。
- 大量团队采用 Rust 的方式不是全量迁移,而是先替换性能敏感或稳定性敏感模块。
这意味着它的现实路线更像“逐步渗透”,而不是“一夜之间统一天下”。
Rust 语言版本更新
Rust 语言的迭代节奏一直比较稳定。
- 版本更新频繁,但总体可预期。
- 工具链和生态协同较好。
- 新特性推进相对谨慎,不会轻易破坏已有工程。
这种稳定更新机制很适合长期维护型项目。你不需要每次升级都怀疑整套工程会不会被打碎。
总结
Rust 的意义,不只是多了一门“语法不同的语言”。它真正重要的地方在于:它试图把性能、安全、工程纪律和现代工具链放到同一个体系里。
如果你只是想最快写完一个小工具,它未必是最轻的选择。
但如果你想长期积累更扎实的工程能力,或者想进入更强调系统能力和不可替代性的方向,Rust 值得认真学。
Archive(内容归档)
统一索引当前站点里的主要内容。
Guides(技术分享):
- AI Studio
- Feature Overview(功能介绍)
- Software Architecture(软件架构)
- CR/DR 牙齿分割阶段记录
- PPOCRv5-ncnn 移动端速度测试
- DeamNet ncnn Windows
- Raw Image Process
- DruNet ncnn Windows
- Low Light Image Enhancement
Thoughts(技术杂谈):
Mabinogi:
Maintenance(维护):